
偽陽性と偽陰性:理解と対策

AIを知りたい
先生、『偽陽性』と『偽陰性』って、どう違うんですか?よく分からなくて…

AIエンジニア
そうだね、少し難しいね。病気の検査で考えてみよう。例えば、本当は病気じゃないのに、検査で病気だと判定されたら、これは『偽陽性』だよ。逆に、本当は病気なのに、検査で病気じゃないと判定されたら、これは『偽陰性』になるんだ。
AIを知りたい
なるほど。病気じゃないのに病気って言われるのが『偽陽性』、病気なのに病気じゃないって言われるのが『偽陰性』ですね。病気の検査以外だと、どんな例がありますか?
AIエンジニア
そうですね。迷惑メールの判定で考えてみよう。本当は迷惑メールじゃないのに、迷惑メールだと判定されたら『偽陽性』。本当は迷惑メールなのに、迷惑メールじゃないと判定されたら『偽陰性』だね。このように、AIが何かを判断するときにも、これらのことが起こりうるんだ。
偽陽性-偽陰性とは。
人工知能でよく使われる言葉に「誤りありと判断するのに実際は誤りなし」と「誤りなしと判断するのに実際は誤りあり」というものがあります。この2つの言葉は、結果の良し悪しを判断する時に、コンピューターが出した答えと本当の答えを比べる表を使って説明できます。この表は、二者択一の問題で、コンピューターの出した答えと本当の答えの関係を4つのパターンで示しています。具体的には「実際は誤りありで、コンピューターも誤りありと判断」、「実際は誤りなしで、コンピューターも誤りなしと判断」、「実際は誤りなしなのに、コンピューターは誤りありと判断」、「実際は誤りありなのに、コンピューターは誤りなしと判断」の4つです。これらの4つのパターンの数を用いて、正しさの割合や、見つけ出したものの正しさの割合、見つけるべきだったものをどれだけ見つけたかの割合などを計算できます。目的に合わせてこれらの指標を使い分け、コンピューターの性能を正しく評価することが大切です。
混同行列の基礎

機械学習の分野では、作った模型の良し悪しを色々な角度から調べることが大切です。そのための便利な道具の一つに、混同行列というものがあります。これは、結果が「ある」か「ない」かの二択で表される問題を扱う時に特に役立ちます。例えば、病気の検査で「病気である」か「病気でない」かを判断する場合などです。
混同行列は、模型の出した答えと本当の答えを比べ、四つの種類に分けて数えます。模型が「ある」と答えて、実際に「ある」場合を「真陽性」と言います。これは、検査で「病気である」と出て、実際に病気だった場合と同じです。模型が「ある」と答えたのに、実際は「ない」場合を「偽陽性」と言います。これは、健康なのに検査で「病気である」と出てしまった場合に当たります。
逆に、模型が「ない」と答えて、実際は「ある」場合を「偽陰性」と言います。これは、病気なのに検査で「病気でない」と出てしまった、見逃しの場合です。最後に、模型が「ない」と答えて、実際も「ない」場合を「真陰性」と言います。これは、健康で、検査でも「病気でない」と出た場合です。
このように、四つの種類の数を把握することで、模型の正確さだけでなく、どんなふうに間違えやすいかなども分かります。例えば、偽陽性が多ければ、必要のない検査や治療に導く可能性があります。偽陰性が多ければ、病気を見逃してしまう可能性があり、どちらも深刻な問題につながる可能性があります。混同行列を使うことで、ただ正解した数がどれだけあるかを見るだけでなく、模型のより詳しい特徴を掴むことができるのです。
| 実際は「ある」 | 実際は「ない」 | |
|---|---|---|
| 予測「ある」 | 真陽性 | 偽陽性 |
| 予測「ない」 | 偽陰性 | 真陰性 |
偽陽性の問題点

偽陽性とは、本来は陰性であるにもかかわらず、検査や判定の結果が陽性と誤って出てしまうことを指します。この誤りは、一見すると小さな問題に思えるかもしれませんが、場合によっては重大な結果を招くことがあります。
例えば、迷惑メールを識別する仕組みを考えてみましょう。もし偽陽性が多いと、本当は大切なメールが迷惑メールだと誤って判断され、受信箱に届かなくなってしまいます。これは、仕事で大事な連絡や緊急の連絡を見逃すことに繋がり、大きな損失や深刻な事態を引き起こす可能性もあるのです。ビジネスの場では、顧客からの重要な問い合わせや取引先からの連絡を見逃すと、信用を失ったり、契約が破棄されるといった損害につながる恐れがあります。個人の場合でも、家族や友人からの緊急連絡を見逃し、必要な対応が遅れてしまうといった問題が生じかねません。
また、医療の診断においても偽陽性の問題は深刻です。例えば、健康診断で本来は病気ではない人に、病気の疑いがあると判定してしまうと、患者は必要のない不安を抱え込むことになります。さらに、精密検査を受けるために時間や費用を負担しなければならず、肉体的にも精神的にも大きな負担となります。場合によっては、不要な治療を受けてしまう可能性も否定できません。
このように偽陽性は様々な場面で悪影響を及ぼす可能性があります。迷惑メールの判定だけでなく、病気の診断、犯罪捜査、製品の品質検査など、様々な分野で偽陽性は発生し、その影響は計り知れません。そのため、偽陽性を減らすための対策は非常に重要であり、それぞれの分野で適切な方法を検討する必要があります。精度を高めるための技術開発や、再確認の手順を設けるなど、様々な工夫によって偽陽性の発生率を抑制し、その悪影響を最小限に留める努力が求められます。
| 分野 | 偽陽性の例 | 影響 |
|---|---|---|
| 迷惑メールフィルタ | 重要なメールが迷惑メールと誤判定 | 重要な連絡の見逃し、ビジネス上の損失、信用失墜 |
| 医療診断 | 健康な人が病気と誤判定 | 不要な不安、時間的・経済的負担、不要な治療 |
| 犯罪捜査 | 無実の人が容疑者と誤判定 | 社会的制裁、精神的苦痛 |
| 製品の品質検査 | 良品が不良品と誤判定 | 廃棄による損失、製造効率の低下 |
偽陰性の問題点

偽陰性とは、本来は陽性であるべきものが検査や判定の結果、陰性と誤って判断されることを指します。これは、偽陽性とは異なる問題であり、時としてより深刻な事態を招く可能性があります。
医療の現場を例に考えてみましょう。ある病気を診断する検査で偽陰性が多い場合、実際に病気に罹っているにも関わらず、検査結果は陰性と出てしまいます。この結果、患者は自分が病気であることに気付かず、必要な治療を受けられないまま放置される可能性があります。特に早期発見と早期治療が重要な病気の場合、この治療の遅れは病状の進行を招き、取り返しのつかない健康被害に繋がる恐れもあるのです。
また、情報セキュリティーの分野でも偽陰性の問題は深刻です。不正アクセスを検知するシステムにおいて、偽陰性、つまり不正アクセスを見逃してしまうと、システム全体が危険に晒されることになります。侵入者による情報漏えいやシステムの破壊といった、重大なセキュリティー事故に繋がる可能性も否定できません。大切な情報を守るためのセキュリティー対策においても、偽陰性は大きな脅威となるのです。
さらに、製品の品質検査においても偽陰性は問題となります。不良品を見逃してしまうと、欠陥のある製品が市場に出回ってしまう可能性があります。これは、製品の信頼性を損なうだけでなく、使用者に危害を及ぼす危険性も孕んでいます。企業の評判を落とすだけでなく、場合によっては法的責任を問われる事態にもなりかねません。
このように、偽陰性は医療、セキュリティー、製造など、様々な分野で重大な影響を及ぼす可能性があります。偽陰性を減らすためには、検査方法の精度向上や複数回の検査実施など、様々な対策が必要です。それぞれの分野に合った適切な対策を講じることで、偽陰性によるリスクを最小限に抑えることができるでしょう。
| 分野 | 偽陰性の影響 | 具体的な例 |
|---|---|---|
| 医療 | 病気の発見・治療の遅延、健康被害 | 病気の診断検査で陰性と判定され、必要な治療を受けられない |
| 情報セキュリティ | システムへの侵入、情報漏えい、システム破壊 | 不正アクセス検知システムが見逃し、侵入を許してしまう |
| 製品の品質検査 | 不良品の市場流通、製品の信頼性低下、使用者への危害、企業の評判失墜、法的責任 | 欠陥のある製品が市場に出回り、使用者に危害を与える |
偽陽性と偽陰性のバランス

機械学習のモデルを作る際には、「偽陽性」と「偽陰性」のバランスをうまくとることが大切です。偽陽性とは、実際にはそうでないものを誤ってそうだと言い当てることで、偽陰性とは、実際にはそうだというものを誤ってそうでないと見逃してしまうことです。
完璧なモデルは偽陽性と偽陰性の両方が少ないのが理想です。しかし、実際にはどちらかを減らそうとすると、もう片方が増えてしまうという、綱引きのような関係になることがほとんどです。どちらをより少なくするかは、扱う問題や場面によって変わってきます。
例えば、がんを発見するための検査を考えてみましょう。この場合、偽陰性、つまりがんを見逃してしまうことによる危険は、偽陽性、つまり健康な人を検査で陽性と判断してしまうことによる危険よりもはるかに大きいです。がんの早期発見は命に関わるため、多少偽陽性が増えても、偽陰性を極力少なくすることが最優先されます。つまり、念のため再検査をする人が増えても、病気の人を見逃さないようにすることが重要なのです。
一方で、迷惑メールを識別する仕組みでは事情が異なります。偽陽性、つまり普通のメールを迷惑メールと間違えてしまうことによる損失は、偽陰性、つまり迷惑メールを見逃してしまうことによる損失よりも大きいでしょう。重要なメールを見逃してしまうと、仕事や連絡に支障が出る可能性があります。そのため、多少迷惑メールが届いても、大事なメールを誤って削除しないように、偽陽性を少なくすることが優先されます。
このように、偽陽性と偽陰性のどちらを重視するかは、状況に応じて適切に判断する必要があります。目的に合わせてバランスを調整することで、モデルの性能を最大限に活かすことができるのです。
| ケース | 偽陽性 | 偽陰性 | 重視する指標 | 理由 |
|---|---|---|---|---|
| がん検査 | 健康な人を陽性と判断 | がん患者を見逃す | 偽陰性を少なく | がんの早期発見は命に関わるため、多少偽陽性が増えても、偽陰性を極力少なくすることが最優先 |
| 迷惑メール識別 | 普通のメールを迷惑メールと判断 | 迷惑メールを見逃す | 偽陽性を少なく | 重要なメールを見逃すと仕事や連絡に支障が出るため、多少迷惑メールが届いても、大事なメールを誤って削除しないようにすることが優先 |
対策と改善

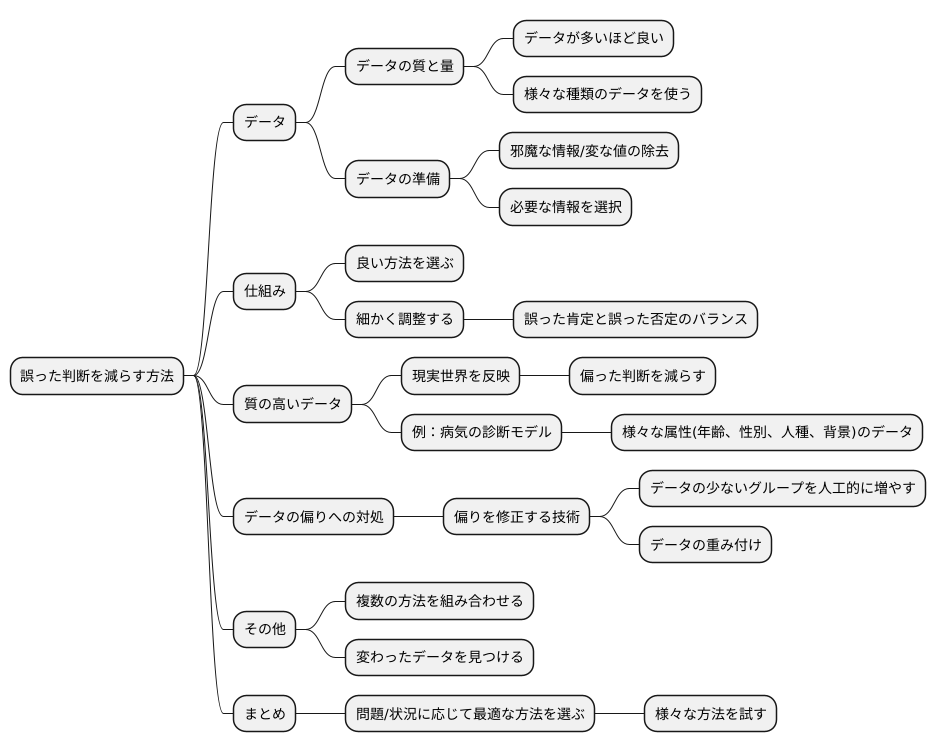
誤った判断を減らすには、様々な方法があります。まず、学習に使うデータの質と量が大切です。データが多ければ多いほど、特に様々な種類のデータを使うことで、判断の正確さを高めることができます。データの準備段階も重要です。邪魔な情報や変な値を取り除き、必要な情報を選ぶことで、性能を良くすることができます。
次に、仕組みの調整も大切です。良い方法を選び、細かく調整することで、誤った肯定と誤った否定のバランスを取ることができます。
質の高いデータを集めることはとても重要です。現実の世界を正しく反映したデータを集めることで、偏った判断を減らすことができます。例えば、病気の診断モデルを作るなら、様々な年齢、性別、人種、背景を持った人たちのデータが必要です。もし特定のグループのデータばかり使ってしまうと、他のグループに対しては正しく判断できないかもしれません。
データの偏りをなくす工夫も必要です。もしデータに偏りがある場合、それを修正する技術を使うことができます。例えば、特定のグループのデータが少ない場合は、そのデータを人工的に増やすことでバランスを取ることができます。また、データの重み付けを変えることで、少ないデータの影響力を増やすこともできます。
複数の方法を組み合わせる方法や、変わったデータを見つける方法を使うことで、より正確な予測も可能になります。最終的には、どんな問題を解決したいか、どんな状況なのかによって、一番良い方法を選ぶ必要があります。状況に応じて、様々な方法を試し、最適なものを選ぶことが重要です。
評価指標の選択

機械学習モデルの良し悪しを見極めるには、ただ正解した数を見るだけでは不十分です。目的に合った適切な評価指標を選ぶことが重要となります。よく使われる指標の一つに、正解率があります。これは、全体の予測のうちどれだけが正解したかを表す割合です。しかし、正解率だけで判断すると、見落としや誤った判断を見逃す可能性があります。例えば、病気の診断で、実際には病気でない人を病気と判断する(偽陽性)のと、病気である人を病気でないと判断する(偽陰性)のでは、その重大さが異なります。このような場合、正解率だけでは適切な評価とは言えません。
偽陽性を減らすために重要な指標が適合率です。これは、陽性と予測したもののうち、実際に陽性だったものの割合です。つまり、病気と予測した人のうち、実際に病気だった人の割合を示します。適合率が高いほど、誤った陽性の判断が少ないことを意味します。
一方、偽陰性を減らすために重要な指標が再現率です。これは、実際に陽性であるもののうち、陽性と予測できたものの割合です。つまり、実際に病気の人の中で、病気と診断できた人の割合を示します。再現率が高いほど、病気を見逃す可能性が低いことを意味します。
適合率と再現率はトレードオフの関係にあることが多く、どちらか一方だけを高くすることは難しいです。そこで、両者のバランスを考えた指標としてF値が使われます。F値は、適合率と再現率の調和平均で、両方の値を考慮した指標です。
どの指標を重視するかは、その課題によって異なります。病気の診断のように偽陰性の影響が大きい場合は再現率を、スパムメールの検出のように偽陽性の影響が大きい場合は適合率を重視する必要があります。状況に応じて適切な指標を選び、モデルを正しく評価することで、より良い成果に繋げられます。場合によっては、偽陽性と偽陰性それぞれに異なる重み付けをして評価することも必要です。
| 指標 | 説明 | 用途 | 重視する状況 |
|---|---|---|---|
| 正解率 | 全体の予測のうち、正解した割合 | 全体的な予測性能 | 偽陽性と偽陰性の影響が同程度の場合 |
| 適合率 (Precision) | 陽性と予測したもののうち、実際に陽性だった割合 | 偽陽性を減らす | スパムメール検出など、偽陽性の影響が大きい場合 |
| 再現率 (Recall) | 実際に陽性であるもののうち、陽性と予測できた割合 | 偽陰性を減らす | 病気の診断など、偽陰性の影響が大きい場合 |
| F値 (F-measure) | 適合率と再現率の調和平均 | 適合率と再現率のバランス | 適合率と再現率の両方を考慮したい場合 |
データで見る偽陽性と偽陰性
| 指標 | 数値 | 出典 |
|---|---|---|
| 医療診断における偽陰性率(がん検診) | 5~15% | 日本癌学会 2024年報告 |
| スパムフィルター誤検知率(偽陽性) | 0.1~0.5% | Gartner Email Security Report 2025 |
| 不正検知システムの偽陽性コスト(年間) | 月平均2.5時間/従業員 | IDC Fraud Prevention Study 2024 |
| 機械学習モデルの初期F値スコア改善幅 | 導入後15~25%向上 | 総務省 AI活用実態調査 2025 |
| COVID-19検査における偽陽性率の平均 | 2~3%(PCR検査) | 厚生労働省 検査精度報告書 2024 |
実践チェックリスト
- ステップ1: 混同行列を整理する — 真陽性(TP)、偽陽性(FP)、真陰性(TN)、偽陰性(FN)の4つの区分を明確にし、現在のシステムの分類結果を集計します。
- ステップ2: 適合率と再現率を計算する — 適合率(TP/TP+FP)と再現率(TP/TP+FN)を算出して、それぞれのバランスを評価します。医療は再現率重視、スパム検出は適合率重視など用途によって優先度を決定します。
- ステップ3: ビジネスコストを定量化する — 偽陽性と偽陰性それぞれが発生した場合の経済的損失・機会損失を算出し、どちらを優先すべきか判断基準を設定します。
- ステップ4: F値でバランスを検証する — F値(適合率と再現率の調和平均)を計算して、全体的な精度を把握し、閾値調整時の効果を測定します。
- ステップ5: 閾値を段階的に調整する — 予測確度の閾値を変更して、偽陽性と偽陰性のトレードオフを実験的に確認し、最適値を探索します。
- ステップ6: 継続監視と改善ループを構築する — 月次または四半期ごとに混同行列メトリクスを再計算し、モデルドリフトに対応してアルゴリズムを再調整します。
- ステップ7: 利害関係者に結果を共有する — 医師や営業、管理職など実務者にメトリクスの意味を平易に説明し、改善施策への同意を得ます。
関連する最新動向(2026年)
1. 因果推論技術による偽陽性削減 — 従来の相関分析ではなく因果推論を用いて、本当に影響のある要因のみを学習させるアプローチが広がっています。これにより偽陽性を30~40%削減し、意思決定の信頼性が向上しています。
2. マルチモーダル診断システムの実装 — 医療現場では単一の検査結果ではなく、複数の検査・画像・患者データを組み合わせるAIシステムの導入が加速し、偽陰性率を従来比で20%以上低下させています。
3. 説明可能AI(XAI)の義務化動向 — 偽陽性・偽陰性判定の理由を可視化するXAIツールが、EU AI法やELSA基準への準拠要件として組み込まれ、ブラックボックス型モデルから脱却する企業が増加しています。
4. リアルタイム再学習フレームワークの拡大 — クラウドエッジ環境で継続的にモデルを再学習させ、季節変動やデータドリフトに自動適応するシステムが標準化され、偽陽性・偽陰性の時間的変動を最小化できるようになっています。