
UCB方策:未知への挑戦

AIを知りたい
先生、『UCB方策』って、聞いたことがないのですが、どんなものですか?

AIエンジニア
UCB方策は、強化学習で使う考え方だよ。宝箱がたくさんあって、それぞれにどれくらい金貨が入っているかわからない状況を想像してみて。UCB方策は、なるべく多くの金貨を手に入れるために、開けた回数の少ない宝箱を優先的に開けていく方法なんだ。
AIを知りたい
なるほど。でも、もしかしたら、あまり開けられていない宝箱には金貨が少ししか入っていないかもしれませんよね?
AIエンジニア
その通り。でも、少ない回数しか開けていない宝箱には、実はたくさんの金貨が入っている可能性もある。UCB方策は、その可能性を探るために、開けた回数の少ない宝箱を積極的に開けて、情報を得ようとするんだ。そして、その情報をもとに、金貨がたくさんありそうな宝箱を絞り込んでいくんだよ。
UCB方策とは。
人工知能の分野でよく使われる『ユーシービーほうさく』について説明します。これは、機械学習の一種である強化学習で使われる考え方です。強化学習では、一番良い結果になる行動を選ぶ必要があります。そのためには、それぞれの行動がどんな結果になるかを知っておく必要があります。『ユーシービーほうさく』は、まだ試した回数が少ない行動を優先的に試すことで、それぞれの行動についての情報を集める方法です。
はじめに

強化学習とは、機械が試行錯誤を通して学習する仕組みのことです。まるで人間が新しい技術を習得する過程とよく似ています。最初はうまくいかないことも、繰り返し練習することで徐々に上達していくように、機械も経験を通して最適な行動を学習していきます。この学習の主役となるのが「エージェント」と呼ばれる学習者です。エージェントは、周囲の環境とやり取りしながら、どのような行動をとれば最も良い結果が得られるのかを模索します。
良い結果とは、より多くの「報酬」を得ることを意味します。例えば、ロボットが迷路を脱出する課題を学習する場合、「迷路から脱出する」という行動に高い報酬が設定されます。逆に、壁にぶつかったり、遠回りしたりする行動には低い報酬、あるいは罰則が与えられます。エージェントは、試行錯誤を通じて、報酬を最大化する行動を見つけ出すのです。
しかし、学習の初期段階では、どの行動が良いのか、どの行動が悪いのか全く分かりません。そのため、エージェントは様々な行動を試してみる必要があります。闇雲に行動するのではなく、効率的に情報を集めることが重要です。限られた試行回数の中で、できるだけ早く最適な行動を見つけ出す必要があるからです。UCB方策は、まさにこの情報収集を効率的に行うための優れた戦略です。UCB方策は、過去の試行結果に基づいて、次にどの行動を試すべきかを決定します。行動の良さだけでなく、その行動に関する情報の確かさも考慮することで、未知の行動の探索と既知の行動の活用をバランスよく行うことが可能になります。
行動の価値を探る

私たちは日々、様々な行動をとって生活しています。朝ごはんに何を食べるか、どの道を通って会社に行くか、仕事でどんな順番で作業を進めるかなど、実に多くの選択に迫られています。こうした行動の一つ一つには、それぞれ価値があります。例えば、朝ごはんに栄養価の高いものを食べれば、午前中の仕事がはかどるかもしれません。近道を通って会社に行けば、時間を節約できるでしょう。効率的な順番で作業を進めれば、早く仕事を終えることができます。
では、どのようにして行動の価値を見極めればいいのでしょうか?もし、すべての行動の価値があらかじめ分かっていれば、常に最も価値の高い行動をとればいいでしょう。しかし、現実には、行動の価値は未知である場合がほとんどです。そこで重要になるのが、「活用」と「探求」のバランスです。
「活用」とは、これまでにもっとも良い結果をもたらしたと分かっている行動をとることです。例えば、いつも同じ道を通って会社に行き、特に問題がなければ、その道を通ることは「活用」にあたります。「活用」は、短期的には良い結果をもたらす可能性が高いですが、本当に最適な行動を見逃してしまう可能性もあります。もしかしたら、別の道の方がもっと早く会社に着けるかもしれません。
一方、「探求」とは、未知の行動を試してみることです。例えば、いつもと違う道を通って会社に行ってみることは「探求」にあたります。「探求」は、短期的にはあまり良い結果につながらないかもしれません。しかし、長期的に見ると、より良い行動を発見できる可能性を秘めています。もしかしたら、思わぬ近道が見つかるかもしれません。
UCB方策は、「活用」と「探求」のバランスをうまくとるための方法の一つです。UCB方策では、それぞれの行動に「期待値」と「不確かさ」という二つの指標を与え、それらを組み合わせて行動を選択します。「期待値」が高い行動は「活用」を、「不確かさ」が高い行動は「探求」を重視します。UCB方策を用いることで、既知の良さそうな行動に固執することなく、未知の可能性を探求しつつ、最適な行動を見つけることができます。
| 概念 | 説明 | 例 | 短期的効果 | 長期的効果 |
|---|---|---|---|---|
| 活用 | 過去に良い結果をもたらした行動をとる | いつもと同じ道を通って会社に行く | 良い結果の可能性が高い | 最適な行動を見逃す可能性 |
| 探求 | 未知の行動を試してみる | いつもと違う道を通って会社に行く | 良い結果につながらない可能性 | より良い行動を発見できる可能性 |
| UCB方策 | 活用と探求のバランスをとる方法 | 期待値と不確かさを組み合わせて行動を選択 | – | 最適な行動を見つける可能性が高い |
UCB方策の仕組み

UCB方策(上限信頼限界方策)は、探索と利用のバランスをうまく調整する強化学習の手法の一つです。様々な選択肢の中から、最良の選択肢を見つけ出すことを目的としています。
この方策は、各選択肢に二つの重要な要素を割り当てます。一つは期待値です。これは、過去の経験に基づいて、その選択肢がどれだけの報酬をもたらすと予想されるかを示す数値です。例えば、ある自動販売機でどの飲み物を買うか迷っている場合、過去に美味しかった飲み物には高い期待値が割り当てられます。もう一つは不確実性です。これは、その期待値がどれほど信頼できるかを示す数値です。まだ試した回数が少ない選択肢は、期待値の信頼性が低いため、不確実性が高くなります。新しい飲み物が追加されたばかりで、まだ誰も買っていない場合は、その飲み物の期待値は不確実性が高くなります。
UCB方策は、これらの期待値と不確実性を組み合わせて、各選択肢の価値を計算します。期待値が高い選択肢ほど価値が高くなります。これは、過去の経験から高い報酬が期待できる選択肢を優先することを意味します。同時に、不確実性が高い選択肢も価値が高くなります。これは、まだ試した回数が少なく、真の価値が不明な選択肢を試すことを促進します。もしかしたら、期待値は低くても、実際には非常に良い選択肢かもしれません。
具体的には、UCB方策は各選択肢の価値を計算する際に、期待値に不確実性のボーナスを加算します。このボーナスは、試行回数が少ない選択肢ほど大きくなります。その結果、最初は様々な選択肢が選ばれ、徐々に良い選択肢に絞られていくという探索と利用のバランスが実現されます。このように、UCB方策は、過去の経験を活かしつつ、新たな可能性も探求することで、最良の選択肢を見つける効率的な手法と言えます。
| 要素 | 説明 | 例(自動販売機) |
|---|---|---|
| 期待値 | 過去の経験に基づいて、選択肢がもたらすと予想される報酬の大きさ | 過去に美味しかった飲み物には高い期待値 |
| 不確実性 | 期待値の信頼度。試行回数が少ないほど高くなる | 新しい飲み物でまだ誰も買っていない場合は不確実性が高い |
| UCB方策の価値計算 | 期待値 + 不確実性ボーナス | 不確実性が高い選択肢は価値も高く、試される機会が増える |
| 探索と利用のバランス | 最初は様々な選択肢を試す(探索)。徐々に良い選択肢に絞られる(利用) | 試行回数が増えるにつれて、不確実性が減り、期待値に基づいて選択されるようになる |
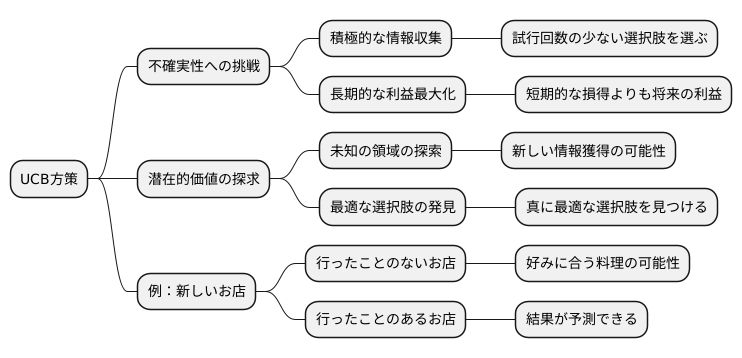
不確実性の役割

私たちは日々様々な選択に迫られますが、多くの場合、それぞれの選択肢がもたらす結果を完全に予測することはできません。このような予測の難しさを「不確実性」と呼びます。UCB方策はこの不確実性とどう向き合うかを教えてくれる、意思決定のための有効な手段です。
UCB方策の最大の特徴は、まさにこの不確実性を積極的に考慮に入れる点にあります。ある選択肢について情報が少ない、つまり不確実性が高い場合、UCB方策は他の選択肢よりも積極的にその選択肢を選びます。まるで未知の領域を探検するかのようです。なぜこのような一見すると非効率な行動をとるのでしょうか。それは、不確実性の高い選択肢には、実は大きな潜在的価値が隠されている可能性があるからです。
たとえば、新しいお店を開拓する場合を考えてみましょう。すでに何度も行ったことのあるお店と、まだ一度も行ったことのないお店、どちらを選ぶでしょうか。UCB方策は、後者、つまり行ったことのないお店を勧めます。なぜなら、行ったことのないお店には、好みに合う絶品料理に出会える可能性が秘められているからです。もちろん、まずい料理に当たる可能性もありますが、UCB方策は、短期間の損得よりも、長期間での利益最大化を目指します。
試行回数の少ない選択肢は、情報が少ないため不確実性が高くなります。UCB方策は、このような試行回数の少ない選択肢を優先的に選ぶことで、新たな情報を獲得し、真に最適な選択肢を見つけることを目指します。一見すると非効率的に見える選択も、将来的に大きな利益をもたらす可能性を秘めているのです。このように、UCB方策は、不確実性という誰もが抱える課題に対し、積極的に挑戦することで最良の結果を導き出す、画期的な方法と言えるでしょう。
応用例

上限信頼区間(UCB)方策は、様々な分野で応用されており、不確かな状況で最も良い選択をするための有力な方法です。その具体的な使い方を見てみましょう。
まず、インターネット広告の配信を例に挙げます。どの広告を見せるかは、クリックされるかどうかが不確実な中で決める必要があります。このとき、UCB方策を使って、過去の実績が良い広告だけでなく、まだ表示回数の少ない広告にも機会を与えることで、よりクリック率の高い広告を見つけ出すことができます。過去のデータからクリック率の予測値と、その予測の不確かさを表す上限信頼区間を計算し、その上限信頼区間が最も高い広告が選ばれ表示されます。表示されることで新たなデータが得られ、より精度の高い予測が可能になります。
次に、医療の分野での例を見てみましょう。最適な治療法は患者ごとに異なり、どの治療法が最も効果的かは、実際に試してみないと分かりません。UCB方策を用いることで、過去の治療データに基づいて、それぞれの治療法の効果と不確かさを評価し、最も有望な治療法を選択することができます。新しい治療法の効果が不確かな場合でも、上限信頼区間を用いることで、試してみる価値のある治療法を見逃すことなく、患者の状態を改善する可能性を高めることができます。
最後に、ゲームの場面を考えてみます。ゲームでは、様々な戦略の中から、どの戦略が最も勝利に繋がるか、あらかじめ知ることは困難です。UCB方策を用いることで、様々な戦略を試しながら、どの戦略が最も有効かを学習し、ゲームの攻略や新しい戦略の発見に役立てることができます。まだ試していない戦略も、上限信頼区間が高い場合には選択されるため、未知の有効な戦略を発見する可能性が高まります。
このように、様々な場面で活用できるUCB方策は、限られた情報から最良の選択をするための、まさに万能と言える方法です。
| 分野 | UCB方策の活用例 | UCB方策によるメリット |
|---|---|---|
| インターネット広告 | クリック率の予測値と不確かさから、上限信頼区間が最も高い広告を表示 | クリック率の高い広告を見つけ出す |
| 医療 | 治療効果の予測値と不確かさから、上限信頼区間が最も高い治療法を選択 | 患者の状態を改善する可能性を高める |
| ゲーム | 様々な戦略を試しながら、上限信頼区間が最も高い戦略を選択 | ゲームの攻略や新しい戦略の発見 |
まとめ

学習を自動で行う方法の一つとして、強化学習というものがあります。この学習方法では、試行錯誤を通じて、良い結果につながる行動を見つけ出すことが目標です。しかし、既知で良い結果が出る行動ばかり選んでいては、より良い、未知の行動を見つけることができません。一方、未知の行動ばかり試していては、良い結果を得る効率が悪くなります。このように、既知の良い行動を選ぶことと、未知の行動を試すことのバランスをうまくとることが難しく、これを「探索と活用のジレンマ」と呼びます。
このジレンマを解決する巧みな方法の一つが、UCB方策と呼ばれる手法です。UCB方策は、「期待値」と「不確実性」という二つの要素を組み合わせて、どの行動を選ぶかを決定します。期待値とは、その行動を選んだ場合に、どれくらい良い結果が得られるかという予測値です。一方、不確実性とは、その予測値がどれくらい信頼できるかを表す尺度です。
UCB方策は、期待値が高い行動だけでなく、不確実性が高い行動も積極的に選択します。なぜなら、不確実性が高いということは、その行動についてまだ十分な情報が得られておらず、実際には期待値よりもはるかに良い結果が得られる可能性を秘めているからです。言ってみれば、UCB方策は、有望そうな宝箱だけでなく、まだ開けていない宝箱にも積極的に手を出す戦略と言えるでしょう。
このバランスの取れた探索と活用によって、UCB方策は限られた試行回数の中で、より効率的に最適な行動を見つけ出すことができます。その汎用性の高さから、様々な分野で応用されています。例えば、広告配信においてどの広告を表示するか、商品の推奨においてどの商品を推薦するかなど、様々な場面で活用されています。UCB方策は、まさに限られた情報から最良の選択を行うための、賢い戦略と言えるでしょう。私たち人間も、未知の可能性を探求し、最適な行動を学習していきます。UCB方策は、機械がどのように学習し、進化していくかを理解する上でも重要な考え方です。
| 項目 | 説明 |
|---|---|
| 強化学習 | 試行錯誤を通じて、良い結果につながる行動を見つけ出す学習方法。 |
| 探索と活用のジレンマ | 既知の良い行動を選ぶことと、未知の行動を試すことのバランスの難しさ。 |
| UCB方策 | 「期待値」と「不確実性」を組み合わせて行動を選択する手法。 |
| 期待値 | 行動を選んだ場合に得られる結果の予測値。 |
| 不確実性 | 期待値の信頼度を表す尺度。 |
| UCB方策の戦略 | 期待値が高い行動だけでなく、不確実性が高い行動も積極的に選択する。 |
| UCB方策の利点 | 限られた試行回数で効率的に最適な行動を見つけ出す。 |
| UCB方策の応用例 | 広告配信、商品推奨など。 |