機械学習の落とし穴:バイアスとその影響

AIを知りたい
「ゴミを入れれば、ゴミが出てくる」っていうのは、機械学習バイアスにも関係あるんですか?よくわかりません。

AIエンジニア
そうだね。まさにその通り!機械学習バイアスは、AIが偏った情報で学習すると、偏った答えを出すことをいうんだよ。たとえば、猫の画像ばかり学習させると、犬を見せても猫と答えてしまうようなものだね。
AIを知りたい
じゃあ、人間が間違った情報を教え込むと、AIも間違った答えを出すってことですか?
AIエンジニア
そういうこと!人間がAIに与えるデータが偏っていたり、間違っていたりすると、AIはその間違いをそのまま学習してしまうんだ。だから、AIに正しい情報を教えることがとても大切なんだよ。
機械学習バイアスとは。
人工知能に関する言葉で「機械学習の偏り」というものがあります。「粗悪な材料を使えば、粗悪な製品ができる」という言葉を聞いたことがあるでしょうか?機械学習の偏りは、まさにそれと同じことが人工知能で起こることを指します。コンピュータに偏った情報を与えると、偏った判断をしてしまいます。これは、人間がコンピュータに与えるデータを選ぶ際に意図的に偏ったデータを選んでしまうこと、気づかないうちに偏ったデータを含めてしまうこと、あるいはコンピュータが学習する過程で間違った思い込みをしてしまい、偏った結果を出してしまうことなどが原因です。
機械学習バイアスとは

機械学習は、膨大な量の情報を材料に、そこから規則性を見つけて未来を予測したり、物事を判断したりする力強い技術です。しかし、この学習という作業の中で、材料となる情報に潜む偏りや歪みが、そのまま機械の思考に取り込まれてしまうことがあります。これを機械学習バイアスと呼びます。まるで、汚れた粘土を使えば、どんなに丁寧に形を作っても汚れた作品になってしまうように、偏った情報で学習した人工知能は、偏った結果しか出せません。
このバイアスは、作る人が気づかずに機械の思考に組み込まれてしまう場合もありますし、もとから情報の中に潜んでいる社会の偏見や差別を反映してしまう場合もあります。例えば、過去の採用情報の中に、男性が有利になるような偏った傾向が含まれていたとします。何も考えずにこの情報で人工知能を学習させると、人工知能は女性よりも男性の方を採用しやすいと判断するようになってしまいます。また、犯罪の発生率を予測する人工知能を開発するとします。もし学習データとして、特定の地域でより多くの警察官がパトロールし、その結果としてより多くの逮捕者が出ているという偏った情報を与えてしまうと、人工知能はその地域で犯罪が多いと誤って学習してしまいます。
このように、機械学習バイアスは、人工知能の公平さや信頼性を損なう重大な問題です。人工知能が社会の様々な場面で使われるようになるにつれて、このバイアスによる影響はますます大きくなります。だからこそ、バイアスを減らし、より公平で信頼できる人工知能を作るための研究や開発が、今、非常に重要になっています。
| 機械学習バイアス | 説明 | 例 |
|---|---|---|
| 概要 | 学習データに潜む偏りや歪みが機械学習モデルに取り込まれ、偏った結果を生み出す現象。 | 汚れた粘土で作品を作ると、作品も汚れてしまうように、偏った情報で学習したAIは偏った結果しか出せない。 |
| 原因 | 開発者が気づかずにバイアスを組み込んでしまう場合や、学習データに社会の偏見や差別が反映されている場合がある。 | – |
| 例1:採用AI | 過去の採用情報に男性が有利になる偏りがある場合、AIは男性を採用しやすいと判断する。 | – |
| 例2:犯罪予測AI | 特定地域のパトロール強化による逮捕者数の増加を学習データに用いると、AIはその地域で犯罪が多いと誤って学習する。 | – |
| 影響 | AIの公平さや信頼性を損ない、AIの利用拡大に伴い影響も増大する。 | – |
| 対策 | バイアスを減らし、公平で信頼できるAIを作るための研究開発が重要。 | – |
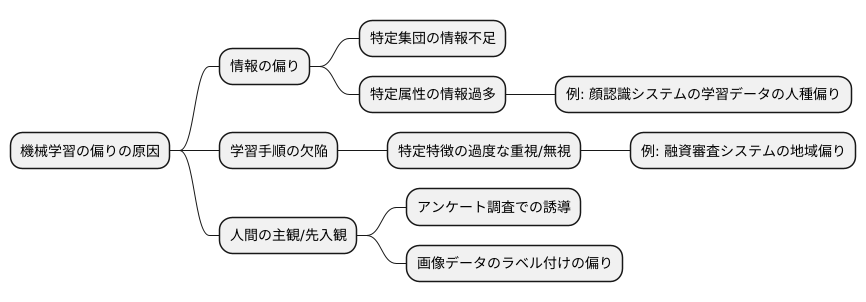
バイアスの原因を探る

機械学習の偏りは、様々な要素が複雑に絡み合い、発生する問題です。その原因を探ることは、公正で信頼できるシステムを構築するために不可欠です。まず、学習に用いる情報の偏りが大きな要因となります。特定の集団に関する情報が不足していたり、逆に特定の属性を持つ情報が過剰に含まれていると、学習結果に偏りが生じます。例えば、顔認識システムの学習データに特定の人種が多く含まれている場合、他の人種の顔を認識する精度が低くなるといった問題が起こりえます。
次に、学習手順そのものに欠陥がある場合も偏りにつながります。学習手順が特定の特徴を過度に重視したり、逆に無視したりすることで、偏った結果が生まれる可能性があります。例えば、融資の審査システムが過去の顧客データに基づいて学習し、特定の地域に住む人々への融資を不利にするような偏った判断をするかもしれません。これは、過去のデータに地域差による偏りが含まれていた場合に起こりえます。
さらに、情報を集める段階で、人間の主観や先入観が入り込むこともあります。例えば、アンケート調査で、質問の仕方や選択肢の設定によって、回答者の意見が誘導される場合があります。また、画像データにラベルを付ける際に、担当者の先入観によってラベル付けに偏りが生じることもあります。このように、情報の偏り、学習手順の欠陥、人間の主観など、様々な要因が複雑に絡み合い、機械学習の偏りを生み出します。これらの要因を理解し、対策を講じることで、より公正で信頼できるシステムを構築することが可能になります。
バイアスの影響と危険性

機械学習は私たちの暮らしを便利にする多くの技術に用いられていますが、その仕組みに潜む『かたより』は時として大きな問題を引き起こします。この『かたより』を、私たちは『偏り』と呼びます。偏りは、機械学習の学習データに偏りがある場合に発生し、様々な場面で思わぬ悪影響を及ぼすことがあります。
例えば、企業の採用活動を考えてみましょう。履歴書をもとに採用候補者を選別するシステムに偏りが含まれていると、特定の性別や出身地の人々が不当に低い評価を受ける可能性があります。優秀な人材を見落とすばかりか、社会における不平等をさらに深刻化させる恐れもあるのです。
また、お金を貸すかどうかの審査を行うシステムにも同様の危険性が潜んでいます。過去のデータに基づいて判断を行うシステムに偏りが存在すると、特定の地域に住む人々がお金を借りづらくなるかもしれません。これは、その地域社会の経済活動を停滞させるばかりでなく、人々の生活を苦しめることにも繋がりかねません。
さらに、犯罪の発生を予測するシステムにおいても、偏りは重大な問題を引き起こします。特定の民族や人種の人々が犯罪者だと誤って判断される可能性があるからです。これは、個人の人権を侵害するだけでなく、社会全体の信頼関係を損なう深刻な事態につながるでしょう。
このように、人工知能の利用が拡大するにつれて、偏りの影響はますます大きくなると考えられます。偏りが生む問題は、社会の公平性や人々の権利に深く関わるため、私たちは早急に適切な対策を講じる必要があります。偏りのない、公正な人工知能の実現に向けて、技術的な改善はもちろんのこと、社会全体の意識改革も必要不可欠です。
| 場面 | 偏りの影響 | 具体的な問題 |
|---|---|---|
| 企業の採用活動 | 特定の性別や出身地の人々が不当に低い評価を受ける | 優秀な人材の見落とし、社会における不平等の深刻化 |
| お金の貸し出し審査 | 特定の地域に住む人々がお金を借りづらくなる | 地域社会の経済活動の停滞、人々の生活の苦難 |
| 犯罪の発生予測 | 特定の民族や人種の人々が犯罪者だと誤って判断される | 個人の人権侵害、社会全体の信頼関係の損失 |
バイアスへの対策

機械学習は多くの分野で活用されていますが、その学習過程で偏りが生じることがあります。これをバイアスと呼び、結果の公平性や信頼性を損なう可能性があります。このバイアスへの対策は、多角的に行う必要があります。まず学習に用いるデータの多様性を確保することが重要です。特定の属性を持つデータばかりで学習すると、その属性に偏った結果が出やすくなります。例えば、ある特定の地域の人々のデータのみで学習した結果を、他の地域の人々に適用すると、正確な結果が得られない可能性があります。そのため、様々な属性を持つデータをバランス良く収集し、偏りのない学習を実現することが不可欠です。年齢、性別、地域、文化など、多様な要素を考慮してデータを収集することで、より公平な結果を得ることができます。次に、用いる計算手法そのものの改善も重要です。特定の特徴に過度に依存する計算手法を用いると、その特徴が結果に大きく影響してしまう可能性があります。例えば、融資の審査で特定の職業の人に不利な結果が出るような計算手法は避けなければなりません。そのため、特定の特徴に偏らない、より公平な計算手法を開発し、利用することが大切です。多くの要素を総合的に判断する計算手法を用いることで、より公正な結果を得ることができます。さらに、機械学習の結果を人が監視し、評価することも必要です。計算手法は完璧ではなく、予期せぬバイアスが生じる可能性があります。そのため、人が計算結果を確認し、偏りの有無を判断することが重要です。もし偏りが発見された場合は、その原因を分析し、データの修正や計算手法の見直しなどの対策を講じる必要があります。このように、データの多様性の確保、計算手法の改善、そして人の監視と評価を組み合わせることで、機械学習におけるバイアスの影響を最小限に抑え、より公平で信頼性の高い結果を得ることができます。これらの対策は、機械学習を社会で適切に活用するために不可欠です。
| 対策 | 詳細 | 例 |
|---|---|---|
| データの多様性の確保 | 様々な属性を持つデータをバランス良く収集し、偏りのない学習を実現する。年齢、性別、地域、文化など、多様な要素を考慮する。 | 特定の地域の人々のデータのみで学習した結果を、他の地域の人々に適用すると、正確な結果が得られない可能性がある。 |
| 計算手法の改善 | 特定の特徴に過度に依存する計算手法を避け、より公平な計算手法を開発し、利用する。多くの要素を総合的に判断する計算手法を用いる。 | 融資の審査で特定の職業の人に不利な結果が出るような計算手法は避ける。 |
| 人の監視と評価 | 人が計算結果を確認し、偏りの有無を判断する。偏りが発見された場合は、その原因を分析し、データの修正や計算手法の見直しなどの対策を講じる。 | 計算手法は完璧ではなく、予期せぬバイアスが生じる可能性があるため、人が確認し対策を講じる。 |
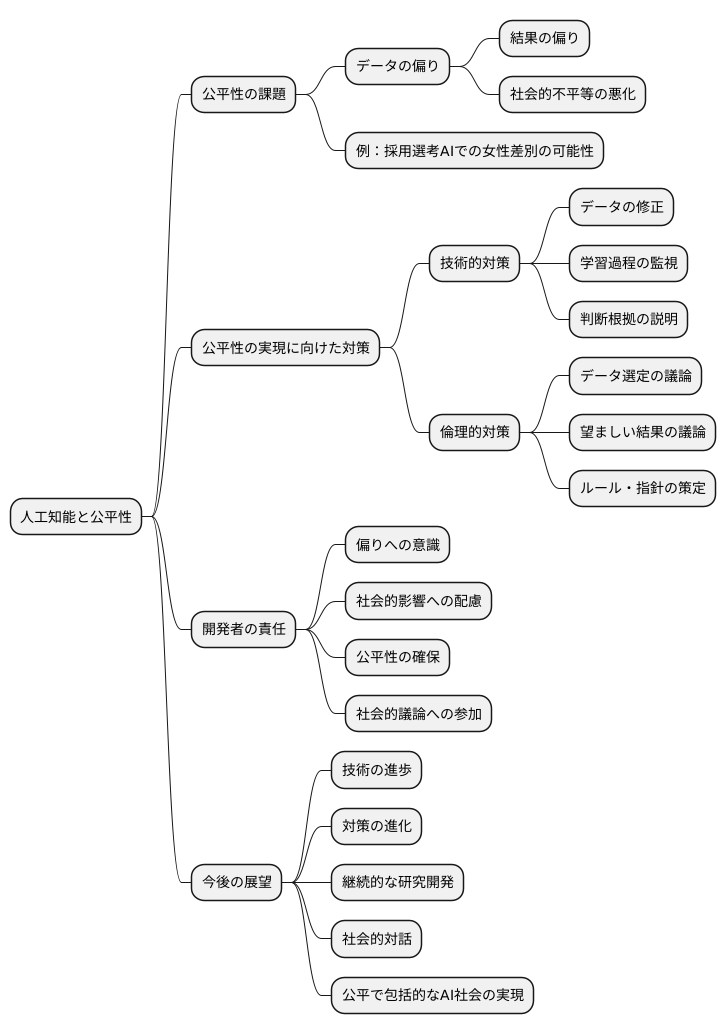
公平なAI実現に向けて

人工知能は私たちの暮らしを大きく変える力を持っていますが、その開発には公平性という大きな課題が伴います。人工知能の学習に使われるデータに偏りがあると、その人工知能が出す結果にも偏りが生じ、社会的な不平等を悪化させる可能性があります。例えば、採用選考の人工知能が過去のデータから男性を優遇するように学習してしまうと、女性の採用機会が不公平に奪われるかもしれません。
公平で信頼できる人工知能を実現するためには、技術的な対策が必要です。偏りのあるデータを修正したり、人工知能の学習過程を監視することで、偏りの発生を抑えることができます。また、人工知能がどのように判断を下したのかを説明できるようにする技術も重要です。これにより、偏りが生じた場合に原因を特定しやすくなり、修正も容易になります。
しかし、技術的な対策だけでは不十分です。倫理的な観点からの議論も欠かせません。どのようなデータを使うべきか、どのような結果が望ましいのか、人工知能の開発者だけでなく、社会全体で議論を深める必要があります。また、人工知能の利用に関する適切なルールや指針を定めることも重要です。
人工知能の開発者は、常に偏りの影響を意識し、責任ある行動をとる必要があります。自分たちが開発する人工知能が社会にどのような影響を与えるかを常に考え、公平性を確保するために最善を尽くす必要があります。また、社会全体の議論に参加し、倫理的な問題点について積極的に発言していくことも重要です。
人工知能技術は日々進歩しています。だからこそ、偏りへの対策も進化させ続けなければなりません。継続的な研究開発と社会的な対話を通じて、誰もが恩恵を受けられる、公平で全ての人々を含む人工知能社会を実現していくことが、私たちの使命です。