
統計翻訳:言葉の壁を越える技術

AIを知りたい
先生、「統計学的機械翻訳」ってどういう意味ですか? インターネットのページが増えたことと何か関係があるって聞いたんですけど…

AIエンジニア
いい質問だね。統計学的機械翻訳というのは、たくさんの文章を統計的に解析することで、ある言語の文章を別の言語の文章に変換する方法のことだよ。インターネット上にたくさんのウェブページが増えたことで、翻訳の学習に使えるデータが爆発的に増えたんだ。
AIを知りたい
たくさんの文章を統計的に解析するって、具体的にどういうことですか?
AIエンジニア
例えば、「こんにちは」という日本語に対応する英語は何かを、膨大な日英対訳データから確率的に計算するんだよ。「こんにちは」に対応する英語は「Hello」が多いから、「こんにちは」を「Hello」と翻訳する確率が高いと判断するんだね。つまり、データに基づいて翻訳するんだよ。
統計学的機械翻訳とは。
人工知能に関わる言葉である「統計を用いた機械翻訳」について説明します。ここ二十年ほどでインターネットのホームページが爆発的に増えました。このおかげで、ホームページにある文字を扱う、自然言語処理という技術の研究が大きく進みました。つまり、自然言語処理という分野の研究が急速に発展したのです。
機械翻訳の新たな波

近年、言葉を通訳する機械の技術に大きな変化が起きています。これまで主流だった文法の規則に基づいた翻訳方法から、統計に基づいた方法へと変わりつつあります。この変化の背景には、誰もが使える情報網の広がりによって、莫大な量の文章データが集められるようになったことがあります。
インターネット上には、様々な言語で書かれたニュースや小説、会話記録など、膨大な量の文章データが存在します。これらのデータは、まるで洪水のように押し寄せ、統計に基づいた機械翻訳という新しい方法を大きく発展させました。統計に基づいた機械翻訳は、大量の文章データを分析することで、ある言葉が別の言葉にどのように翻訳されるかの確率を計算します。例えば、「こんにちは」という日本語が英語で「Hello」と訳される確率や、「こんばんは」が「Good evening」と訳される確率などを、実際に使われている文章データから学習します。このようにして、より自然で正確な翻訳が可能になりました。
従来の規則に基づいた翻訳では、文法の例外や言葉の微妙なニュアンスを捉えるのが難しく、不自然な翻訳結果になることがありました。しかし、統計に基づいた翻訳では、大量のデータから言葉の使い方のパターンを学習するため、より自然な翻訳が可能になります。また、新しい言葉や表現が登場した場合でも、データを追加学習させることで、柔軟に対応できます。
このように、情報網の普及と統計に基づいた翻訳技術の発展は、言葉の壁を低くする大きな可能性を秘めています。異なる言葉を話す人同士が、まるで同じ言葉を話すかのように自由にコミュニケーションできる未来も、そう遠くないかもしれません。まさに、言葉を通訳する機械における新たな波の到来と言えるでしょう。
| 項目 | 内容 |
|---|---|
| 従来の翻訳手法 | 文法規則に基づく |
| 近年主流の翻訳手法 | 統計に基づく |
| 変化の背景 | インターネットの普及による大量の文章データの入手 |
| 統計に基づく翻訳の特徴 | 大量の文章データを分析し、翻訳確率を計算 |
| 統計に基づく翻訳のメリット | より自然で正確な翻訳が可能、新しい表現への柔軟な対応 |
| 従来の翻訳の課題 | 文法の例外やニュアンスの表現が難しい |
| 将来展望 | 言葉の壁が低くなり、異なる言語話者同士の円滑なコミュニケーションが可能に |
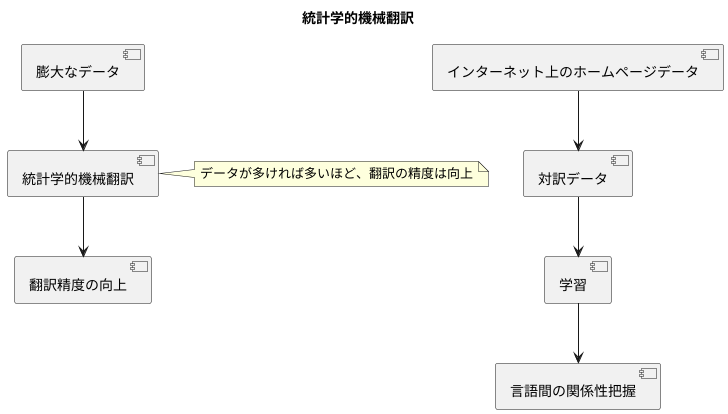
膨大なデータの活用

近年の情報技術の発達に伴い、世界中で膨大な量のデータが生み出されています。この膨大なデータをうまく活用することで、様々な分野で革新的な進歩が生まれています。その代表例の一つが統計学的機械翻訳です。
統計学的機械翻訳は、原文と翻訳文の組み合わせである対訳データを使って学習を行います。具体的には、大量の対訳データをコンピュータに読み込ませ、ある言葉が別の言語でどのように表現されるのか、どのような言葉の並び方が使われるのかといった、言語間の関係性を統計的に学習させます。まるで、言葉を翻訳するための辞書や文法書を自動的に作っているようなものです。
この学習に使うデータが多ければ多いほど、翻訳の精度は向上します。少しの例文を覚えただけでは、なかなか正確な翻訳はできませんが、たくさんの例文を学ぶことで、より自然で正確な翻訳が可能になるのと同じです。インターネット上に存在する膨大な量のホームページデータは、まさにこの学習データとして最適です。様々な言語で書かれた、多種多様な内容のホームページデータは、統計学的機械翻訳の精度向上に大きく貢献しています。
このように、インターネット上に存在する膨大なデータは、宝の山とも言えます。統計学的機械翻訳は、この宝の山から知識を掘り起こし、私たちのコミュニケーションをより豊かに、よりスムーズにするための技術です。まさに、データこそ宝という時代を象徴する技術と言えるでしょう。
確率に基づく翻訳

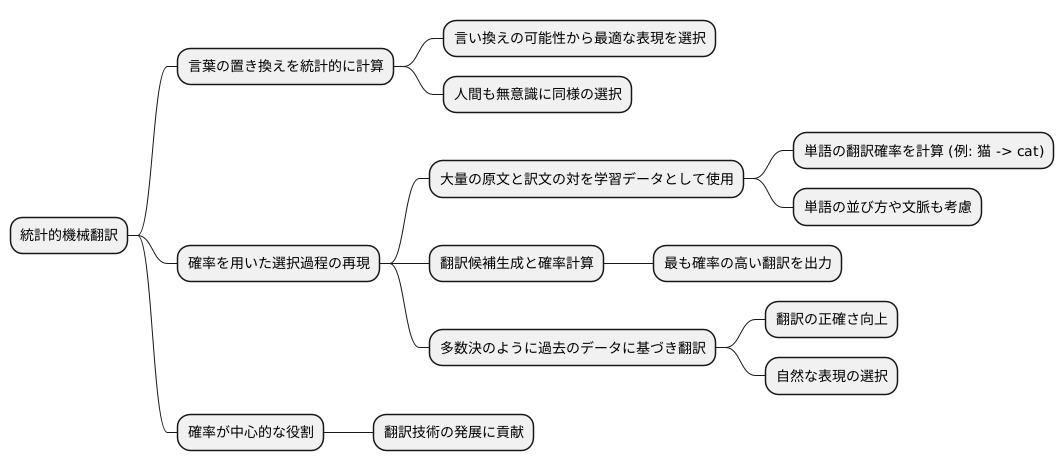
言葉の置き換えを統計的な計算によって行う、統計的機械翻訳という技術があります。これは、ある文章を別の言葉に置き換える時、様々な言い換えの可能性の中から、一番ふさわしい表現を選ぶというものです。人間が翻訳をする際も、無意識のうちに同じような選択を行っています。統計的機械翻訳は、この選択の過程を、確率という数値を使って再現しています。
具体的には、大量の文章を学習データとして用います。この学習データには、原文と、人間が翻訳した正しい訳文が対になって含まれています。機械はこのデータから、ある言葉が別の言葉に置き換えられる確率を計算します。例えば、「猫」という日本語が「cat」という英語に翻訳される確率、あるいは「美しい」という日本語が「beautiful」という英語に翻訳される確率などを、過去のデータに基づいて算出します。
翻訳したい文章が与えられると、機械は様々な翻訳候補を生成し、それぞれの候補の確率を計算します。この確率は、個々の単語の翻訳確率だけでなく、単語の並び方や文脈なども考慮に入れて計算されます。つまり、ただ単語を置き換えるだけでなく、文全体の流れが自然になるように、より確率の高い翻訳を選び出そうとします。
そして、最終的に最も確率の高い翻訳が、最適な翻訳結果として出力されます。この手法は、まるで多数決のように、過去のデータに基づいて最も妥当な翻訳を選び出すため、翻訳の正確さを向上させるのに役立っています。大量のデータから学習することで、人間の翻訳者のように、文脈に合った自然な表現を選び出すことができるのです。このように、確率という概念は、統計的機械翻訳において中心的な役割を果たしており、今後の翻訳技術の発展にも大きく貢献していくと考えられます。
自然な翻訳の実現

言葉の壁をなくし、まるで母語話者のように自然で流暢な翻訳を実現することは、長年の夢でした。従来の翻訳手法は、文法規則を忠実に守ることに重点を置いていましたが、この方法は時に不自然でぎこちない表現を生み出す原因となっていました。例えば、ある言語特有の言い回しや慣用句は、単純な置き換えではうまく伝わりません。直訳すると意味が通じないばかりか、かえって誤解を招く可能性もあるのです。
しかし、統計に基づいた機械翻訳の登場は、この状況を一変させました。膨大な量の言語データから学習することで、機械は言葉の奥深くに潜むパターンやニュアンスを捉えられるようになりました。まるで職人が長年の経験から技を磨くように、機械もまたデータという経験から自然な表現方法を学んでいくのです。これは単なる単語の置き換えではなく、文脈や文化的背景までも考慮に入れた、より高度な翻訳を可能にします。
この技術の進歩は、翻訳の質を飛躍的に向上させました。以前は専門の翻訳者でなければ難しかった、自然で滑らかな文章が、機械によって自動的に生成されるようになったのです。読者はまるで原文を読んでいるかのような感覚で、翻訳された文章を楽しむことができます。これは翻訳作業の効率化だけでなく、異文化間の理解促進にも大きく貢献しています。例えば、海外のニュースや文献を母国語でスムーズに読めるようになれば、世界中で起きている出来事をより深く理解し、多様な文化に触れる機会も増えるでしょう。まさに言葉の壁が取り払われ、世界中の人々がより密接につながる未来への扉が開かれたと言えるでしょう。
| 従来の翻訳手法 | 統計に基づいた機械翻訳 |
|---|---|
| 文法規則を忠実に守ることに重点 | 膨大な量の言語データから学習 |
| 不自然でぎこちない表現 | 言葉の奥深くに潜むパターンやニュアンスを捉える |
| 言い回しや慣用句の直訳による誤解 | 文脈や文化的背景までも考慮 |
| 翻訳の質に限界 | 自然で滑らかな文章の自動生成 |
| 翻訳作業の効率化、異文化間の理解促進 |
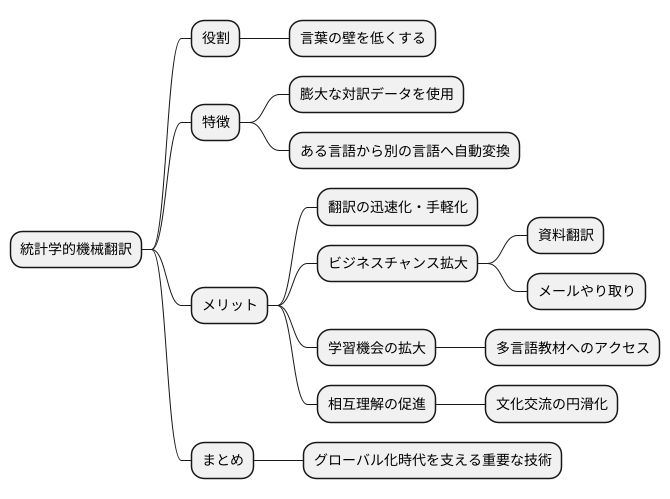
言葉の壁を低くする

異なる言葉を話す人々の間にある言葉の壁。この壁を低くする技術として、統計学的機械翻訳は大きな役割を果たしています。統計学的機械翻訳とは、膨大な量の対訳データを用いて、ある言語の文章を別の言語の文章へと自動的に変換する技術です。
従来の翻訳作業は、高度な言語能力を持つ専門家が時間をかけて行う必要がありました。しかし統計学的機械翻訳の登場により、より手軽に、より迅速に翻訳を行うことが可能となりました。この技術は、まるで魔法の杖のように、言葉の壁を乗り越え、人々の意思疎通を円滑にする力を持っています。
ビジネスの場を考えてみましょう。海外との取引や商談の際に、言葉の壁は大きな障害となります。しかし、統計学的機械翻訳を用いることで、資料の翻訳やメールのやり取りがスムーズになり、ビジネスチャンスの拡大に繋がります。また、教育の場では、様々な言語で書かれた教材にアクセスすることが可能となり、学習機会の幅が広がります。さらに、文化交流においても、異なる文化圏の人々が容易にコミュニケーションを取ることができるようになるため、相互理解の促進に大きく貢献します。
国際化が加速する現代社会において、統計学的機械翻訳はなくてはならない存在になりつつあります。この技術の更なる発展により、言葉の壁はますます低くなり、人々はより密接に繋がり、より豊かな国際社会を築いていくことができるでしょう。まさに、グローバル化時代を支える重要な技術と言えるでしょう。
今後の展望と課題

統計を用いた機械翻訳は近年、目覚しい発展を遂げ、目を見張る成果を上げてきました。異なる言葉を話す人々同士の意思疎通を円滑にし、世界中の人々を繋ぐ架け橋となる可能性を秘めています。しかし、この技術が真に世界を変えるためには、依然として乗り越えるべき課題が存在します。
まず、機械翻訳の精度は学習に用いるデータの量に大きく左右されます。質の高い翻訳結果を得るには、膨大な量の対訳データが必要となりますが、分野によってはデータの入手が困難な場合もあり、これが精度向上の妨げとなっています。特に、専門性の高い分野や、口語表現、方言などが含まれるデータは不足しており、これらの分野での翻訳精度の向上は喫緊の課題と言えるでしょう。
次に、機械翻訳は文脈の理解に苦労する傾向があります。人間であれば、前後の文脈や状況、文化的な背景などを考慮して言葉の意味を理解しますが、機械翻訳は、単語や短い句を単位として処理するため、複雑な文脈を正確に捉えることが難しいのです。例えば、比喩表現や皮肉、婉曲表現などは、文脈を理解しなければ誤訳につながる可能性が高く、より高度な文脈理解能力の開発が求められます。
とはいえ、機械翻訳の未来は決して暗いものではありません。深層学習に代表される新しい技術の登場により、文脈理解やデータ不足といった課題も克服されつつあります。深層学習は、人間の脳の仕組みを模倣した学習方法であり、従来の手法では難しかった複雑な文脈の理解や、少量のデータからの学習を可能にします。今後、更なる研究開発が進むことで、より自然で、人間らしい翻訳が実現されると期待されます。
機械翻訳技術の進歩は、言葉の壁を取り払い、グローバルなコミュニケーションを促進するだけでなく、文化交流や国際協力の活性化にも大きく貢献するでしょう。そして、人々の相互理解を深め、より豊かで、より繋がりの強い世界を実現するための原動力となるはずです。
| 課題 | 詳細 |
|---|---|
| データ不足 | 質の高い翻訳結果には膨大な対訳データが必要だが、専門性の高い分野や口語表現、方言などのデータは不足している。 |
| 文脈理解の困難さ | 単語や短い句を単位として処理するため、複雑な文脈(比喩、皮肉、婉曲表現など)を正確に捉えることが難しい。 |
| 将来展望 | 詳細 |
|---|---|
| 深層学習による克服 | 深層学習により、複雑な文脈の理解や少量データからの学習が可能になりつつある。 |
| 更なる発展への期待 | 研究開発の進展により、より自然で人間らしい翻訳の実現が期待される。 |
| 機械翻訳の貢献 | 詳細 |
|---|---|
| グローバルコミュニケーションの促進 | 言葉の壁を取り払い、国際的な意思疎通を円滑にする。 |
| 文化交流と国際協力の活性化 | 文化交流を促進、国際協力を活性化する。 |
| 相互理解の深化 | 人々の相互理解を深め、より豊かで繋がりの強い世界を実現する。 |