
強化学習で学ぶ賢いエージェント

AIを知りたい
『エージェント』って言葉がよく出てきますが、実際にはどういう意味で使われているのでしょうか?

AIエンジニア
そうですね。『エージェント』とは、簡単に言うと、ある環境の中で自分で考えて行動するプログラムのことです。人間で例えると、ゲームをしている人がエージェント、ゲームの世界が環境にあたります。
AIを知りたい
ゲームをしている人ですか。確かに、ゲームでは自分で考えて行動しますね。でも、AIの場合はどのように『考える』のでしょうか?
AIエンジニア
AIの場合は、色々な行動を試してみて、その結果に応じて行動を修正していきます。ゲームでいうと、高い得点が出たら、その行動を覚える、低い得点だったら、違う行動を試す、といった感じです。このように、試行錯誤を繰り返すことで、より良い行動を学習していくのです。
エージェントとは。
人工知能の分野でよく使われる「代理人」という言葉について説明します。特に、試行錯誤を通じて学習する仕組みにおいて、この代理人は、ある特定の状況の中で様々な行動を試しながら、正しい答えを見つけようとします。代理人が行動を起こすたびに、その行動が良いか悪いかに応じて報酬が与えられます。代理人は、より多くの報酬を得られるような行動を学ぶことを目指します。
はじめに

人工知能の世界で近年注目を集めているのが、強化学習という学習手法です。この手法では「エージェント」と呼ばれるものが中心的な役割を果たします。エージェントとは、あたかもコンピュータゲームの主人公のように、仮想的に作られた環境の中で試行錯誤を繰り返しながら学習していくプログラムのことです。
このエージェントは、私たち人間が日常生活で経験を積んでいく過程とよく似ています。例えば、自転車に乗る練習を思い浮かべてみてください。最初は何度も転んでしまうかもしれませんが、繰り返し練習することで徐々にバランスの取り方を覚え、最終的にはスムーズに走れるようになります。強化学習におけるエージェントもこれと同じように、仮想環境の中で様々な行動を試み、その結果に応じて成功や失敗を経験しながら、最適な行動を学習していくのです。
具体的には、エージェントはまず仮想環境の中で何らかの行動をとります。そして、その行動が環境にどのような変化をもたらすかを観測し、その結果が良いものであれば報酬を得て、悪いものであれば罰を受けます。エージェントは、この報酬と罰の情報を基に、より多くの報酬を得られるような行動を学習していくのです。まるで、私たちが褒められると嬉しいと感じ、叱られると反省するように、エージェントも報酬と罰を通じて学習していきます。
このように、試行錯誤を通して学習していく強化学習のアプローチは、私たち人間の学習方法と共通点が多く、だからこそ人工知能の可能性を広げる重要な技術として注目されているのです。そして、この技術は、ゲームの攻略だけでなく、ロボット制御や自動運転技術、さらには創薬など、様々な分野への応用が期待されています。
エージェントの学習方法

知的な働きをするもの、つまりエージェントがどのように学習していくか、その方法について説明します。エージェントの学習は、人間が新しいことを覚える過程によく似ています。例えば、自転車に乗ることを考えてみましょう。最初は何度も転んでしまうかもしれません。しかし、ペダルを漕ぎ、バランスを取るという試行錯誤を繰り返すうちに、徐々に上手に乗れるようになります。エージェントの学習もこれと同じで、試行錯誤と、その結果として得られる報酬が学習の鍵となります。
エージェントは、与えられた環境の中で様々な行動を取ります。そして、それぞれの行動に対して、良い結果であれば報酬が与えられ、悪い結果であれば報酬が与えられません。この報酬は、エージェントにとって、行動の良し悪しを示す大切な指標となります。エージェントの目的は、より多くの報酬を得ることです。そのため、エージェントは、過去に得られた報酬を参考に、次にどのような行動を取ればより多くの報酬を得られるかを考え、学習していきます。
迷路を想像してみてください。迷路の中には、いくつもの道があり、その中には行き止まりもあります。エージェントは、まるで迷路の中でゴールを目指すように、試行錯誤しながら最適な経路を探します。この時、報酬は、ゴールへの道しるべの役割を果たします。報酬という手がかりを頼りに、エージェントは徐々に正しい道を見つけていくのです。
小さな子供が新しいおもちゃで遊ぶ様子を思い浮かべてみてください。子供は、おもちゃの仕組みを理解するために、色々なことを試してみます。ボタンを押したり、レバーを回したり、試行錯誤を繰り返しながら、おもちゃの遊び方を学んでいきます。最初はうまくいかないことも多いですが、徐々に成功体験を積み重ね、最終的にはおもちゃで自由に遊べるようになります。エージェントの学習もこれと全く同じです。最初は試行錯誤の連続ですが、経験を積むことで、最終的には目的を達成する方法を習得するのです。
環境との相互作用

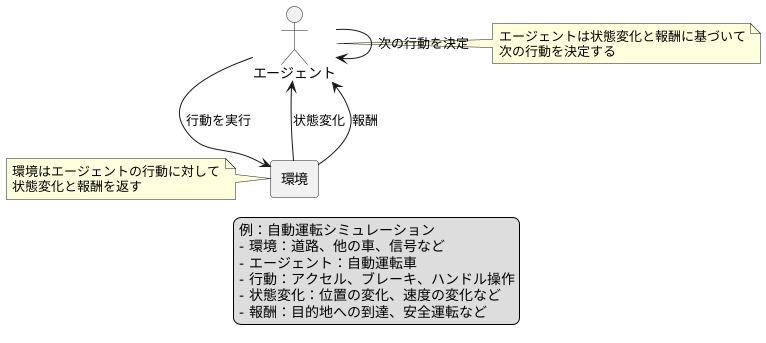
私たちは、常に周りの環境と関わり合いながら生活しています。温度を感じたり、物を見たり、音を聞いたり、様々な情報を環境から受け取っています。そして、受け取った情報に応じて、服を着替えたり、道を歩いたり、人と話したりと、様々な行動を選択します。これはまるで、私たち自身がある種の学習主体、すなわち「学習する者」であるかのように機能していることを示しています。私たちが環境と相互作用する方法と同様に、人工知能の分野でも「エージェント」と呼ばれる学習主体が環境との相互作用を通して学習を行います。このエージェントは、私たちと同じように、環境の中に存在し、環境から情報を受け取り、行動を実行します。
エージェントが行動する環境は、現実世界の場合もあれば、コンピュータ上に構築された仮想世界の場合もあります。例えば、自動運転の技術開発では、シミュレーション環境の中でエージェントに運転を学習させることがよく行われます。この環境は、エージェントにとって行動の場であり、エージェントの行動に対して反応を返します。この反応には、「報酬」と呼ばれる行動の良し悪しを示す評価と、「状態」と呼ばれる環境の状態変化が含まれます。エージェントは、熱いストーブに触れると「熱い」という感覚を経験するように、環境から状態変化というフィードバックを受け取ります。そして、ストーブに触れたことで「火傷」という痛みを経験するように、報酬を通じて行動の良し悪しを学習します。
エージェントは、環境から受け取った状態と報酬の情報に基づいて、次にどのような行動をとるべきかを決定します。熱いストーブに触れて火傷をした経験があれば、次にストーブを見た時には触らないという行動を選択します。このように、エージェントも環境との相互作用を通して、試行錯誤を繰り返し、より良い行動を選択できるよう学習していきます。この学習プロセスは、私たち人間が経験を通して学習していく過程と非常によく似ています。環境からのフィードバック、すなわち状態と報酬の情報こそが、エージェントが学習し、成長していくための鍵となるのです。
報酬の役割

学習する機械、いわゆるエージェントにとって、報酬とは教師からの褒め言葉のようなものです。教師が生徒の良い行動を褒めることで、生徒はやる気を出してより良くしようとします。これと同じように、エージェントも報酬を得ることで、どのような行動が良いのかを学びます。そして、より多くの報酬を得られるように、自分の行動を改善していくのです。
報酬には様々な種類があります。例えば、ゲームで高い点数を出すことが報酬となる場合もあれば、ロボットが目的の場所に到達することが報酬となる場合もあります。また、ある製品を作る際に、不良品を少なくすることが報酬となることもあります。このように、報酬は目的によって様々です。
報酬の与え方は、エージェントの学習に大きな影響を与えます。例えば、ゲームで高い点数を得るだけでなく、敵を倒すことにも報酬を与えると、エージェントは点数を稼ぐだけでなく、積極的に敵を倒そうとするでしょう。もし、敵を倒すことへの報酬が大きすぎると、点数を稼ぐことを忘れて、敵ばかり追いかけるようになるかもしれません。このように、報酬の設定方法によって、エージェントの行動は大きく変わるのです。
適切な報酬を設定することは、エージェントをうまく学習させる鍵となります。まるで、教師が生徒の良い点を褒めて伸ばすように、適切な報酬はエージェントの学習を促進し、望ましい行動へと導きます。逆に、不適切な報酬を設定してしまうと、エージェントは期待とは異なる行動をとってしまう可能性があります。そのため、エージェントにどのような行動をさせたいのかを明確に理解し、それに合わせた報酬を設定することが非常に重要です。適切に設定された報酬は、エージェントがより賢く、より能力を高めるための、なくてはならない要素と言えるでしょう。
| 概念 | 説明 | 例 |
|---|---|---|
| 報酬 | エージェントが良い行動をとった時に与えられる褒め言葉のようなもの。エージェントは報酬を得ることで、どのような行動が良いのかを学び、より多くの報酬を得られるように行動を改善する。 | ゲームの高得点、ロボットの目標到達、製品の不良品削減 |
| 報酬の種類 | 目的によって様々。 | ゲームのスコア、ロボットの移動距離、生産ラインの不良品数 |
| 報酬の与え方 | エージェントの学習に大きな影響を与える。 | ゲームで高得点に加えて敵を倒すことにも報酬を与える。 |
| 適切な報酬設定 | エージェントをうまく学習させる鍵。エージェントの学習を促進し、望ましい行動へと導く。 | 生徒の良い点を褒めて伸ばす |
| 不適切な報酬設定 | エージェントは期待とは異なる行動をとってしまう可能性がある。 | 敵を倒す報酬が大きすぎると、点数を稼ぐことを忘れて敵ばかり追いかける。 |
応用例

強化学習の使い道は本当に幅広く、様々な分野で活躍しています。代表的な例としては、ゲームの知能や機械の操作、自動で動く車の技術、資源の使い方、病気の診断などがあげられます。まるで人間の脳のように学習する能力を持つため、複雑な課題を解決するのに役立ちます。
例えば、囲碁や将棋といったゲームでは、強化学習で作った知能は、自分自身と何度も対戦することでどんどん賢くなっていきます。そしてついには、人間のトップレベルの棋士にも勝ってしまうほどの力を身につけるのです。これは、強化学習が膨大な量のデータを元に、最適な手を自ら見つけ出すことができるからです。
また、機械を動かす分野でも、強化学習は力を発揮します。ロボットに複雑な動きを教えたいとき、従来の方法では人間が一つ一つ動き方をプログラムする必要がありました。しかし、強化学習を使えば、ロボットは試行錯誤を繰り返すことで、自ら動き方を学習することができます。例えば、物を掴む、運ぶ、組み立てるといった作業を、まるで人間のように器用にこなせるようになるのです。これは工場での作業や、人間には危険な場所での作業をロボットに任せられるようになるため、私たちの生活をより安全で便利なものにしてくれます。
さらに、自動で動く車の技術にも、強化学習は欠かせません。周りの状況を判断し、安全に運転するためには、複雑な状況に対応できる能力が必要です。強化学習を使うことで、様々な道路状況や天候に対応できる、より安全な自動運転技術を実現できる可能性を秘めています。
このように、強化学習は様々な分野で私たちの生活を豊かに、そして便利にするための技術として、日々進化を続けています。今後ますます発展していくことで、私たちの生活はさらに向上していくことでしょう。これからの強化学習の活躍に、期待が高まります。
| 分野 | 活用例 | 説明 |
|---|---|---|
| ゲーム | 囲碁、将棋 | 自己対戦を通じて学習し、人間のトップ棋士にも勝利できるレベルに到達。 |
| 機械操作 | ロボットによる作業 | 試行錯誤を通じて複雑な動作を学習。掴む、運ぶ、組み立てるといった作業を自動化。 |
| 自動運転 | 自動運転車 | 様々な道路状況や天候に対応できる安全な運転を実現。 |
| その他 | 資源の使い方、病気の診断 | 複雑な課題を解決するのに役立つ。 |
今後の展望

強化学習は発展途上の技術ですが、秘めた可能性は非常に大きく、様々な分野での活用が期待されています。複雑な状況や変化の激しい環境に対応できる意思決定能力を機械に与えるという画期的な仕組みは、人工知能の新たな地平を切り開く重要な鍵となるでしょう。
現在、強化学習は様々な課題に取り組むための研究が進められています。例えば、災害救助ロボットの開発においては、想定外の事態が起こる災害現場で、がれきの撤去や人命救助などの複雑な作業を的確に行うために強化学習が役立ちます。ロボットは試行錯誤を通して、様々な状況に応じて最適な行動を自ら学習し、刻々と変化する状況にも柔軟に対応できるようになります。
また、スマートシティと呼ばれる、情報通信技術を活用した次世代都市の構築においても、強化学習は重要な役割を担うと期待されています。都市全体の交通システムの制御やエネルギー消費の最適化など、複雑に絡み合う様々な要素を考慮しながら、都市機能の効率的な運用を実現するために、強化学習を用いたシステム開発が進められています。複数のシステムが互いに連携し、全体として最適な行動を選択することで、都市全体の快適性や安全性を向上させることが期待できます。
さらに、人間との協調学習も、強化学習の重要な研究分野の一つです。人間の持つ知識や経験を機械学習に取り入れることで、学習の効率を高め、より高度な意思決定能力を実現できると考えられています。例えば、熟練作業員の技術をロボットに学習させることで、高度な技能を必要とする作業の自動化が可能になるでしょう。
このように、強化学習は私たちの社会に大きな変革をもたらす可能性を秘めた技術であり、今後の研究の進展と応用範囲の拡大によって、さらに多くの分野で革新的な変化がもたらされることが期待されています。 人工知能がより賢く、人間社会にとってより役立つ存在となるために、強化学習は今後ますます重要な役割を担っていくでしょう。
| 分野 | 活用例 | 期待される効果 |
|---|---|---|
| 災害救助 | 災害救助ロボットの開発
|
想定外の事態にも対応できるロボットの開発 |
| スマートシティ |
|
|
| 人間との協調学習 | 熟練作業員の技術をロボットに学習 | 高度な技能を必要とする作業の自動化 |