
Q値:行動の価値を測る

AIを知りたい
先生、「Q値」ってなんですか?

AIエンジニア
いい質問だね。強化学習では、AIがとる行動の良し悪しを数値で表す必要があるんだ。その数値のことを「Q値」と呼ぶんだよ。 行動が良いものならQ値は高く、悪いものなら低くなるように学習していくんだ。
AIを知りたい
なるほど。行動の良し悪しを数値で表すんですね。でも、どうやって良し悪しを決めるんですか?
AIエンジニア
AIが行動した結果、報酬がもらえるかどうかで決まるんだ。報酬がもらえる行動はQ値が高くなり、もらえない行動はQ値が低くなる。だから、Q値を高くするように学習すれば、AIは報酬がもらえる行動、つまり適切な行動を学べるんだよ。
Q値とは。
人工知能の分野でよく使われる「Q値」って言葉について説明します。「Q値」っていうのは、強化学習っていう学習方法で出てくる、ある行動の良し悪しを数値で表したものです。もとになるのは「行動価値関数」っていう式の値で、この式の頭文字をとって「Q値」って呼んでいます。この「Q値」をできるだけ良い値にできれば、その行動が適切だったっていうことになるんです。
はじめに

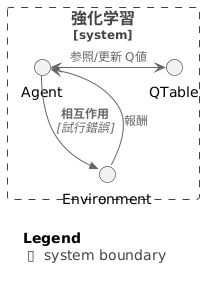
試行錯誤を通して学ぶ強化学習は、人間の学習方法とよく似ています。まるで人が様々な経験から学ぶように、計算機も与えられた状況の中で行動し、その結果得られる報酬を手がかりに学習を進めます。
この学習の過程で最も重要なのは、行動の良し悪しを判断することです。具体的には、将来どれだけの報酬を得られるかを見積もる必要があります。この見積もりを数値で表したものがQ値と呼ばれます。Q値は、ある状態である特定の行動をとった場合の将来得られる報酬の期待値を表します。
強化学習の目的は、このQ値を最大化するように行動を決定する仕組みを作ることです。言い換えれば、様々な行動を試してみて、どの行動が最も高い報酬に繋がるかを学習していくのです。例えば、ロボットが迷路を解くことを考えてみましょう。ロボットは様々な方向に進んでみます。行き止まりに突き当たれば、それは低い報酬に繋がります。正しい道を進めば、より高い報酬が得られます。ロボットは、試行錯誤を通じて、どの道が最終的にゴールにたどり着き、高い報酬を得られるかを学習していくのです。
Q値を適切に学習できれば、どのような状況でも最適な行動を選択できるようになります。迷路の例で言えば、ロボットはどの地点からでも最短経路でゴールにたどり着けるようになります。このように、強化学習は試行錯誤とQ値の学習を通じて、複雑な問題を解決する能力を身につけていくのです。そして、このQ値こそが強化学習の核心と言えるでしょう。
行動価値関数とQ値

強化学習という学習方法では、行動価値関数という考え方が使われます。行動価値関数は、ある特定の状態の時に、ある行動をとった場合に、将来どれだけの報酬がもらえるかを予測する関数です。例えば、迷路でどの道に進むかという選択に迷った時、それぞれの道からゴールまでたどり着くまでに得られる報酬を予測し、最も報酬の高い道を選ぶことが、この関数の役割です。
この行動価値関数の値は、Q値と呼ばれています。Q値は、Quality(質)の頭文字からきています。ある状態である行動をとった時の質の高さを表す値であり、Q値が高いほど、その状態でのその行動は良い行動だと判断できます。迷路の例でいうと、ゴールまでの距離が短い道や、宝箱がある道はQ値が高くなります。反対に、行き止まりに繋がる道や、敵がいる道はQ値が低くなります。
Q値は、行動の価値を数字で表したものと言えるでしょう。環境の状態と行動の組み合わせごとにQ値が計算されます。例えば、迷路の分かれ道ごとに、右に進む、左に進む、まっすぐ進むといった選択肢があり、それぞれの選択肢にQ値が割り当てられます。これらのQ値をもとに、どの行動が最も良いかを判断し、最適な行動を選択します。迷路の例では、最も高いQ値を持つ道を選ぶことで、効率的にゴールを目指せます。このように、強化学習ではQ値を指針として、試行錯誤しながら学習を進めていくのです。
| 用語 | 説明 | 迷路の例 |
|---|---|---|
| 強化学習 | 行動価値関数を使って、将来の報酬を予測し、最適な行動を選択する学習方法。 | 迷路の中で、どの道を選ぶかを学習する。 |
| 行動価値関数 | ある状態である行動をとった場合に、将来どれだけの報酬がもらえるかを予測する関数。 | 各分かれ道で、どの道に進むとゴールまでたどり着けるかを予測する。 |
| Q値 | 行動価値関数の値。Quality(質)の頭文字。Q値が高いほど、その状態でのその行動は良い行動。 | ゴールまでの距離が短い道や、宝箱がある道のQ値は高く、行き止まりや敵がいる道のQ値は低い。 |
Q値の最適化

強化学習とは、試行錯誤を通じて、行動の良し悪しを学習し、最適な行動を見つける方法です。目的は、あらゆる状況で最も多くの報酬を得られる行動を選べるようになることです。この学習の中心となるのがQ値です。Q値とは、特定の状況で特定の行動をとった場合に、将来にわたってどれだけの報酬が得られるかを示す指標です。
Q値の最適化とは、各状況において最も高いQ値を持つ行動を選べるように学習を進めることです。言い換えれば、最も多くの報酬が期待できる行動を見つけるということです。この最適化は、エージェントと呼ばれる学習主体が環境と相互作用しながら行われます。エージェントは、様々な行動を試してみて、その結果として得られた報酬と、その時の状況、そしてとった行動を記録します。
エージェントは、得られた報酬をもとにQ値を更新していきます。例えば、ある状況である行動をとった結果、多くの報酬が得られたとします。すると、エージェントはその状況でその行動をとることに対するQ値を上げます。逆に、報酬が少なかった場合はQ値を下げます。
Q値の更新は、将来得られる報酬を適切に見積もるように調整されます。つまり、すぐに得られる報酬だけでなく、その行動をとった後に続く行動によって得られる報酬も考慮されます。遠い将来に得られる報酬は、現在の価値に割り引いて評価されます。これは、将来の出来事の不確実性を反映しています。
このように、エージェントは試行錯誤とQ値の更新を繰り返すことで、徐々に最適な行動戦略を学習していきます。最終的には、あらゆる状況で最大の報酬が得られる行動を、迷わず選択できるようになることを目指します。
Q学習

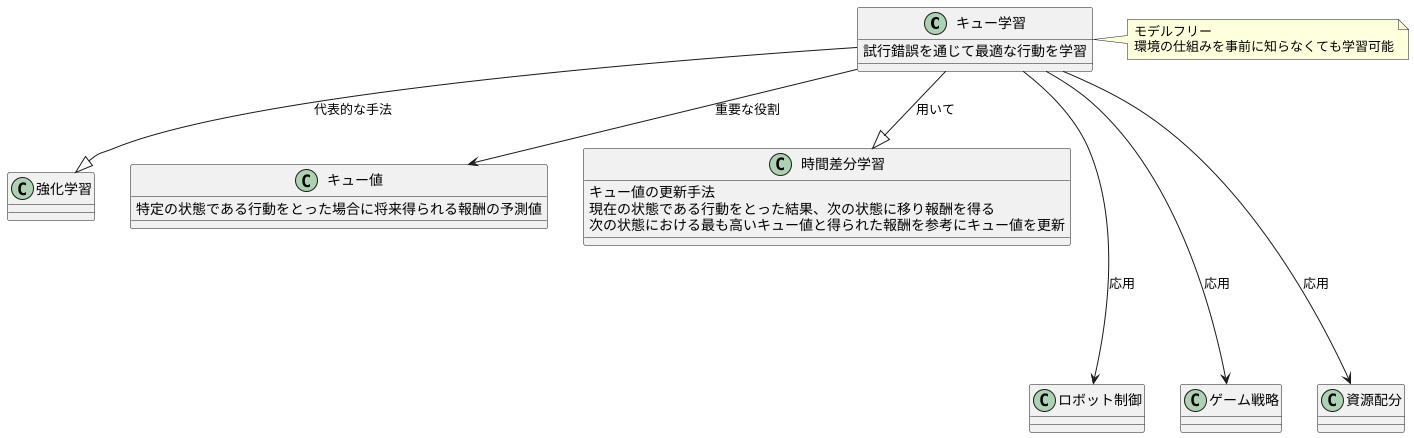
「キュー学習」は、機械が試行錯誤を通じて最適な行動を学習する、強化学習の代表的な手法の一つです。この学習方法では、「キュー値」と呼ばれる数値が重要な役割を果たします。キュー値は、特定の状態において、ある行動をとった場合に将来どれだけの報酬が得られるかを予測した値です。この値が大きいほど、その行動は良い行動であると判断されます。
キュー学習では、「時間差分学習」という手法を用いてキュー値を更新していきます。具体的には、現在の状態である行動をとった結果、次の状態に移り、報酬を得たとします。この時、現在の状態における行動のキュー値は、次の状態における最も高いキュー値と、今得られた報酬を参考に更新されます。
例えば、迷路の中でロボットがゴールを目指す場面を想像してみましょう。ロボットは、各交差点で進む方向を選びます。最初はどの道が良いか分からず、ランダムに進みます。ある交差点で右に進むと、次の交差点で行き止まりになり、報酬が得られません。この経験から、ロボットは現在の交差点で右に進む行動のキュー値を下げます。一方、別の交差点で左に進むと、ゴールに近づき、報酬が得られました。この経験から、ロボットは現在の交差点で左に進む行動のキュー値を上げます。
このように、試行錯誤とキュー値の更新を繰り返すことで、ロボットは徐々に最適な行動を学習し、迷路を効率的に解けるようになります。キュー学習の利点は、「モデルフリー」であることです。つまり、迷路の構造(環境の仕組み)を事前に知らなくても学習を進めることができます。そのため、様々な状況に柔軟に対応できる学習方法として、注目されています。また、キュー学習は、ロボット制御だけでなく、ゲーム戦略の学習や、資源配分の最適化など、幅広い分野で応用されています。
Q値の応用

「質」を表す指標であるQ値は、様々な分野で活用され、その範囲は広がり続けています。特に、行動の良し悪しを学習する強化学習においては中心的な役割を果たしており、将来への期待も高まっています。
例えば、近年注目を集めているロボット工学の分野では、Q値を用いた学習を通して、ロボットは周囲の状況に適した行動を自ら学ぶことが可能です。障害物を避けて目的地まで移動する、物を掴んで指定の場所に置くといった複雑な動作も、試行錯誤を通じて最適な行動を習得していくことができます。従来のように、一つ一つの動作を人間が細かく指示する必要がなくなり、ロボットの自律的な行動制御を実現できるのです。
また、娯楽分野におけるゲーム開発においても、Q値は重要な役割を担っています。ゲームに登場するキャラクターは、Q値を用いた学習によって、状況に応じた最適な戦略を自ら編み出すことができます。敵の攻撃を避けつつ効果的な攻撃を行う、味方と協力して任務を遂行するといった高度な判断も、Q値に基づいた学習によって可能になります。これにより、より人間に近い知能を持った、リアルで魅力的なキャラクターを作り出すことができるのです。
さらに、医療の分野でもQ値の応用が始まっています。患者の容態は一人ひとり異なり、最適な治療法も様々です。Q値を用いた学習は、個々の患者の状態に合わせて、最も効果的な治療方針を導き出すことを可能にします。薬の量や投与方法、手術の時期などを最適化することで、治療効果の向上や副作用の軽減が期待されます。
このように、Q値は様々な分野で応用され、私たちの生活をより豊かに、より便利にする可能性を秘めた技術と言えるでしょう。今後、更なる研究開発が進むことで、Q値の応用範囲はますます広がっていくと考えられます。
| 分野 | Q値の活用例 | 効果 |
|---|---|---|
| ロボット工学 | 障害物回避、物体操作 | 自律的な行動制御 |
| ゲーム開発 | キャラクターの行動戦略 | リアルで知的なキャラクター |
| 医療 | 最適な治療方針の決定 | 治療効果向上、副作用軽減 |
まとめ

強化学習とは、試行錯誤を通じて行動の価値を学習し、最適な行動を見つけるための枠組みです。この学習の中核を担うのが「行動価値関数」、通称Q値です。Q値は、ある状況で特定の行動をとった場合に、将来にどれだけの報酬が得られるかを予測した数値です。言いかえると、それぞれの行動の良し悪しを評価する指標と言えるでしょう。
Q値を最大化することを目指すことで、学習する主体であるエージェントは、環境の中で最も効果的な行動を選択できるようになります。例えば、ロボットが迷路を探索する場面を考えてみましょう。それぞれの分岐点で、右に進む、左に進む、まっすぐ進むといった選択肢があります。各選択肢に対応するQ値を学習することで、ロボットはゴールにたどり着くための最短経路を見つけ出すことができるのです。
Q値を学習するための代表的な手法として、Q学習が挙げられます。Q学習は、エージェントが実際に環境と相互作用しながら、試行錯誤を通じてQ値を更新していくアルゴリズムです。経験を通して得られた報酬をもとに、Q値の推定値を徐々に正確な値に近づけていきます。
近年、Q学習以外にも様々なQ値学習アルゴリズムが開発され、ロボットの制御、ゲームをプレイする人工知能、医療診断支援など、幅広い分野で応用されています。例えば、工場のロボットアームの動きを最適化したり、囲碁や将棋で人間を凌駕するAIを開発したり、患者の状態に合わせて最適な治療方針を決定するシステムなどが実現されています。
Q値は強化学習を理解する上で欠かせない概念であり、今後の更なる発展が期待される重要な研究分野です。より複雑な状況における意思決定を自動化するために、Q値の研究はますます重要性を増していくでしょう。今後、Q値の研究が進むことで、私たちの生活はより便利で豊かなものになっていくと考えられます。
| 用語 | 説明 | 例 |
|---|---|---|
| 強化学習 | 試行錯誤を通じて行動の価値を学習し、最適な行動を見つけるための枠組み | ロボットの迷路探索、ゲームAI、医療診断支援 |
| 行動価値関数(Q値) | ある状況で特定の行動をとった場合に、将来にどれだけの報酬が得られるかを予測した数値。行動の良し悪しを評価する指標。 | 迷路の分岐点で、右、左、まっすぐ進む選択肢それぞれに対応するQ値 |
| Q学習 | エージェントが実際に環境と相互作用しながら、試行錯誤を通じてQ値を更新していくアルゴリズム | – |