
ラベルなしデータで学ぶAI

AIを知りたい
「自己教師あり学習」と「教師なし学習」って、どちらもデータにラベルが付いていない状態で学習するんですよね?違いがよくわからないのですが…

AIエンジニア
良い質問ですね。どちらもラベルなしデータを使う点は同じですが、学習の仕方が違います。自己教師あり学習は、データ自身から「擬似的なラベル」を作って学習します。例えば、ジグソーパズルのように画像をバラバラにして、元の画像を復元する訓練をさせることで、画像の特徴を学習させるといった方法です。
AIを知りたい
なるほど!つまり、自分で問題と答えを作って学習しているんですね。では、教師なし学習はどうやって学習するのですか?
AIエンジニア
教師なし学習は、データの中に隠れている構造やパターンを見つけ出すことを目的としています。例えば、顧客データを分析して、いくつかのグループに分類する、といったことを行います。この時、あらかじめグループ分けの基準(ラベル)は与えられません。データの特徴から、似たもの同士を自動的にグループ化するのです。
Self-Supervised and Unsupervised Learningとは。
人工知能の言葉で「自己教師あり学習」と「教師なし学習」というものがあります。これは、人間が答えを教える「教師あり学習」とは違います。「教師あり学習」では、答え付きのデータが少ないと人工知能の学習が進まないことがあります。一方、「自己教師あり学習」では、答えのないデータから学習課題を自分で作ることができます。データの中にある本来の構造や模様を利用して、同じデータの一部を予測したり、作り出したりします。例えば、「画像修復」では、周りの点の情報をもとに、画像の欠けている部分を補うことができます。さらに進んだ「教師なし学習」では、はっきりとした答えや目標を使わずに、データの模様や構造のグループを見つけられるように人工知能に学習させます。そうすることで、隠れた知識を得ることを助けます。これは、異常なデータを見つける技術などの土台となっています。
ラベル付きデータの課題

人工知能の学習には、大量のデータが必要です。しかし、ただデータを集めるだけでは不十分で、それぞれのデータに何が写っているか、どんな内容かを説明するラベルが必要です。例えば、猫の画像を人工知能に学習させるには、その画像に「猫」というラベルを付ける必要があります。このラベルが付いていることで、人工知能は画像を見てそれが猫だと理解し、学習を進めることができます。
しかし、このラベル付け作業が大きな課題となっています。膨大な量のデータを一つ一つ人手でラベル付けしていくのは、大変な手間と時間、そして費用がかかります。特に、近年の人工知能ブームで必要とされるデータ量は爆発的に増加しており、従来の方法ではとても追いつきません。このラベル付け作業の負担が、人工知能開発の速度を妨げる大きな要因、ボトルネックとなっています。
ラベル付きデータの不足は、特に新しい分野やニッチな分野で深刻です。例えば、珍しい病気の診断支援を行う人工知能を開発しようとした場合、その病気に該当する画像データはそもそも数が少なく、さらにその少ないデータに医師がラベルを付ける作業は非常に負担が大きいため、十分な量のラベル付きデータを集めることが困難になります。データ不足は人工知能の精度低下に直結するため、結果として精度の高い人工知能モデルを開発することが難しくなります。
こうした背景から、ラベルの付いていないデータ、つまりラベルなしデータを使って学習できる人工知能技術の開発が重要視されています。ラベルなしデータはラベル付きデータに比べて大量に存在するため、もしラベルなしデータで効率的に学習できるようになれば、人工知能開発の大きな進歩につながると期待されています。様々な研究機関や企業が、ラベルなしデータの活用方法について活発に研究開発を進めています。
| 項目 | 説明 |
|---|---|
| 人工知能の学習データ | 大量のデータとラベルが必要 |
| ラベル | データの内容を説明する情報(例:猫の画像に「猫」というラベル) |
| ラベル付け作業の課題 | 人手で行うには手間、時間、費用がかかり、AI開発のボトルネックとなっている |
| ラベル付きデータ不足の影響 | 特に新しい分野やニッチな分野で深刻。AIの精度低下につながる |
| ラベルなしデータの活用 | ラベルなしデータで学習できるAI技術の開発が重要視されている |
| ラベルなしデータのメリット | ラベル付きデータより大量に存在し、活用できればAI開発の大きな進歩につながる |
自己教師あり学習の概要

自己教師あり学習は、データにラベルが付けられていない状況でも、機械学習モデルを訓練できる強力な手法です。データ自身に内在する情報や構造を利用して、学習のための擬似的なラベルを自動的に生成する点が特徴です。言ってみれば、教師なし学習でありながら、教師あり学習のように振る舞うことができる、画期的な学習方法と言えます。
具体的には、入力データの一部を意図的に欠損させたり、変換を加えたりすることで、予測問題を作り出します。例えば、画像の場合、画像の一部をマスクで覆い隠します。そして、モデルには隠された部分の内容を予測させるタスクを与えます。隠された部分を正確に予測するためには、モデルは画像全体の文脈や特徴を理解する必要があり、この過程を通じて画像に関する知識を獲得していくのです。文章の場合も同様に、文中の単語をマスクし、その単語を予測させることで、モデルは単語の意味や文脈、文章全体の構造を学習します。
自己教師あり学習の利点は、大量のラベル付きデータが必要ないという点です。ラベル付け作業は、多くの時間と費用を要するため、ラベルなしデータを用いて学習できる自己教師あり学習は、実用面で大きなメリットがあります。また、ラベル付きデータでは学習できないような、データに内在する複雑な構造や特徴を捉えることができる可能性も秘めています。
この手法は、画像認識や自然言語処理といった様々な分野で応用されています。画像認識では、前述のように画像の一部を隠して予測させることで、画像の特徴表現を学習し、物体認識や画像分類などのタスクに利用できます。自然言語処理では、単語の予測だけでなく、文章の順序を予測させたり、文章が類似しているかどうかを判断させるタスクも用いられます。このように、様々なタスク設定を通じて、高精度な言語モデルの構築が可能になります。自己教師あり学習は、今後の機械学習の発展において、重要な役割を担うことが期待されています。
| 項目 | 説明 |
|---|---|
| 定義 | ラベルなしデータで訓練可能な機械学習手法。データ自身から擬似的なラベルを生成し、教師あり学習のように学習を行う。 |
| 学習方法 | 入力データの一部をマスク・変換し、予測問題を作成。例えば、画像の一部を隠し、隠された部分を予測させることで、画像全体の文脈や特徴を学習する。 |
| 利点 |
|
| 応用分野 |
|
| 将来性 | 今後の機械学習の発展において重要な役割を担うと期待されている。 |
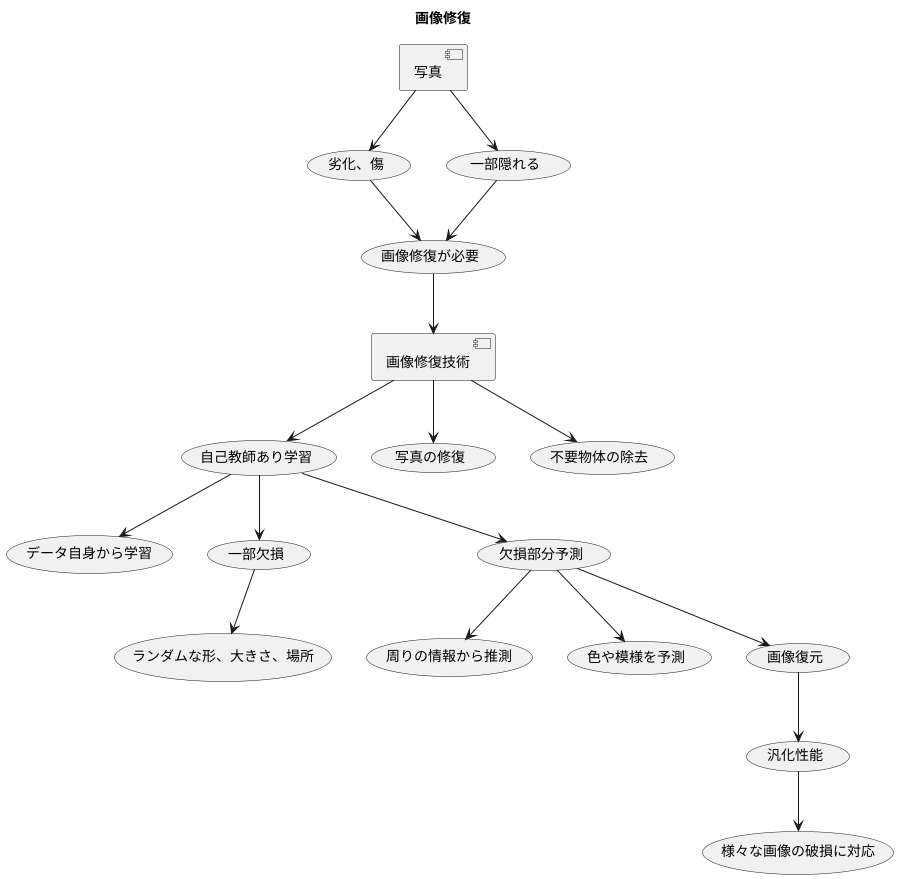
画像修復の例

写真は時とともに劣化したり、傷ついてしまったりすることがあります。また、意図せず写真の一部が隠れてしまうこともあるでしょう。このような写真の破損部分を自然に復元する技術が画像修復です。画像修復は、機械学習の一種である自己教師あり学習を用いて実現されています。自己教師あり学習とは、データ自身に含まれる情報から学習を行う方法です。具体的には、完全な写真の一部をわざと欠損させ、その欠損部分を予測させることでモデルを学習させます。
例えば、可愛い猫の写真で考えてみましょう。猫の顔の一部を四角く隠します。この隠された部分を、モデルに予測させて復元させるのです。モデルは、隠されていない周りの部分、例えば猫のひげや目の形、毛並みなどを見て、隠された部分が耳の先なのか、鼻の一部なのかを推測します。そして、その部分にふさわしい色や模様を予測し、画像を復元しようとします。この作業を繰り返すことで、モデルは猫の顔の特徴、つまり耳や鼻、ひげといった要素がどのように配置され、どのような色や模様をしているのかを学習していきます。まるで絵を描くのが上手になるように、猫の絵の描き方を覚えていくのです。
学習の際には、隠す部分の形や大きさ、場所を毎回ランダムに変えることが重要です。円形に隠したり、細長く隠したり、様々なパターンで隠すことで、多様な状況に対応できるようになります。様々な練習問題を解くことで、応用力が身につくのと同じです。このようにして、モデルは特定の状況だけでなく、様々な画像の破損に対応できる汎化性能を獲得していくのです。こうして鍛えられた画像修復技術は、古くなった写真の修復や、不要な物体が写り込んだ写真の修正など、様々な場面で活用されています。まるで魔法のように、傷ついた写真を美しく蘇らせる技術と言えるでしょう。
教師なし学習の進化

人が教えなくても自ら学ぶ、それが教師なし学習です。まるで職人のように、ラベルのない生のデータを渡されるだけで、隠れた規則や繋がりを見つけ出すことができます。これは、先生役のデータが必要な教師あり学習とは大きく異なる点です。
教師なし学習の活躍の場は実に様々です。例えば、ある商店の顧客情報を分析したいとします。教師なし学習を使えば、購買履歴に基づいて顧客をグループ分けすることができます。特売品ばかり買うグループ、新製品を好むグループなど、データの背後にある特徴を捉えて分類します。また、普段と異なる行動をする顧客、例えば、いつもと違う商品を大量に購入する顧客を異常として見つけることもできます。これは不正利用の検知などに役立ちます。
教師なし学習は、データの山を分かりやすく図表にするデータの可視化や、データから価値ある知識を掘り出すデータマイニングといった作業にも利用されています。最近では、人間の脳を模倣した深層学習の技術が発展し、教師なし学習の精度も飛躍的に向上しました。膨大なデータが集まる時代だからこそ、教師なし学習は力を発揮するのです。インターネット上の膨大な情報、医療現場で集まる検査データ、工場のセンサーデータなど、活用の可能性は無限に広がっています。今後、様々な分野で、教師なし学習が革新をもたらすでしょう。
| 教師なし学習 | 説明 | 例 |
|---|---|---|
| 概要 | ラベルのないデータから隠れた規則や繋がりを見つけ出す学習方法。 | – |
| 顧客分析 | 購買履歴に基づいて顧客をグループ分けする。 | 特売品志向グループ、新製品志向グループなど |
| 異常検知 | いつもと異なる行動をする顧客を見つける。 | 不正利用検知 |
| データの可視化 | データを分かりやすい図表にする。 | – |
| データマイニング | データから価値ある知識を掘り出す。 | – |
| 深層学習との関係 | 深層学習技術の発展により精度が向上。 | – |
| 活用分野 | インターネット、医療、工場など、膨大なデータが存在する分野。 | – |
異常検出への応用

異常検知は、教師なし学習と呼ばれる手法の大切な活用例の一つです。普段と変わらないデータの特徴を学ぶことで、そこから外れた異常なデータを発見することができます。これは、まるでいつもと違う様子を見つけるようなものです。
例えば、クレジットカードの不正利用を想像してみてください。普段の買い物とは異なる金額や場所での利用があった場合、システムはそれを異常と判断し、利用者に警告を発します。これは、過去の利用履歴という正常なデータから学習した結果です。また、工場では、機械の振動や温度などのセンサーデータから、故障の前兆となる異常な変化を検知することができます。普段の稼働状態を学習することで、わずかな異変も見逃さずに捉え、故障を未然に防ぐことができるのです。その他にも、ネットワークへの不正アクセスやサーバーの異常動作の検知など、様々な場面で異常検知は役立っています。
異常検知の仕組みは、正常なデータから得られた特徴に基づいて、新しいデータがどれくらいその特徴に合致するのかを判断するというものです。もし、新しいデータが正常なデータの特徴から大きく外れている場合、それは異常と判定されます。この判断基準は、正常なデータのばらつき具合を考慮して決められます。あまりに厳しくしすぎると、正常なデータも異常と判定されてしまう可能性があり、逆に甘すぎると異常を見逃してしまう可能性があります。
近年では、深層学習と呼ばれる技術を用いた異常検知の手法も開発されています。深層学習は、複雑なデータの特徴を捉える能力が高いため、従来の手法よりも高い精度で異常を検知できる可能性を秘めています。これにより、これまで見つけるのが難しかった、より巧妙な異常も見つけられるようになると期待されています。異常検知は、安全管理や品質向上、不正防止など、様々な分野で欠かせない技術となっており、今後ますます発展していくと考えられます。
| 活用例 | 説明 |
|---|---|
| クレジットカードの不正利用検知 | 普段の買い物とは異なる金額や場所での利用を異常と判断し、利用者に警告。 |
| 工場における故障予知 | 機械の振動や温度などのセンサーデータから、故障の前兆となる異常な変化を検知。 |
| ネットワーク不正アクセス検知 | ネットワークへの不正アクセスを検知。 |
| サーバー異常動作検知 | サーバーの異常動作を検知。 |
| 異常検知の仕組み | 説明 |
|---|---|
| 正常データ学習 | 正常なデータから特徴を学習。 |
| 新規データ評価 | 新しいデータが正常データの特徴に合致するかどうかを判断。 |
| 異常判定 | 新規データが正常データの特徴から大きく外れている場合、異常と判定。 |
| 技術動向 | 説明 |
|---|---|
| 深層学習の活用 | 複雑なデータの特徴を捉え、高い精度で異常を検知。 |
将来の展望

データにラベルを付ける作業は、手間と費用がかかる大変な作業です。例えば、画像認識の学習には、一枚一枚の画像に「猫」「犬」などのラベルを付ける必要があります。膨大な数の画像にラベルを付けるのは大変な作業です。しかし、自己教師あり学習や教師なし学習といった技術は、ラベル付きデータが少なくても、あるいは全くなくても学習できるという、画期的な学習方法です。これらの技術は、ラベル付けのコストを大幅に削減し、人工知能の研究開発を加速させる可能性を秘めています。
自己教師あり学習では、データの一部を隠したり、変化させたりすることで、データ自身に含まれる情報から学習を行います。例えば、画像の一部を隠して、隠された部分を予測させることで、画像の全体像を学習することができます。教師なし学習では、データの構造やパターンを自動的に学習します。例えば、大量の文章を読み込ませることで、言葉の意味や文法を理解することができます。これらの技術は、深層学習という、人間の脳の神経回路を模倣した学習モデルと組み合わせることで、さらに強力なものとなります。
将来的には、これらの技術によって、動画の理解やロボットの制御など、より複雑な作業を人工知能が行えるようになると期待されています。動画の理解では、動画の内容を自動的に要約したり、登場人物の行動を予測したりすることができるようになるでしょう。ロボットの制御では、複雑な環境でも、自律的に行動できるロボットの開発につながると期待されます。また、これらの技術は、人間には見つけることができない、隠れた規則性や知識を発見する可能性も秘めています。これは、科学的な発見や、ビジネスにおける新しい知見の獲得につながる可能性があります。自己教師あり学習や教師なし学習は、今後の人工知能の発展を大きく支える、重要な技術となるでしょう。
| 学習方法 | 説明 | 例 | 将来的な応用 |
|---|---|---|---|
| 自己教師あり学習 | データの一部を隠したり、変化させたりすることで、データ自身に含まれる情報から学習を行う。 | 画像の一部を隠して、隠された部分を予測させることで、画像の全体像を学習する。 | 動画の理解(内容の自動要約、登場人物の行動予測)、ロボットの制御(複雑な環境での自律的な行動) |
| 教師なし学習 | データの構造やパターンを自動的に学習する。 | 大量の文章を読み込ませることで、言葉の意味や文法を理解する。 | 隠れた規則性や知識の発見(科学的な発見、ビジネスにおける新しい知見の獲得) |