
逆強化学習:熟練者の技を学ぶAI

AIを知りたい
先生、『逆強化学習』って、普通の強化学習と何が違うんですか?どちらも何かを学習させるんですよね?

AIエンジニア
いい質問だね。普通の強化学習は、目的(例えばゲームの得点)が最初に決まっていて、それを達成するための行動をコンピュータに学習させるんだ。逆強化学習は、上手な人の行動を見て、その人が何を目的として行動しているのかをコンピュータに推測させるんだよ。
AIを知りたい
つまり、上手な人の『目的』がわからないけど、『行動』は見えているから、その目的を推測するってことですか?
AIエンジニア
その通り!例えば、自転車に乗るの上手な人の動きをコンピュータに記録させて、その人が『転ばないこと』を目的としているのか、『速く走る事』を目的としているのかを推測させる。そして、最終的にはその上手な人よりも上手に自転車に乗れるように行動を導き出すのが逆強化学習なんだ。
逆強化学習とは。
人工知能の分野で使われる「逆強化学習」という言葉について説明します。これは、機械学習の一種で、上手な人のやり方を見て、その人が何を目標にしているのかを推測し、その人よりもさらに良いやり方を見つける方法です。
はじめに

人間のように考え、行動する機械の実現は、人工知能研究における大きな目標です。その中で、人の優れた技を機械に習得させる技術が注目を集めています。それが「逆強化学習」と呼ばれる手法です。
従来の機械学習では、あらかじめ「どのような結果を目指すべきか」をはっきりさせる必要がありました。例えば、犬と猫を見分ける学習をするなら、「犬の写真を見せたら『犬』と答える」という目標を機械に与える必要があったのです。しかし、現実世界の問題はもっと複雑です。囲碁や将棋のようなゲームでさえ、必ずしも勝ち負けだけが全てではありません。「美しい棋譜」や「相手を翻弄する戦略」など、様々な目標が考えられます。ましてや、運転や料理、芸術活動など、明確な正解のない課題においては、従来の学習方法では対応が難しいと言えるでしょう。
そこで登場するのが逆強化学習です。この手法は、熟練者の行動を注意深く観察し、そこからその人が何を目標としているのかを推測するというアプローチを取ります。例えば、熟練した料理人の動きを記録し、その一連の動作から「美味しい料理を作る」「手際よく作業を進める」「食材を無駄なく使う」といった複数の目標を推定します。そして、推定した目標に基づいて機械が学習することで、熟練者に匹敵、あるいは凌駕するパフォーマンスを発揮できるようになるのです。
このように、逆強化学習は、明確な目標設定が難しい複雑な課題を解決するための、強力な手法として期待されています。将来的には、様々な分野での応用が期待されており、人工知能技術の発展に大きく貢献するものと考えられています。
| 手法 | 説明 | 課題 | 利点 |
|---|---|---|---|
| 従来の機械学習 | あらかじめ結果を定義する必要がある。例えば、犬の写真を見せたら「犬」と答える、といった具合。 | 現実世界の複雑な問題、明確な正解のない課題への対応が難しい。 | – |
| 逆強化学習 | 熟練者の行動を観察し、目標を推測する。例えば、料理人の動きから「美味しい料理を作る」「手際よく作業を進める」といった目標を推定。 | – | 明確な目標設定が難しい複雑な課題を解決できる。 |
手法の概要

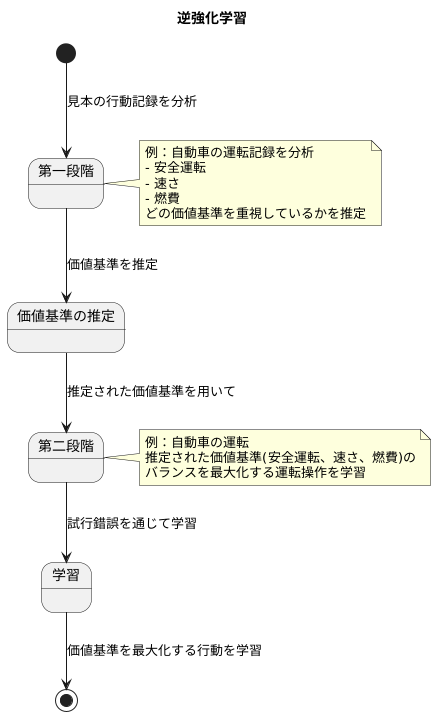
逆強化学習は、見本の行動記録から、その行動を生み出すもととなった価値基準を推定し、その価値基準を基に学習する手法です。これは二つの段階に分けて行われます。
第一段階では、見本の行動記録を分析し、どのような価値基準を最も重視しているかを推定します。例えば、自動車の運転記録を分析する場合、安全運転を重視しているのか、速さを重視しているのか、燃費を重視しているのかといった価値基準を推定します。この推定作業は、見本の行動が、どのような価値基準に基づいて選択されたかを解き明かす作業と言えます。見本の行動は、単に運転操作の記録だけでなく、どのような状況でどのような行動を選んだのかという、状況と行動の組み合わせの記録です。この記録から、どのような価値基準を最大化しようとすれば、このような行動記録になるのかを推定します。この推定された価値基準は、見本の意図や目的を反映したものであると考えられます。
第二段階では、推定された価値基準を用いて、学習を行います。学習者は、試行錯誤を通じて、価値基準を最大化する行動を学習します。自動車の運転の例で言えば、第一段階で推定された「安全運転」「速さ」「燃費」といった価値基準のバランスを最大化するように、運転操作を学習します。この学習は、単に見本の運転操作を真似るのではなく、与えられた価値基準に基づいて、より良い運転方法を探索する試行錯誤の過程です。これにより、学習者は見本の行動を模倣するだけでなく、さらに状況に合わせた最適な行動を学習し、見本を超える成果を上げることも可能になります。つまり、逆強化学習は、見本の行動を単に模倣するのではなく、見本の行動原理を理解し、それを基により優れた行動を学習する手法と言えます。
強化学習との違い

強化学習と逆強化学習は、一見似た技術に思えますが、その学習目的と手法は大きく異なります。どちらも、学習する主体であるエージェントが環境と関わり合いながら学習を進めるという点は共通しています。しかし、両者の大きな違いは、報酬をどのように扱うかという点にあります。
強化学習では、設計者が予め報酬の仕組みを決めておきます。例えば、ロボットに物を掴ませる学習の場合、「物を掴む」という行動に高い報酬を与えます。エージェントは、このあらかじめ設定された報酬をより多く得るために、試行錯誤を繰り返しながら最適な行動を学習します。つまり、強化学習は「どのようにすれば報酬を最大化できるか」、言い換えれば「どのように行動すれば良いか」を学ぶ学習方法と言えます。
一方、逆強化学習では、報酬の仕組みは未知です。その代わりに、熟練者の行動データを利用します。例えば、熟練の職人さんがどのように道具を扱うかを観察し、そのデータから職人の行動原理、すなわち「何を目標としているか」を推定します。この推定された目標が、逆強化学習における報酬関数となります。そして、エージェントはこの推定された報酬関数を基に、熟練者と同じように行動できるよう学習します。つまり、逆強化学習は「熟練者は何を目標として行動しているのか」を学ぶ学習方法と言えます。
このように、強化学習は「どのように行動するか」を学ぶのに対し、逆強化学習は「何を目標とするか」を学ぶという大きな違いがあります。この違いによって、逆強化学習は、目標設定が難しい複雑な作業を学習させる際に特に有効です。熟練者の行動を観察することで、複雑な目標を自動的に設定できるからです。これは、強化学習では設計者が報酬関数を綿密に設計する必要があるのと対照的です。
| 項目 | 強化学習 | 逆強化学習 |
|---|---|---|
| 学習目的 | どのように行動すれば良いかを学ぶ (報酬最大化) | 熟練者は何を目標として行動しているかを学ぶ |
| 報酬 | 設計者が予め設定 | 未知 (熟練者の行動データから推定) |
| 入力 | 報酬関数 | 熟練者の行動データ |
| 出力 | 最適な行動 | 報酬関数、熟練者の行動を模倣する方策 |
| 適用例 | ロボット制御、ゲームAI | 複雑な作業の学習、熟練者の行動分析 |
応用例

逆強化学習は、様々な分野での応用が期待される、注目を集めている技術です。その活用範囲は広く、私たちの生活を大きく変える可能性を秘めています。
自動運転の分野では、熟練した運転手の運転データを基に、安全で効率の良い運転方法を学習させることができます。例えば、急ブレーキや急ハンドルといった危険な操作を避けつつ、スムーズな加減速や車線変更を行う方法を、機械に自動的に習得させることが可能になります。これにより、交通事故の減少や渋滞の緩和といった効果が期待されます。
ロボット制御の分野においても、熟練作業者の動作データを活用することで、複雑な作業を自動化するための制御方法を生み出すことができます。これまで人間の手で行われてきた精密な組立作業や、複雑な動きを必要とする作業なども、ロボットが正確に再現できるようになる可能性があります。これにより、生産性の向上や人手不足の解消に繋がるでしょう。
医療の分野では、医師の診断データを用いて、病気の診断を支援する仕組みを作ることも考えられます。経験豊富な医師の膨大な診断記録を学習させることで、様々な症状から病気を特定する精度を高めることが期待されます。また、新しい治療法の開発や、個々の患者に最適な治療計画の立案にも役立つ可能性があります。
さらに、ゲームの分野でも、熟練プレイヤーの操作データから、高度な戦略や戦術を学習させることができます。これにより、より人間に近い思考を持つ、強力な人工知能の開発が可能になるでしょう。
このように、逆強化学習は、人間の持つ高度な技能や知識を機械に学習させるための強力な手段として、様々な分野で活用が期待されています。今後、更なる研究開発が進めば、私たちの社会をより豊かに、より便利にする技術として、ますます重要な役割を果たしていくと考えられます。
| 分野 | 活用例 | 期待される効果 |
|---|---|---|
| 自動運転 | 熟練運転手のデータから安全で効率的な運転方法を学習 | 交通事故の減少、渋滞の緩和 |
| ロボット制御 | 熟練作業者のデータから複雑な作業の自動化 | 生産性の向上、人手不足の解消 |
| 医療 | 医師の診断データから病気の診断支援 | 診断精度の向上、新治療法の開発、最適な治療計画の立案 |
| ゲーム | 熟練プレイヤーのデータから高度な戦略・戦術を学習 | 人間に近い思考を持つAIの開発 |
課題と展望

人の熟練した技を機械に教え込む技術である逆強化学習は、大きな可能性を秘めていますが、いくつかの難題も抱えています。まず、熟練者の行動データを集めることが難しい場合があります。熟練者の行動は限られた状況でしか見られない場合もあり、また十分な量のデータを集めることができない場合も少なくありません。さらに、集めたデータに誤りや雑音が多いと、正確な学習ができません。人の行動は常に完璧ではなく、機械に教えるためには不要な情報を取り除く必要がありますが、これが難しい場合があります。
次に、理想的な報酬の与え方を推定することが困難です。逆強化学習では、熟練者の行動から、どのような状況でどのような行動に高い報酬が与えられるべきかを推測します。しかし、同じ行動でも状況によって報酬が変わる場合があり、複雑な状況では適切な報酬を推定することが難しくなります。この報酬の推定には膨大な計算が必要となる場合もあり、大規模な問題を扱う際には時間と資源が不足してしまう可能性があります。
しかし、これらの難題を克服するための研究も活発に行われています。より効率的に計算を行う方法や、雑音に強い学習方法の開発が進んでいます。これらの研究成果によって、より多くの場面で逆強化学習が活用できるようになると期待されています。例えば、ロボットの制御や自動運転技術、さらには医療や金融など、様々な分野への応用が考えられます。今後、逆強化学習は、より高度な人工知能を実現するための重要な技術となるでしょう。
| 課題 | 詳細 |
|---|---|
| 熟練者の行動データ収集の難しさ |
|
| 理想的な報酬の与え方の推定の難しさ |
|
まとめ

人間がどのように行動を決定しているのか、その背後にある思考や目的を理解することは、人工知能の開発において長年の課題でした。逆強化学習は、この難題に挑む強力な手法として注目を集めています。従来の強化学習では、あらかじめ明確な目標(報酬)を設定する必要がありました。しかし、現実世界の複雑な課題を扱う際には、適切な目標を設定すること自体が困難な場合が多くありました。例えば、自動運転で言えば「安全に目的地に到着する」という漠然とした目標を、具体的な数値で表現することは容易ではありません。逆強化学習は、この問題を解決する糸口となります。熟練者の運転データを観察することで、「安全運転とは何か」をデータから学習し、目標を推定することが可能になります。
具体的には、熟練者の運転データから、どのような状況でどのような行動を選択しているのかを分析します。そして、その行動から、熟練者が暗黙的に持っている目標や価値観を推測します。この推測された目標を基に、強化学習の手法を用いて、人工知能エージェントを訓練します。これにより、熟練者のように高度な判断を行い、複雑な状況にも対応できる人工知能を実現することができます。逆強化学習は、自動運転だけでなく、ロボット制御、医療診断、ゲームプレイなど、様々な分野への応用が期待されています。例えば、ロボットに複雑な組み立て作業を教えたい場合、熟練作業者の動きをデータ化し、逆強化学習を用いることで、ロボットは人間の意図を理解し、効率的な作業手順を習得できます。
もちろん、逆強化学習にも課題は残されています。例えば、大量の熟練者データが必要となる点や、学習に時間がかかる点などが挙げられます。しかし、近年の深層学習技術の進歩と相まって、これらの課題も克服されつつあります。今後、逆強化学習は、人間と機械の協調を促進し、人間の知能の理解を深めるためにも、重要な役割を担っていくと考えられます。人間の持つ暗黙知を形式知に変換する技術としても期待されており、様々な分野での革新につながる可能性を秘めています。