
サポートベクターマシン入門

AIを知りたい
『サポートベクターマシン』って、二つのデータの集まりを分ける線を引くんですよね?よくわかりません。もっと簡単に説明してもらえますか?

AIエンジニア
そうだね。たとえば、猫と犬の写真を分けることを考えてみよう。サポートベクターマシンは、猫と犬の写真の間に線を引いて、どちら側にあるかで写真が猫か犬かを判断するんだよ。
AIを知りたい
猫と犬の間の線…なんとなくわかります。でも、その線はどこに引けばいいんですか?
AIエンジニア
良い質問だね!サポートベクターマシンは、猫と犬のグループそれぞれに一番近い写真を見つける。そして、その写真と線の間の距離を最大にするように線を引くんだ。こうすることで、新しい写真が来ても、より正確に猫か犬かを判断できるようになるんだよ。
サポートベクターマシンとは。
人工知能の分野でよく使われる『サポートベクターマシン』について説明します。サポートベクターマシンとは、データの集まりを二つに分ける線または面を見つけることで、データの分類や予測を行う方法です。この方法は、境界線に最も近いデータ(サポートベクトル)と境界線との間の距離(マージン)を最大にするという考え方に基づいています。マージンを最大にすることで、新しいデータが追加された場合でも、より正確に分類できるようになります。サポートベクターマシンの詳しい説明と、実際に動かせるPythonのプログラムは、下のリンク先に掲載されています。より深く理解したい方は、ぜひご覧ください。
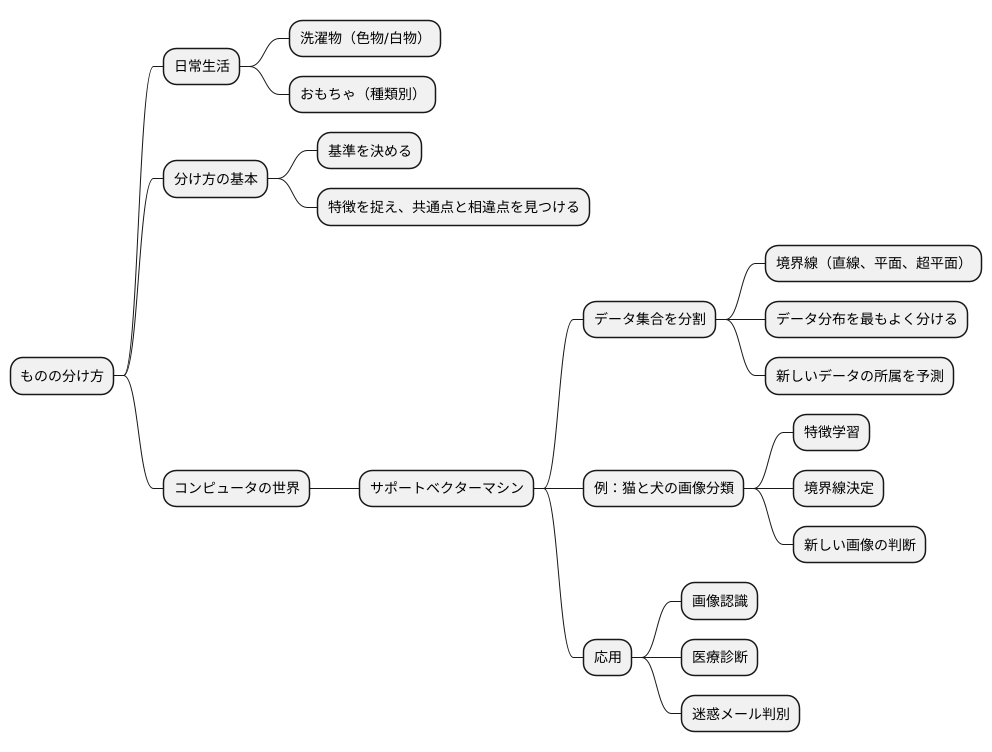
分け方の基礎

ものを分けるということは、私たちの日常に深く根付いています。例えば、洗濯物を色物と白いものに分ける、おもちゃを種類ごとに整理する、といった行動は、無意識のうちにものごとの特徴を捉え、適切な基準で分類していると言えるでしょう。分け方の基本は、まず何を基準に分けるかを決めることです。基準が明確であれば、迷うことなく作業を進めることができます。基準を決めたら、次にそれぞれのグループに属するものの特徴を捉え、共通点と相違点を見つけ出すことが重要です。
コンピュータの世界でも、この分け方の考え方は活用されています。例えば、大量のデータから特定の特徴を持つものを選び出す「サポートベクターマシン」という手法があります。これは、データの集合をまるで二つの陣地に分け隔てるかのように、境界線を引く技術です。データが二次元であれば直線、三次元であれば平面、さらに高次元になれば超平面と呼ばれる境界線を引きます。この境界線は、データの分布を最もよく分けるように計算されます。この境界線を適切な位置に配置することで、新しいデータがどちらの陣営に属するかを正確に予測することが目的です。
例えば、猫と犬の画像を分類する場合を考えてみましょう。サポートベクターマシンは、あらかじめ与えられた猫と犬の画像の特徴を学習し、猫の画像のグループと犬の画像のグループを分ける境界線を導き出します。そして、新しい画像が提示されたとき、その画像の特徴を基に、境界線のどちら側に位置するかによって、猫か犬かを判断します。この技術は、画像認識だけでなく、医療診断や迷惑メールの判別など、様々な分野で応用されています。このように、ものごとの特徴を捉え、適切な基準で分類する考え方は、私たちの生活から高度な情報処理技術まで、幅広く活用されているのです。
境界線とデータの関係

分け隔てる線と情報の繋がりについて説明します。分け隔てる線を引くとき、どこに線を引くのが良いか、迷うことがあります。例えば、黒い点と白い点を分ける線を引くとき、様々な線が考えられます。しかし、分け隔てる線と、その線に最も近い点との間の距離、つまり余白を大きく取ることが重要です。この余白のことを「間隔」と呼びます。間隔が大きいほど、新しい情報が追加されたときにも、線がより正確に点を分けることができると考えられます。
分け隔てる線を引く際に、全ての情報が同じように影響するわけではありません。間隔を決める上で重要な役割を果たす情報があります。それは、分け隔てる線に最も近い情報です。これらの情報を「支えとなる情報」と呼びます。支えとなる情報は、分け隔てる線の位置を決める支えとなる重要な情報であり、これらの情報が少しでも動くと、分け隔てる線の位置も変わります。つまり、他の情報は分け隔てる線の決定には影響を与えず、支えとなる情報だけが重要な役割を果たすのです。
例えば、黒い点と白い点を分ける線を引く場面を想像してみましょう。多くの黒い点と白い点がありますが、分け隔てる線に最も近い、ほんの少数の点だけが、線の位置に影響を与えます。これらの点が「支えとなる情報」です。他の点は、たとえ位置が変わっても、分け隔てる線の位置には影響しません。このように、間隔と支えとなる情報は、分け隔てる線を正しく引く上で重要な役割を果たします。新しい情報が追加された場合でも、間隔が大きいほど、そして支えとなる情報が適切に配置されているほど、分け隔てる線は正確に点を分けることができます。
高次元への拡張

現実世界で見られるデータは、複雑に絡み合っていることが多く、単純な直線や平面を用いて分類しようとすると、うまくいかない場合があります。例えば、二次元のグラフ上にプロットされたデータ点が、まるで糸が絡まるように入り組んでいる様子を想像してみてください。このようなデータでは、直線を引いて二つのグループに分けようとしても、どうしても綺麗に分類できません。
このような複雑なデータを扱う際に、サポートベクターマシン(SVM)は「カーネルトリック」と呼ばれる強力な手法を用います。カーネルトリックは、データをより高次元空間へと写像することで、分類の精度を向上させる技術です。二次元のデータであれば三次元、三次元のデータであれば四次元、といった具合に、より多くの情報軸を持つ空間にデータを投影するのです。
二次元平面上に複雑に絡み合っていたデータも、三次元空間に投影することで、まるで絡まった糸を解きほぐすように、データ点同士の距離が明確になることがあります。三次元空間では、二次元では不可能だった平面による分割が可能になり、より正確な分類を実現できるのです。例えるなら、平面の地図上では区別できない建物も、立体模型で見れば高さが異なり、容易に見分けられるようになるのと同じです。
カーネルトリックの巧妙な点は、実際に高次元空間を扱うことなく、高次元空間で計算しているのと同じ効果を得られるところにあります。高次元空間の計算は膨大な計算資源を必要としますが、カーネルトリックは特別な計算方法を用いることで、計算コストを抑えつつ、高次元空間で分類しているのと同等の結果を得られるように工夫されています。これにより、SVMは複雑なデータにも対応できる柔軟性を手に入れ、様々な現実世界の問題に応用できる強力なツールとなっているのです。
線形分離と非線形分離

分け隔てなく物事を仕分けるには、いくつかのやり方があります。分かりやすくするために、人を仕分ける場面を想像してみましょう。まず、整然と並んだ兵隊を二つの組に分けたいとします。この場合は、一本の直線で綺麗に分けられます。これが、線形分離と呼ばれるやり方です。データが直線や平面で綺麗に分けられる場合に使える、単純で分かりやすい方法です。
一方、入り乱れて動き回る群衆を二つの組に分けたい場合はどうでしょうか。直線を引いても、綺麗に二分することは難しいでしょう。このような複雑な状況では、非線形分離と呼ばれる、もっと工夫を凝らしたやり方が必要になります。このやり方では、人々が持つ様々な特徴(例えば、服装の色や持ち物など)を手がかりに、複雑な曲線を使って仕分けを行います。群衆を上空から見て、異なる色の帽子をかぶった人たちの塊を曲線で囲む様子を想像してみてください。これが、非線形分離のイメージです。
この二つのやり方を、計算機で扱うデータにも応用できます。データを分類する際に、データの散らばり方に応じて、線形分離と非線形分離を使い分けます。線形分離は、データが綺麗に整列している場合に有効です。一方、データが複雑に絡み合っている場合は、非線形分離を用います。非線形分離では「カーネルトリック」と呼ばれる特別な技術を使い、データをより多くの特徴で捉えられるように変換することで、複雑な境界線を引くことができます。まるで、人々を様々な角度から観察して、より細かくグループ分けするかのようです。このように、データの特性に合わせた適切な方法を選ぶことで、より正確に分類できるようになります。
| 分類方法 | 説明 | 例 | データの特性 | その他 |
|---|---|---|---|---|
| 線形分離 | 直線や平面でデータを分ける | 整然と並んだ兵隊を二つの組に分けたい場合 | データが綺麗に整列している場合に有効 | 単純で分かりやすい方法 |
| 非線形分離 | 複雑な曲線でデータを分ける | 入り乱れて動き回る群衆を二つの組に分けたい場合 | データが複雑に絡み合っている場合に有効 | カーネルトリックなどの技術を使用 |
応用分野の広がり

サポートベクトルマシン(SVM)は、データを分類する能力に優れているため、様々な分野で活用されています。その応用範囲は年々広がりを見せ、私たちの生活にも深く関わってきています。
医療分野では、SVMは病気の診断を助ける重要な役割を担っています。例えば、レントゲン写真やCTスキャンなどの画像診断において、SVMは画像データの特徴を学習し、ガンなどの病気を高い精度で判別することができます。早期発見と適切な治療につながるため、医療現場での貢献は計り知れません。また、個々の遺伝子情報を解析し、将来的な病気のリスクを予測する際にも活用されています。これにより、生活習慣の改善や予防医療への意識向上を促す効果が期待されています。
金融分野でも、SVMは欠かせない存在となっています。顧客の信用度を評価し、融資の可否を判断する際に、SVMは過去の取引履歴や収入などのデータに基づいてリスクを予測します。また、クレジットカードの不正利用を瞬時に検知するシステムにもSVMが活用されており、私たちの財産を守る上で重要な役割を果たしています。
さらに、SVMは言葉を扱う分野でも活躍しています。膨大な量の文章データを分類し、それぞれの文書に適切なラベルを付けることができます。例えば、ニュース記事をテーマごとに分類したり、顧客からの問い合わせ内容を自動的に振り分けたりする際に役立ちます。また、迷惑メールを自動的に判別し、受信箱をきれいに保つスパムフィルターにもSVMの技術が応用されています。
このように、SVMは医療、金融、自然言語処理など、多岐にわたる分野で応用されています。データの分類が必要とされるあらゆる場面で活用できるため、今後ますますその重要性が増していくと予想されます。人工知能技術の発展とともに、SVMは私たちの社会をより豊かに、より安全なものへと変えていく力を持っていると言えるでしょう。
| 分野 | 活用例 |
|---|---|
| 医療 | ・画像診断による病気の判別 ・遺伝子情報解析による病気リスク予測 |
| 金融 | ・顧客の信用度評価と融資判断 ・クレジットカード不正利用検知 |
| 自然言語処理 | ・ニュース記事のテーマ分類 ・顧客問い合わせの自動振り分け ・迷惑メール判別(スパムフィルター) |
プログラムによる実装

プログラムを使ってSVMを作ることは、それほど難しくありません。よく使われているプログラム言語の一つであるパイソンを使うと、比較的簡単にSVMを作ることができます。パイソンには、サイキットラーンと呼ばれる便利な道具集まりがあり、この中にSVMを作るための部品がすでに用意されています。少しのプログラムを書くだけで、SVMの模型を組み立て、学習させることができます。まるでプラモデルを組み立てるように、手軽にSVMを利用できるのです。
サイキットラーンには、SVMの模型を作るだけでなく、模型の細かな調整や、出来上がった模型の良し悪しを評価するための道具も揃っています。これにより、SVMを効率よく使うことができるのです。実際にプログラムを動かしてみることで、SVMがどのように動き、どのような特徴を持っているのかを、より深く理解することができます。机の上で教科書を読むだけでなく、実際に手を動かして試してみることで、SVMの仕組みを体で感じることができるのです。
例えば、パイソンを使って作ったSVMのプログラムは、色々な場所で公開されています。インターネットで検索すれば、実際に動くプログラムの例を見つけることができます。これらの例を参考にしながら、自分でプログラムを書いて、実際に動かしてみることで、SVMへの理解をさらに深めることができます。百聞は一見に如かず、実際に動かしてみることで、教科書だけではわからないSVMの奥深さを体感することができるでしょう。
公開されているプログラムは、SVMを学ぶための良い教材となります。プログラムを見ながら、どの部分がどのような役割を果たしているのか、一つずつ確認していくことで、SVMの仕組みをより深く理解することができます。また、プログラムの一部を書き変えて、その結果がどのように変わるのかを試してみることで、SVMの挙動をより具体的に把握することができます。このように、実際にプログラムを動かして試行錯誤することで、SVMに関する知識を深め、より効果的に活用することができるようになります。
| ライブラリ | 言語 | メリット | 学習方法 |
|---|---|---|---|
| scikit-learn | Python | 簡単にSVMを構築、学習、評価できる | 公開されているプログラム例を参考に、実行、改変を通して学習 |