深層強化学習のDQN入門

AIを知りたい
先生、DQNの説明でQテーブルを更新していくってありましたが、具体的にどういうふうに更新するんですか?

AIエンジニア
いい質問だね。Qテーブルの更新には、『Q値の更新式』というものを使うんだ。具体的には、Q(状態, 行動) = Q(状態, 行動) + α * (報酬 + γ * maxQ(次の状態, 全ての行動) – Q(状態, 行動)) という式で更新する。少し複雑に見えるけど、一つずつ見ていこう。
AIを知りたい
式の中に、報酬とか、maxQとか出てきましたけど、これらは何を表しているんですか?
AIエンジニア
報酬は、ある行動をとったときに環境からもらえる値のことだよ。例えば、ゴールに近づけば+1、遠ざかればー1、ゴールに着けば+100といった具合だね。maxQ(次の状態, 全ての行動)は、次の状態で取れる全ての行動の中で、最も高いQ値を持つ行動のQ値を表している。つまり、将来得られるであろう最大の価値を意味するんだ。これらを踏まえて、式全体を見ると、現在のQ値に、行動によって得られた報酬と将来得られるであろう最大の価値を加味して、新しいQ値を計算していることが分かるね。
DQNとは。
ディープマインド社が作った、人工知能の強化学習という種類の計算方法である「ディー・キュー・エヌ」について説明します。
まず、始点をA、終点をIとした道順を想像してみてください。
目標に近づく行動をとると1点加算され、遠ざかる行動をとると1点減点されます。そして、目標に到達すると100点加算されます。
この計算方法では、行動の良し悪しを記録する「Qテーブル」と呼ばれる表を使います。この表は、はじめはすべての値が0になっています。
ディー・キュー・エヌは、このQテーブルの値を繰り返し更新することで学習します。表の中の値が大きいほど、良い行動だと判断するのです。
Qテーブルの値は、決められた計算式を使って更新されます。この計算式には「割引率」と呼ばれる値が含まれています。これは、行動の手数が増えるほど、その行動の価値は低くなるということを考慮するためのものです。
目標への経路探索

目的地まで一番良い道順を探す、ということは、私たちの生活の中にたくさんあります。例えば、地図アプリで最短ルートを探す時や、工場で品物を運ぶロボットの動きを決める時など、様々な場面で道順を探す技術が使われています。このような問題を解くために、試行錯誤しながら学習する「強化学習」という方法が注目を集めています。
強化学習は、まるで迷路の中でゴールを目指すように、機械が周りの状況と関わり合いながら学習する方法です。具体的には、「エージェント」と呼ばれる学習するものが、周りの環境の中でどう動くかを選びます。そして、その結果として得られる「報酬」をもとに、より良い行動を学習していきます。例えば、迷路の例で考えると、エージェントはゴールに辿り着けば報酬をもらえます。逆に、行き止まりにぶつかったり、遠回りしたりすると報酬はもらえません。このように、エージェントは報酬を最大にするように行動を学習していくことで、最終的には迷路のゴール、つまり最適な道順を見つけることができます。
この技術は、自動運転やゲームなど、様々な分野で応用が期待されています。複雑な状況の中で、どのように行動すれば最も良い結果が得られるかを自動的に学習できるため、これまで人間が試行錯誤で解決していた問題を、効率的に解決できる可能性を秘めているのです。例えば、荷物の配送ルートの最適化や、工場の生産ラインの効率化など、私たちの生活をより豊かにするための様々な課題に応用されていくと考えられます。
| 項目 | 説明 |
|---|---|
| 問題 | 目的地までの最適な道順を見つける |
| 例 | 地図アプリの最短ルート検索、工場ロボットの経路決定 |
| 解決方法 | 強化学習 |
| 強化学習 | 試行錯誤を通じて学習する機械学習の一種 |
| エージェント | 学習を行う主体 |
| 報酬 | 行動の結果として得られる評価値 |
| 学習プロセス | エージェントは報酬を最大化するように行動を学習 |
| 応用例 | 自動運転、ゲーム、配送ルート最適化、生産ライン効率化 |
行動価値の学習

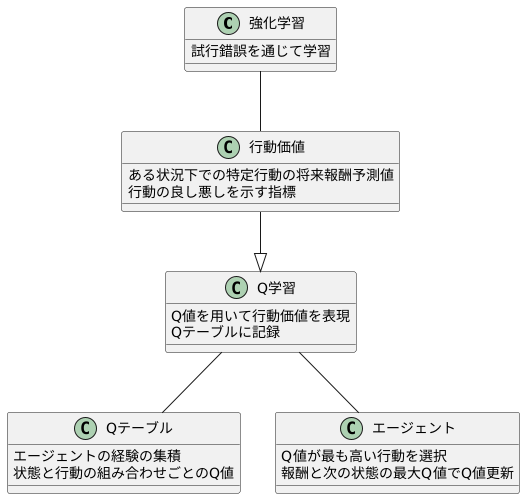
強化学習とは、試行錯誤を通じて学習を行う人工知能の学習方法の一つです。この学習方法において、行動価値は非常に重要な概念です。行動価値とは、ある状況下で特定の行動をとった場合に、将来的に得られるであろう報酬の予測値を表します。言い換えると、その行動がどれくらい良い結果をもたらすかを示す指標と言えるでしょう。
例えば、囲碁や将棋を考えてみましょう。現在の盤面の状態が「状況」であり、次にどの駒をどこに動かすかが「行動」です。この時、それぞれの行動に対して行動価値が割り当てられます。より良い手、つまり勝利に繋がる手ほど、高い行動価値を持つことになります。
行動価値は、どのようにして求められるのでしょうか。強化学習では、Q学習という手法がよく用いられます。Q学習では、Q値と呼ばれる値を用いて行動価値を表現します。Q値は、状態と行動の組み合わせごとに計算され、Qテーブルと呼ばれる表に記録されます。このQテーブルは、いわばエージェントの経験の集積と言えるでしょう。最初はランダムな値が入っていますが、エージェントが様々な行動を試み、その結果として報酬を得ることで、Q値は徐々に更新されていきます。
具体的には、エージェントは現在の状態において、Q値が最も高い行動を選択します。そして、その行動を実行した結果として得られた報酬と、次の状態における最大のQ値を用いて、現在の状態と行動に対するQ値を更新します。この更新プロセスを繰り返すことで、Q値は真の行動価値に近づいていきます。つまり、エージェントは経験を通じて、どの状況でどの行動をとるべきかを学習していくのです。このように、行動価値の学習は、強化学習において中心的な役割を果たしています。
報酬による学習

報酬による学習とは、行動の結果に応じて与えられる報酬を手がかりに、どのような行動をとるべきかを学習する方法です。まるで動物の訓練のように、望ましい行動には褒美を与え、望ましくない行動には罰を与えることで、より良い行動を促すことができます。この学習方法を人工知能に応用したものが、深層強化学習の中核をなす技術の一つであるDQN(深層Q学習)です。
DQNは、ゲームの攻略方法を学ぶ人工知能と考えることができます。ゲームを進める中で、人工知能は様々な行動を試し、その結果として報酬を受け取ります。例えば、迷路ゲームを考えてみましょう。人工知能がゴールに辿り着けば、大きな報酬が与えられます。逆に、壁にぶつかったり、遠回りしたりすると、報酬は与えられません。あるいは、制限時間がある場合は、時間経過に応じてペナルティとして負の報酬が与えられることもあります。
DQNは、この報酬を最大化することを目指して学習を進めます。過去の経験から、どの行動がどの程度の報酬に繋がるかを学習し、将来の行動選択に役立てるのです。具体的には、Q値と呼ばれる数値を使って、各状態における各行動の価値を評価します。Q値が高いほど、その行動が将来大きな報酬に繋がると期待されることを意味します。
人工知能は、行動の結果として得られた報酬と、次の状態におけるQ値を使って現在の状態におけるQ値を更新します。例えば、ある行動によって高い報酬が得られ、次の状態のQ値も高ければ、その行動のQ値は高く更新されます。逆に、低い報酬しか得られず、次の状態のQ値も低ければ、その行動のQ値は低く更新されます。このように、試行錯誤と報酬のフィードバックを通して、人工知能は徐々に最適な行動を学習していくのです。まるで迷路を何度も挑戦することで、最短ルートを覚えていく人間のように、DQNも報酬という道しるべを頼りに、最適な行動戦略を身につけていきます。
| 項目 | 説明 |
|---|---|
| 報酬による学習 | 行動の結果に応じて与えられる報酬を手がかりに、どのような行動をとるべきかを学習する方法。 |
| DQN (深層Q学習) | 報酬による学習を人工知能に応用した技術。ゲームの攻略方法を学ぶ人工知能のように、報酬を最大化することを目指して学習する。 |
| 報酬の例(迷路ゲーム) | ゴール到達で大きな報酬、壁にぶつかる/遠回りで報酬なし、時間経過で負の報酬(ペナルティ)。 |
| Q値 | 各状態における各行動の価値を評価する数値。Q値が高いほど、将来大きな報酬に繋がると期待される。 |
| Q値の更新 | 行動の結果として得られた報酬と、次の状態におけるQ値を使って現在の状態におけるQ値を更新。試行錯誤と報酬のフィードバックを通して最適な行動を学習。 |
将来の報酬を考慮

強化学習における将来の報酬を適切に評価することは、エージェントが長期的な目標を達成するために不可欠です。将来の報酬とは、エージェントが将来のある時点で受け取る報酬のことです。将来の報酬を現在の価値に換算するために、割引率という考え方が用いられます。割引率は、0から1の間の値で表され、この値が将来の報酬の評価にどのように影響するかを説明します。
割引率を理解するために、具体的な例を考えてみましょう。もし割引率が0に設定されている場合、エージェントは目先の報酬だけを重視し、将来の報酬は全く考慮しません。つまり、長期的な目標を達成するためには、割引率を0より大きく設定する必要があります。
一方、割引率が1に近い値に設定されている場合、エージェントは将来の報酬を現在の報酬とほぼ同じ価値として評価します。例えば、割引率が0.9だとすると、1段階先の報酬は現在の価値の9割、2段階先の報酬は8割1分、3段階先の報酬は7割2分9厘、といった具合に、時間経過とともに指数関数的に減衰していきます。
割引率の設定は、エージェントの学習に大きな影響を与えます。割引率が小さすぎると、エージェントは目先の利益に囚われ、長期的な目標を達成することができません。逆に、割引率が大きすぎると、遠い将来の不確実な報酬を過大評価してしまう可能性があります。したがって、適切な割引率を設定することが、強化学習の成功には不可欠です。最適な割引率は、扱う問題の性質や時間的尺度に依存するため、実験や調整を通じて適切な値を見つけることが重要です。
| 割引率 | エージェントの行動 | 将来の報酬の評価 | 長期的な目標達成 |
|---|---|---|---|
| 0 | 目先の報酬のみ重視 | 将来の報酬を全く考慮しない | 達成できない |
| 0 < 割引率 < 1 (e.g., 0.9) | 将来の報酬も考慮 | 時間経過とともに指数関数的に減衰 (e.g., 1段階後: 9割, 2段階後: 8割1分, 3段階後: 7割2分9厘) | 適切な値の設定が必要 |
| 1に近い値 | 将来の報酬を現在の報酬とほぼ同じ価値で評価 | 将来の報酬を高く評価 | 不確実な報酬を過大評価する可能性あり |
深層学習による表現学習

深層学習は、人間の脳の仕組みを模倣した多層構造の神経回路網を用いて、複雑な情報を学習する技術です。この技術を表現学習に適用することで、データの持つ本質的な特徴を自動的に抽出することができます。従来の機械学習では、データの特徴を人間が設計する必要がありましたが、深層学習を用いることで、この作業を自動化することが可能になります。
深層強化学習の一つであるDQNは、この深層学習による表現学習を用いて、ゲームの状態や行動を数値化し、コンピュータが理解できるようにしています。例えば、画面に映し出されたゲームの状態をピクセルデータとして入力し、深層学習モデルによって処理することで、ゲームの状態を特徴付ける数値表現を獲得します。この数値表現は、ゲーム画面のどこに敵がいるか、アイテムがあるかといった情報を抽象的に表現したものになります。
DQNでは、この状態の数値表現を入力として受け取り、各行動に対する価値(Q値)を出力する神経回路網を学習します。Q値とは、ある状態である行動を取った場合に、将来得られる報酬の期待値です。神経回路網は、過去の経験から学習し、どの行動がより高い報酬につながるかを予測します。従来のQ学習では、状態と行動の組み合わせごとにQ値を記録する必要がありました。しかし、ゲームの状態や行動の種類が膨大な場合、全ての組み合わせを記録することは現実的に不可能です。
DQNでは、深層学習を用いることで、状態を効率的に表現し、任意の状態におけるQ値を推定できるため、状態数が膨大な場合でも適用可能です。つまり、DQNは、深層学習の表現学習能力によって、複雑なゲームの状態を理解し、最適な行動を選択することができるのです。これにより、人間のような高度な判断を必要とするゲームにおいても、コンピュータが優れた性能を発揮することが可能になります。
| 項目 | 説明 |
|---|---|
| 深層学習 | 人間の脳の仕組みを模倣した多層構造の神経回路網を用いて、複雑な情報を学習する技術。データの持つ本質的な特徴を自動的に抽出する表現学習に利用される。 |
| 従来の機械学習 | データの特徴を人間が設計する必要があった。 |
| DQN (深層強化学習) | 深層学習による表現学習を用いて、ゲームの状態や行動を数値化し、コンピュータが理解できるようにする。 |
| DQNの仕組み |
|
| Q値 | ある状態である行動を取った場合に、将来得られる報酬の期待値。 |
| 従来のQ学習 | 状態と行動の組み合わせごとにQ値を記録する必要があり、状態数が膨大な場合、全ての組み合わせを記録することは現実的に不可能。 |
| DQNの利点 | 深層学習を用いることで、状態を効率的に表現し、任意の状態におけるQ値を推定できるため、状態数が膨大な場合でも適用可能。 |
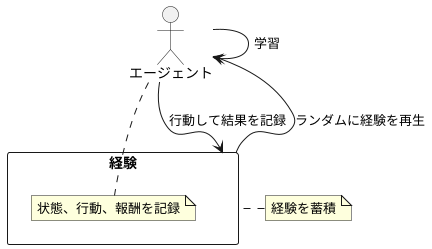
経験の蓄積と再生

私たちは物事を経験することで学び、成長していきます。機械学習の世界でも同じように、経験を蓄積し、それを繰り返し学習することで賢くなっていきます。この学習方法の一つに「経験再生」というものがあります。これは、まるで人間が過去の出来事を思い出し、そこから学びを得るかのようです。
具体的には、学習する機械、つまり「エージェント」は、様々な行動を試みます。そして、それぞれの行動によってどのような結果が得られたのか、つまり、どのような状態になり、どれだけの報酬が得られたのかを記録していきます。この記録の一つ一つを「経験」と呼びます。エージェントは、この経験をまるで日記のように大切に保管していきます。
学習の際には、蓄積した経験の中からいくつかを無作為に取り出して利用します。これを「再生」と呼びます。ちょうど、ランダムに日記を読み返すようなイメージです。もし、特定の経験ばかりから学習すると、偏った知識しか得られなくなってしまいます。しかし、様々な経験をランダムに思い出す、つまり再生することで、特定の状況に囚われず、より広い視野で物事を理解できるようになります。
さらに、過去の経験を繰り返し再生することで、重要な教訓を何度も学び、より深く理解することができます。これは、私たち人間が何度も復習することで知識を定着させるのと似ています。このように、経験の蓄積と再生は、機械学習、特に「深層強化学習」と呼ばれる分野で、エージェントが効率的に学習するための重要な技術となっています。まるで人生経験を積むように、機械も経験を積み重ねることで賢く成長していくのです。