半教師あり学習:機械学習の新潮流

AIを知りたい
『半教師あり学習』って、教師あり学習と教師なし学習のいいとこ取りってことで合ってますか?

AIエンジニア
いいところに気がつきましたね。まさに、両方のいいところを組み合わせた学習方法です。教師あり学習のように、少しのラベル付きデータを使うことで効率よく精度高く学習できます。さらに、教師なし学習のように、ラベルのない大量のデータも活用できるので、コストを抑えられます。
AIを知りたい
つまり、少しのヒントとたくさんの材料を使って学習するってことですね。具体的にどんな時に使うんですか?
AIエンジニア
そうですね。例えば、音声の認識や、インターネット上の情報の整理、生物の遺伝子情報の分類など、幅広い分野で使われています。ラベルを付けるのが大変な大量のデータを使う必要がある場合に有効です。
Semi-supervised learningとは。
人工知能で使われる『半教師あり学習』という言葉について説明します。半教師あり学習とは、少しだけ答えのついたデータと、たくさんの答えのないデータを混ぜて学習させる方法です。教師あり学習と教師なし学習のちょうど中間にあたる学習方法といえます。
教師あり学習は、学習の効率と精度が良いという利点がありますが、答えをつける作業に時間がかかります。半教師あり学習は、この良い点を残しつつ、作業の手間を減らすことができます。一方、教師なし学習は、たくさんのデータを扱うのに費用がかかりにくいという利点がありますが、学習の効率と精度はあまり高くありません。半教師あり学習は、この利点も残しつつ、効率と精度を高めることができます。
半教師あり学習は、音声の分析やインターネットの情報の分類、たんぱく質の成分の並び方の分類など、様々な場面で使われています。
半教師あり学習とは

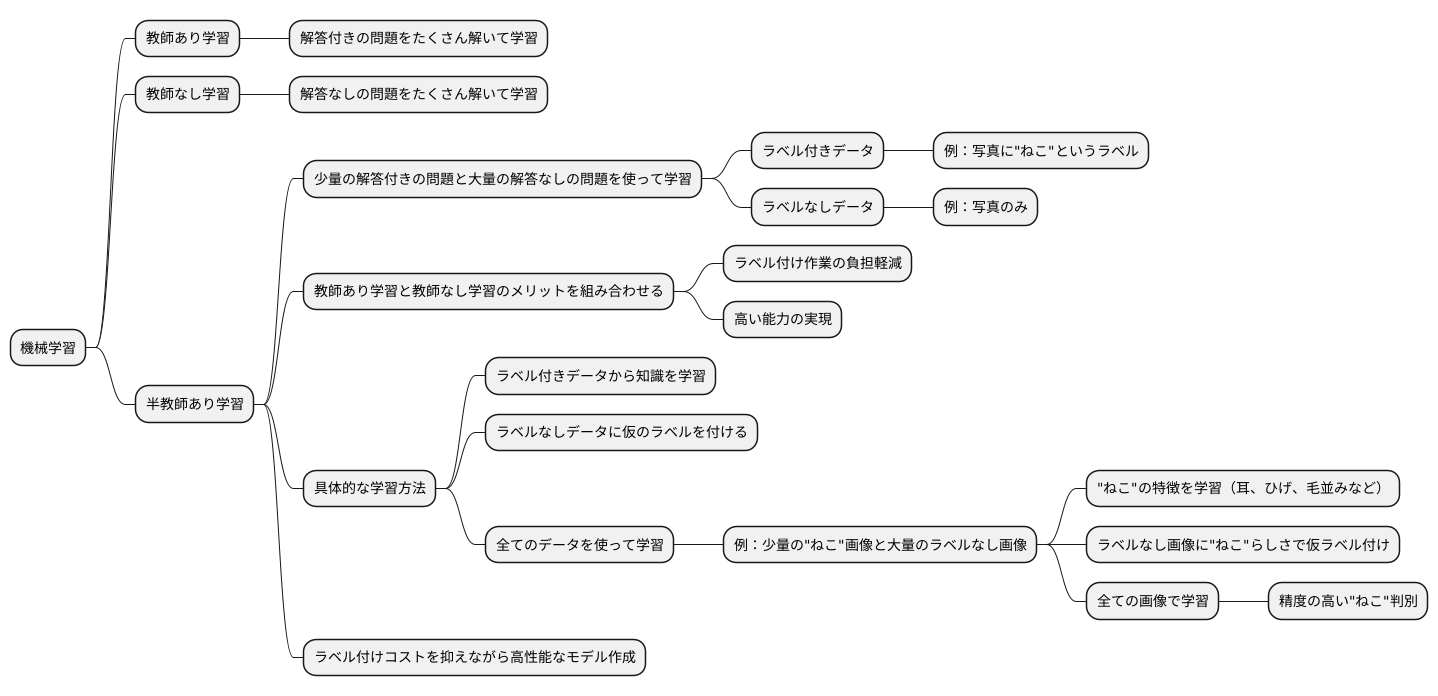
機械学習には大きく分けて三つの方法があります。一つ目は、解答付きの問題をたくさん解いて学習する教師あり学習、二つ目は解答なしの問題をたくさん解いて学習する教師なし学習、そして三つ目は少量の解答付きの問題と大量の解答なしの問題を使って学習する半教師あり学習です。
半教師あり学習は、この三つの学習方法のうちの一つで、少量のラベル付きデータと大量のラベルなしデータの両方を使って学習を行います。ラベル付きデータとは、例えばある写真に「ねこ」という名前が付けられているように、データに説明が付け加えられているデータのことです。一方、ラベルなしデータとは、写真だけが存在するといったように、説明が付け加えられていないデータのことです。
これまでの教師あり学習では、ラベル付きデータのみを使って学習していたため、大量のデータにラベルを付ける作業が必要で、費用と時間が多くかかっていました。一方で、教師なし学習はラベルなしデータのみを使うため、データの構造や特徴をつかむことはできますが、特定の作業に対する能力は低い傾向にあります。
半教師あり学習は、これらの二つの学習方法のよいところを組み合わせることで、ラベル付け作業の負担を軽くしつつ、高い能力を実現することを目指しています。具体的には、ラベル付きデータから学習した知識をラベルなしデータに当てはめることで、ラベルなしデータにも仮のラベルを付け、より多くのデータで学習を行います。
例えば、少量の「ねこ」とラベル付けされた画像と、大量のラベルのない画像を使って学習する場合を考えてみましょう。まず、ラベル付きの「ねこ」の画像から、ねこの特徴(耳の形、ひげ、毛並みなど)を学習します。次に、この学習した特徴をラベルなしの画像に当てはめ、「ねこ」らしさの高い画像に仮の「ねこ」ラベルを付けます。そして、これらのラベル付きと仮ラベル付きの画像を全て使って学習を行うことで、より多くのデータで学習できたことになり、少ないラベル付きデータでも精度の高いねこの判別ができるようになります。このように、半教師あり学習は、ラベル付けのコストを抑えながら、高性能なモデルを作ることを可能にします。
教師あり学習との違い

{教師あり学習は、あらかじめ答えの分かっているデータを使って学習を進めます。 例えば、たくさんの写真に「犬」や「猫」といったラベルが付けられており、それらの写真とラベルをセットにして学習することで、新しい写真を見たときに「犬」か「猫」かを判断できるようになります。この学習方法では、大量のラベル付きデータが必要です。犬と猫を見分けるためには、それぞれ何千枚、何万枚もの写真にラベルを付けて学習させる必要があるでしょう。これは、とても手間と時間がかかる作業です。また、ラベルの正確さも重要です。もしラベルが間違っていると、学習モデルも間違った判断をするようになってしまいます。
一方で、半教師あり学習は、ラベル付きデータとラベルのないデータを両方使って学習します。少量のラベル付きデータと大量のラベルのないデータを組み合わせることで、ラベル付けの手間を大幅に減らすことができます。ラベルのないデータは、インターネットなどから簡単に入手できる場合が多く、費用も抑えられます。例えば、犬と猫のラベル付き写真が数百枚と、ラベルのない写真が数万枚あったとします。半教師あり学習では、ラベル付き写真から犬と猫の特徴を学び、その知識をラベルのない写真に適用することで、より多くのデータから学習することができます。このように、ラベルのないデータを活用することで、ラベル付けにかかる費用と時間を大幅に削減できるのです。さらに、ラベル付きデータが少ない場合でも、ラベルのないデータから学習することで、教師あり学習よりも高い精度を達成できる場合もあります。つまり、半教師あり学習は、限られた資源で効率的に学習を進めるための、有効な学習方法と言えるでしょう。
| 学習方法 | データ | メリット | デメリット |
|---|---|---|---|
| 教師あり学習 | ラベル付きデータ(大量) | 新しいデータに対して正確な予測が可能 | ラベル付けに手間と時間がかかる ラベルの正確さが重要 |
| 半教師あり学習 | ラベル付きデータ(少量) + ラベルのないデータ(大量) | ラベル付けの手間と費用を削減 ラベル付きデータが少ない場合でも高精度を達成できる可能性がある |
– |
教師なし学習との違い

教師なし学習と半教師あり学習、どちらも大量のデータを扱う機械学習の手法ですが、その学習方法には大きな違いがあります。教師なし学習は、例えるなら、おもちゃの山を子供に与えて自由に遊ばせるようなものです。子供は、色や形、大きさなど、おもちゃの特徴に基づいて、似たおもちゃ끼리まとめていくでしょう。しかし、親から「これは車、これは人形」と教えられていないため、それぞれのグループに名前をつけることはできません。つまり、データの構造やパターンを見つけることは得意ですが、具体的な意味や役割を理解することはできません。
一方、半教師あり学習は、少しだけ教えられた子供のようなものです。おもちゃの山の中から、親がいくつかのおもちゃを選び、「これは車」、「これは人形」と教えてくれます。子供は、教えられたおもちゃの特徴を参考にしながら、残りの多くのおもちゃを自分で分類していきます。既に「車」や「人形」の例を知っているので、教師なし学習の場合よりも正確に分類できる可能性が高くなります。つまり、少量のラベル付きデータは、学習の方向性を示す羅針盤のような役割を果たし、モデルがより高い精度でタスクをこなせるように導きます。
このように、両者の違いは「教師」となるラベル付きデータの有無にあります。ラベルがない教師なし学習は、データの全体像を掴むのに役立ち、データの可視化や異常検知などに用いられます。一方、ラベル付きデータが少量でも存在する半教師あり学習は、分類や回帰といった特定の課題の解決に威力を発揮し、教師あり学習に必要なラベル付きデータの作成コストを削減できるという利点も持ちます。大量のデータの中に一部だけラベルが付与されている場合など、半教師あり学習は非常に有効な学習方法と言えるでしょう。
| 学習方法 | ラベル付きデータ | 学習の仕組み | 得意なこと | 用途 | メリット |
|---|---|---|---|---|---|
| 教師なし学習 | なし | データの特徴に基づいて、似たデータをグループ化する | データの構造やパターンの発見 | データの可視化、異常検知 | ラベル付けが不要 |
| 半教師あり学習 | 少量あり | 少量のラベル付きデータを参考に、残りのデータを分類する | 分類、回帰 | 教師あり学習のコスト削減 | 少量のラベルデータで高精度な学習が可能 |
半教師あり学習の利点

機械学習を行う上で、学習データへのラベル付けは大変な手間がかかります。ラベル付けとは、データ一つ一つにそのデータが何を表すのかという情報を付与する作業のことです。例えば、画像に写っているものが「犬」なのか「猫」なのかを判断し、それぞれの画像に「犬」や「猫」といったラベルを付ける作業です。このラベル付け作業は、人手で行うことが多く、多大な時間と費用がかかるため、機械学習の大きな課題となっています。
そこで注目されているのが、半教師あり学習という手法です。半教師あり学習とは、少量のラベル付きデータと大量のラベルなしデータを組み合わせて学習を行う手法です。ラベル付きデータを用いてモデルに基本的な知識を教え、ラベルなしデータを用いてモデルの精度を高めていきます。
半教師あり学習の最大の利点は、ラベル付けの手間を大幅に削減できることです。ラベル付きデータは少量で済むため、ラベル付けにかかる時間と費用を大幅に抑えることができます。一方で、大量のラベルなしデータは比較的容易に入手できることが多いため、データ収集にかかる負担も軽減されます。
さらに、半教師あり学習は、ラベル付きデータが少ない場合でも、高い精度を実現できるという利点もあります。ラベルなしデータから、データの構造や特徴といった有用な情報を抽出し、モデルの学習に活用することで、少量のラベル付きデータだけでは得られない高い精度を実現することが可能となります。
特に、近年の機械学習の中心的な手法である深層学習は、大量のデータを用いて学習を行うことで高い性能を発揮します。しかし、大量のデータを全てラベル付けするのは現実的に困難です。そのため、深層学習においては、半教師あり学習が非常に有効な手法となります。ラベルなしデータも活用することで、学習データ量を大幅に増やすことができ、深層学習モデルの性能向上に大きく貢献します。
| 項目 | 説明 |
|---|---|
| ラベル付け | データに意味を表すラベルを付与する作業。例:画像に「犬」や「猫」といったラベルを付ける。人手で行うことが多く、時間と費用がかかる。 |
| 半教師あり学習 | 少量のラベル付きデータと大量のラベルなしデータを組み合わせて学習を行う手法。 |
| 半教師あり学習の利点 | ラベル付けの手間と費用を削減、ラベル付きデータが少ない場合でも高精度を実現可能。 |
| 深層学習との関係 | 深層学習は大量のデータを用いることで高性能を発揮するが、ラベル付けは困難。半教師あり学習はラベルなしデータも活用できるため、深層学習の性能向上に貢献。 |
半教師あり学習の応用

半教師あり学習は、限られた量のラベル付きデータと大量のラベルなしデータの両方を利用する学習方法で、様々な分野でその力を発揮しています。
例えば、音声認識の分野では、音声データのラベル付けには多大な時間と労力がかかります。そこで、少量の音声データにだけラベルを付け、残りの大量の音声データはラベルなしのまま、半教師あり学習を用いてモデルを訓練します。こうすることで、少ないラベル付きデータでも高精度な音声認識システムを構築することが可能になります。
画像認識の分野でも、半教師あり学習は有効です。画像データは大量に存在しますが、全ての画像にラベルを付けるのは現実的ではありません。例えば、猫の画像を認識するモデルを訓練したい場合、少量の猫の画像に「猫」というラベルを付け、残りの大量の画像にはラベルを付けずに学習させることで、ラベル付けのコストを抑えつつ、高精度な画像認識モデルを実現できます。
自然言語処理においても、半教師あり学習は応用されています。例えば、文章を分類するタスクでは、大量の文章データにラベルを付けるのは困難です。そこで、少量の文章にラベルを付け、残りの文章はラベルなしのまま、半教師あり学習を用いてモデルを訓練します。これにより、ラベル付けの負担を軽減しながら、精度の高い文章分類が可能となります。機械翻訳の分野でも、半教師あり学習によって、より自然で滑らかな翻訳結果を得られるようになってきています。
医療診断のような、データの収集が難しい分野でも、半教師あり学習は活躍しています。例えば、希少な病気の診断では、症例データが限られています。このような場合、限られた数の診断データにラベルを付け、他の関連データはラベルなしのまま学習させることで、少ないデータからでも病気の予測や診断精度の向上に貢献できます。このように、半教師あり学習は、様々な分野でデータ活用を促進し、より良い成果を生み出すための重要な技術となっています。
| 分野 | 半教師あり学習の適用例 | メリット |
|---|---|---|
| 音声認識 | 少量の音声データにラベルを付け、残りの大量の音声データはラベルなしのままモデルを訓練 | 少ないラベル付きデータでも高精度な音声認識システムを構築可能 |
| 画像認識 | 少量の画像にラベルを付け、残りの大量の画像はラベルなしのまま学習(例:猫の画像認識) | ラベル付けコストを抑えつつ、高精度な画像認識モデルを実現 |
| 自然言語処理 | 少量の文章にラベルを付け、残りの文章はラベルなしのままモデルを訓練(例:文章分類、機械翻訳) | ラベル付けの負担を軽減しながら、精度の高い処理が可能 |
| 医療診断 | 限られた数の診断データにラベルを付け、他の関連データはラベルなしのまま学習(例:希少な病気の診断) | 少ないデータからでも病気の予測や診断精度の向上に貢献 |
今後の展望

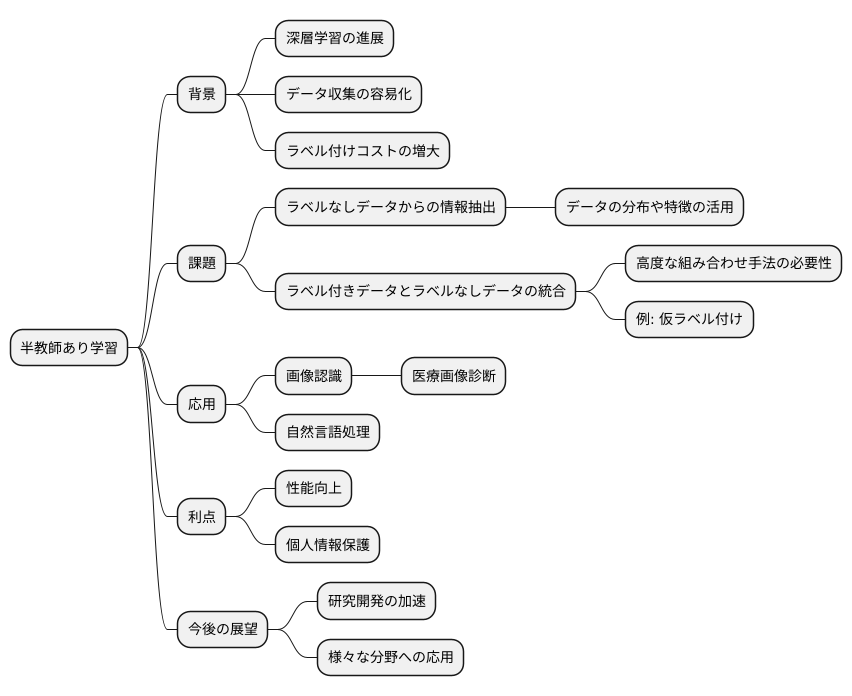
近年、深層学習技術が急速に発展を見せています。それと同時に、学習データの一部にしかラベル(正解情報)が付いていない「半教師あり学習」という研究分野も活発に研究が行われています。大量のデータを集めることは容易になった一方、全てのデータにラベルを付けるには多大なコストと時間がかかります。そこで、ラベル付きデータとラベルなしデータを共に活用する半教師あり学習が注目されているのです。
この分野における重要な課題は大きく分けて二つあります。一つ目は、ラベルのないデータからいかに効率良く情報を引き出すかという点です。ラベルがないデータは、一見すると価値がないように思えますが、データの分布や特徴といった情報は豊富に含んでいます。これらの情報を上手く活用することで、学習モデルの精度向上に繋げることが期待できます。二つ目は、ラベル付きデータとラベルなしデータをどのように組み合わせ、学習モデルに反映させるかという点です。単純に混ぜて学習させるだけでは効果が薄いため、より高度な組み合わせ方が必要となります。例えば、ラベル付きデータで学習したモデルを用いて、ラベルなしデータに仮のラベルを付け、それを新たな学習データとして利用するといった手法が研究されています。
今後、これらの課題を解決する、より洗練された半教師あり学習手法が開発されることで、画像認識や自然言語処理といった様々な分野で、更なる性能向上が見込まれます。例えば、医療画像診断では、専門医によるラベル付けが必要なため、ラベル付きデータの取得が困難です。半教師あり学習を用いることで、限られたラベル付きデータと大量のラベルなしデータから高精度な診断支援モデルを構築できる可能性があります。また、個人情報保護の観点からも、ラベルなしデータの活用は重要性を増しています。個人情報を含むデータにラベルを付けるのは、プライバシーリスクを伴います。半教師あり学習は、ラベルなしデータを中心的に活用することで、このリスクを軽減しながら、効果的な学習を実現できるため、今後の機械学習において必要不可欠な技術となるでしょう。ラベル付きデータの取得が難しい状況や、データのプライバシー保護の重要性が高まる中で、半教師あり学習は、これまで以上に注目され、研究開発が加速していくと予想されます。