
音声認識の立役者:隠れマルコフモデル

AIを知りたい
隠れマルコフモデルって、音声認識でよく使われるんですよね?どんな仕組みなんですか?

AIエンジニア
そうだね。音声認識でよく使われるよ。簡単に言うと、隠れた状態のつながりから、観測できる結果を予測するモデルなんだ。例えば、ある音の並びから、どんな言葉が spoken word 発せられたのかを推測するのに役立つんだよ。
AIを知りたい
隠れた状態のつながりって、どういうことですか?
AIエンジニア
例えば、「あ」という音の後に「い」という音が続く確率が高いといった、音のつながりの規則性みたいなものだ。この規則性が隠れた状態のつながりで、実際に聞こえてくる「あ」や「い」といった音が観測できる結果にあたるんだよ。隠れマルコフモデルでは、この隠れた状態のつながりを利用して、音声を認識するんだ。
隠れマルコフモデルとは。
人工知能にまつわる言葉、「隠れマルコフモデル」について説明します。音声認識に使われることの多いこのモデルは、隠れたマルコフモデル(HMM)とも呼ばれます。HMMは、音の最小単位ごとに学習することで、たくさんの言葉を扱えるようになっています。HMMで使われているマルコフモデルは、図を見ると分かるように、左から右への一方通行の構造になっています。「隠れ」というのは、どの状態からどの特徴が出ているかが隠されていて、分からないという意味です。
隠れた状態遷移:マルコフモデル

隠れた状態遷移マルコフモデルとは、時間とともに移り変わる仕組みを数理的に表す強力な手法です。音声の認識だけでなく、様々な分野で広く役立てられています。
この手法の根幹をなす考えは、「マルコフ性」と呼ばれるものです。マルコフ性とは、仕組みの次の状態は現在の状態だけに左右され、過去の状態には影響を受けないという性質です。例えば、明日の天気を予想する際に、今日までの天気の推移ではなく、今日の天気だけを考慮すれば良いという考え方です。これは、複雑な仕組みを単純化し、解析しやすくする上で非常に大切な特性です。
隠れた状態遷移マルコフモデルでは、このマルコフ性を前提として、仕組みの状態変化を確率で表します。例えば、今日の天気が「晴れ」だとします。このとき、明日の天気が「晴れ」になる確率、「曇り」になる確率、「雨」になる確率をそれぞれ定めることで、天気の変化を数理的に表すことができます。
しかし、このモデルの「隠れた」とはどういう意味でしょうか? 天気の例で言えば、「晴れ」「曇り」「雨」といった状態は直接観測できます。しかし、多くの場合、観測できるのは状態その自体ではなく、状態に関連する何らかの信号です。例えば、ある装置の内部状態は直接観測できませんが、装置から出力される信号は観測できます。隠れた状態遷移マルコフモデルは、このような観測できる信号から、隠れた状態を推定することを可能にします。
このように、状態遷移を確率で表すことで、不確実性を含む現実世界の様々な現象をより的確に捉えることができるのです。まさに、目に見えない状態の変化を捉える、隠れた状態遷移マルコフモデルの真価がここにあります。
| 項目 | 説明 |
|---|---|
| 隠れた状態遷移マルコフモデル | 時間とともに移り変わる仕組みを数理的に表す手法。音声認識など様々な分野で活用。 |
| マルコフ性 | 次の状態は現在の状態だけに依存し、過去の状態には影響を受けない性質。 |
| 状態遷移確率 | ある状態から別の状態へ遷移する確率。例:今日の天気が晴れなら、明日の天気が晴れ/曇り/雨になる確率。 |
| 隠れた状態 | 直接観測できない内部状態。観測できるのは状態に関連する信号。 |
| 観測信号 | 隠れた状態から出力される観測可能な信号。例:装置の出力信号。 |
| モデルの目的 | 観測信号から隠れた状態を推定する。 |
見えない状態:隠れマルコフモデル

隠れマルコフモデルは、直接目には見えない状態を推定するための統計モデルです。「隠れ」とは、システムの内部状態を直接観察することができないことを意味します。例えば、天気の変化を考えてみましょう。私たちは、空模様や気温といった目に見える観測データから、今日の天気が「晴れ」なのか「雨」なのかを判断します。しかし、天気という状態そのものを直接見ることはできません。真の天気は隠れており、私たちは様々な観測を通して推測するしかありません。
隠れマルコフモデルでは、このような隠れた状態を確率的に表現します。例えば、「晴れ」という状態の次の日は、「晴れ」である確率が高く、「雨」である確率は低いといった具合です。また、各状態からは、対応する観測データが生成されます。「晴れ」の状態からは、「空が青い」「気温が高い」といった観測データが得られる確率が高くなります。逆に、「雨」の状態からは、「空が暗い」「気温が低い」「雨が降っている」といった観測データが得られる確率が高くなります。
音声認識の例では、私たちが聞くのは音声信号ですが、その背後にある言葉や音といった状態は直接知ることができません。これらの隠れた状態は、観測された音声信号を通して推測されます。隠れマルコフモデルは、各状態からどのような音声信号が観測されるかという確率を定義することで、観測データと隠れた状態の関係をモデル化します。例えば、「あ」という音に対応する状態からは、「あ」の音声信号が観測される確率が高く、他の音声信号が観測される確率は低いといった具合です。このように、観測データと隠れた状態を確率的に結びつけることで、聞こえてきた音声から、実際に発声された言葉や音を推定することが可能になります。これは、直接観測できない現象を解析する上で非常に強力な道具となります。
音声認識への応用

音声認識は、人間の声を機械が理解できるように文字や命令に変換する技術です。この技術を支える重要な仕組みの一つに、隠れマルコフモデルがあります。隠れマルコフモデルを使うと、目には見えない音の繋がりを確率で表現することができます。
音声認識では、入力された音声を単語や文章に変換する必要があります。しかし、音声をそのまま文字に対応させるのは難しいです。なぜなら、同じ言葉でも話す人や状況によって発音が変わるからです。そこで、隠れマルコフモデルは音声を「音素」と呼ばれる基本的な音の並びとして捉えます。音素とは、例えば「あ」や「い」のような母音、「か」や「さ」のような子音などです。
隠れマルコフモデルでは、音素の並び方がマルコフ過程という数学モデルで表現されます。マルコフ過程とは、現在の状態が直前の状態だけに影響されるという考え方です。例えば、「あ」の次に「い」が来る確率、「い」の次に「う」が来る確率といった具合に、前後の音素の関係を確率で表します。
また、各音素からどのような音声が観測されるかについても確率で表現します。例えば、「あ」という音素は「あ」という音として聞こえる確率が高いですが、少し違った音で聞こえることもあります。このような不確実性を確率で表現することで、様々な発音に対応できます。
音声認識では、観測された音声から、最も可能性の高い音素の並びを推定します。この推定には、隠れマルコフモデルに基づいた計算方法が用いられます。こうして音素の並びが分かれば、それを単語や文章に変換することができます。
隠れマルコフモデルの利点は、音素ごとのモデルを学習しておけば、様々な単語に対応できることです。新しい単語が追加された場合でも、その単語を構成する音素のモデルが既に学習されていれば、容易に対応できます。これは、多くの単語を扱う音声認識システムを作る上で、とても大切なことです。
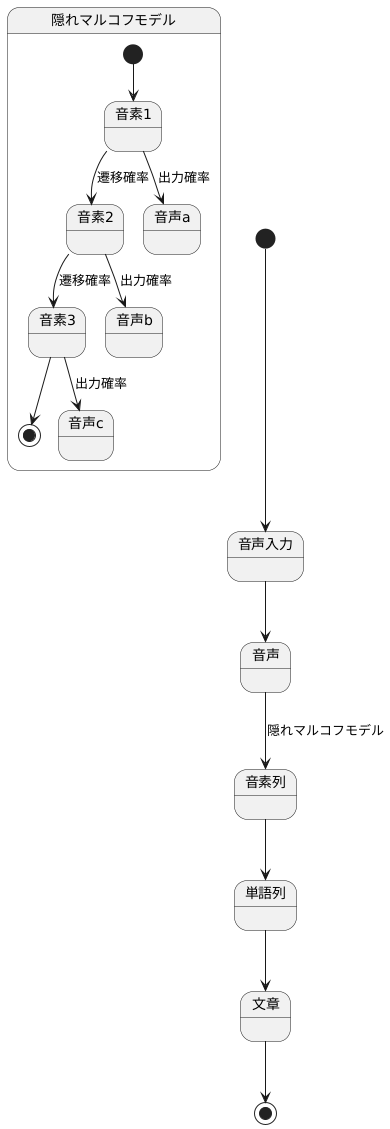
左から右への構造

隠れマルコフモデルは、目に見えない状態の遷移を確率的に扱うモデルです。このモデルは、様々な分野で活用されていますが、特に音声認識の分野で広く使われています。音声認識では、音声を認識するために、音の並びを分析する必要があります。この音の並びには、時間的な順序という重要な特徴があります。例えば、「こんにちは」という言葉は、「こ」「ん」「に」「ち」「は」という音の並びで構成されていますが、これらの音は必ずこの順番で発音されます。「は」「に」「ち」「こ」「ん」という逆の順番で発音されることはありません。
隠れマルコフモデルでは、この時間的な順序を表現するために、「左から右への構造」という考え方を用います。これは、時間の流れを左から右への流れとして捉え、状態の遷移も常に左から右へと進むようにモデル化するということです。例えば、「こんにちは」の音声認識を行う場合、最初の状態は「こ」の音に対応する状態であり、そこから「ん」の音に対応する状態へ遷移し、さらに「に」、「ち」、「は」に対応する状態へと順に遷移していきます。このように、状態の遷移は常に過去の状態から未来の状態へと向かい、逆方向の遷移は起こりません。
この左から右への構造は、音声信号のような時間的な並びを持つデータを扱う上で非常に重要です。なぜなら、この構造により、モデルの複雑さを抑え、学習を効率的に行うことができるからです。もし、状態が様々な方向へ遷移するような複雑なモデルを考えると、計算量が膨大になり、学習が難しくなります。左から右への構造という制約を設けることで、計算量を削減し、効率的な学習を実現できます。さらに、時間的な順序を適切に表現できるため、音声認識の精度向上にも大きく貢献しています。つまり、左から右への構造は、隠れマルコフモデルを用いた音声認識において、なくてはならない重要な要素と言えるでしょう。

学習と認識

音声の言葉を書き起こす、音声認識の仕組みを説明します。音声認識でよく使われる隠れマルコフモデルは、多くの音声データを使って学習を行います。この学習データには、実際の音声と、その音声に対応する音の最小単位である音素の情報が含まれています。例えば、「こんにちは」という音声であれば、「k」「o」「n」「n」「i」「ch」「i」「w」「a」といった音素の情報が記録されているのです。
学習の仕組みは、音素ごとに異なる音声信号の特徴を捉え、それらがどれだけの確率で現れるかを計算することです。さらに、ある音素の次にどの音素が現れやすいか、音素の繋がり方の確率(状態遷移確率)も学習します。こうして学習が進むと、音素と音声信号、音素同士の繋がりの関係性がモデルの中に記録されていきます。
学習を終えたモデルは、いよいよ未知の音声認識に挑戦します。認識の過程では、入力された音声信号を分析し、学習済みのモデルと照合します。各音素から観測される音声信号の確率分布と、音素の繋がり方の確率を用いて、最も可能性の高い音素の並びを探し出すのです。この音素の並びが、入力された音声の言葉として認識されるわけです。
この探索には、ビタビアルゴリズムという効率的な計算方法が使われます。ビタビアルゴリズムは、動的計画法と呼ばれる手法に基づき、膨大な組み合わせの中から最適な音素の並びを素早く見つけ出すことができます。このアルゴリズムのおかげで、音声認識は高速かつ正確に行えるようになっているのです。
今後の展望

これまで音声を文字に変換する技術で、隠れマルコフモデルは大きな成果をあげてきました。まるで隠された状態を推測する名探偵のように、音のつながりから言葉を探り当ててきたのです。しかし、この名探偵にも弱点があります。例えば、周囲の騒音や話す人の癖によって、音声が変化してしまうと、うまく推理できないことがあります。また、言葉のつながりの複雑さを十分に理解できていないという点も課題です。
そこで、近年注目されているのが、深層学習と呼ばれる技術との組み合わせです。深層学習は、人間の脳のように複雑な情報を処理できるため、大量の音声データから隠れた規則性を自ら学ぶことができます。まるで、膨大な事件記録を読み込んで、犯人を見つける鋭い鑑識官のようです。この鑑識官と名探偵が協力すれば、より正確で、様々な状況に対応できる音声認識システムを作ることができると期待されています。
具体的には、深層学習を使って、音の細かい特徴を捉えたり、言葉のつながりをより深く理解したりすることが考えられます。例えば、雑踏の中でも特定の声を聞き分けたり、方言や訛りのある話し方でも正確に文字に変換したりすることができるようになるでしょう。また、話し言葉特有のあいまいさや省略を理解し、より自然な文章を生成することも可能になるかもしれません。まるで、話し手の意図まで汲み取る、まるで人の心を読むことができる通訳者のようです。
このように、隠れマルコフモデルと深層学習を組み合わせることで、音声認識技術はさらに進化し、私たちの生活を大きく変えていくでしょう。音声で機械を操作したり、外国語をリアルタイムで翻訳したり、まるで魔法のような世界が現実のものとなる日もそう遠くはないでしょう。
| 技術 | 特徴 | 利点 | 欠点 |
|---|---|---|---|
| 隠れマルコフモデル | 音のつながりから言葉を推測 | 音声認識で成果を上げている | 騒音や話し手の癖に弱い 言葉のつながりの複雑さを十分に理解できない |
| 深層学習 | 大量のデータから隠れた規則性を学習 | 複雑な情報を処理できる 音の細かい特徴を捉えられる 言葉のつながりを深く理解できる |
– |
| 隠れマルコフモデル + 深層学習 | 両者の利点を組み合わせる | より正確で様々な状況に対応できる 話し手の意図まで汲み取れる |
– |