未知データへの対応:汎化性能

AIを知りたい
「汎化性能」ってよく聞くんですけど、具体的にどういう意味ですか?

AIエンジニア
いい質問ですね。たとえば、たくさんの犬の写真を見せて、「これは犬です」と機械に学習させたとします。学習後、初めて見る犬の写真を見せても「これは犬です」と正しく答えられたら、その機械は高い『汎化性能』を持っていると言えるのです。つまり、初めて見るデータにも対応できる力のことです。
AIを知りたい
なるほど。初めて見るデータに対応できる力のことなんですね。ということは、たくさんの犬の写真を学習させればさせるほど汎化性能は高くなるんですか?
AIエンジニア
必ずしもそうとは限りません。たとえば、限られた種類の犬の写真ばかり学習させると、初めて見る種類の犬の写真では正しく答えられない可能性があります。色々な種類の犬の写真をバランスよく学習させることが、汎化性能を高めるために重要なのです。
汎化性能とは。
人工知能に関する言葉である「広く使える能力」について説明します。この能力は、まだ見たことのないデータにどれくらい対応できるかを示すもので、人工知能の学習においては、この能力を高めることが大きな目標の一つと言えるでしょう。この能力をきちんと測るためには、学習に使うデータとテストに使うデータをきちんと分けて、学習や実験を行うことが大切です。
汎化性能とは

機械学習の模型の良し悪しを判断する上で、未知のデータへの対応力は極めて重要です。この対応力を汎化性能と呼びます。汎化性能とは、学習に用いなかった新しいデータに、どれほど的確に対応できるかを示す能力のことです。言い換えると、初めて見るデータに対しても、模型がどれほど正確に予測や分類を実行できるかを表す指標です。
たとえば、大量の手書き数字画像を使って数字を認識する模型を学習させたとします。学習に用いた画像に対しては100%の精度で数字を認識できたとしても、学習に使っていない新しい手書き数字画像に対してどれだけの精度で認識できるかが、その模型の真の価値を決めるのです。これが汎化性能の高さに繋がります。
学習済みのデータにだけ完璧に対応できたとしても、それは真の知性とは言えません。初めて見るデータ、つまり未知の状況にも的確に対応できる能力こそが、模型の知性を示すと言えるでしょう。未知のデータにうまく対応できない模型は、特定の状況でしか役に立たない、融通の利かないものになってしまいます。まるで、決まった道順しか覚えられないロボットのようです。
真に役立つ機械学習模型を作るためには、この汎化性能を高めることが不可欠です。それは、初めて訪れる街でも、地図を見たり周囲の景色を観察したりすることで自分の位置を理解し、目的地までたどり着ける人間の能力に似ています。初めての状況でも、これまでの知識や経験を活かして対応できる能力、これこそが機械学習模型にも求められる真の知性であり、汎化性能の目指すところです。この能力こそが、機械学習模型を様々な場面で役立つものにする鍵となるのです。
なぜ汎化性能が重要か

機械学習の目的は、現実世界の問題を解決することにあります。私たちの身の回りでは、常に新しい情報が生まれ、状況は変化し続けています。限られた学習情報にだけ対応できる学習模型では、実社会で役立つには限界があります。真に価値のある学習模型は、学習時には存在しなかった未知の情報に対しても、正しい予測や分類を行える必要があるのです。これを汎化性能と呼びます。
例として、病気の診断を助ける医療向け人工知能の開発を考えてみましょう。学習に使った情報には含まれていなかった症例でも、正しく診断できる能力、すなわち高い汎化性能が求められます。このような人工知能は、未知の病気に遭遇したとしても、その特徴を捉え、適切な診断を下すことが期待されます。また、患者の年齢や生活習慣、持病などの様々な要因を考慮した上で、個別化された診断を行うことも可能になるでしょう。
汎化性能の高い学習模型は、様々な状況や変化に柔軟に対応できるため、現実世界の問題解決に大きく貢献します。例えば、自動運転技術においても、汎化性能は非常に重要です。学習時に想定していなかったような、天候の急変や道路状況の変化、予期せぬ歩行者の行動など、様々な状況に遭遇する可能性があります。このような状況でも安全に運転を続けるためには、学習データに含まれていない状況にも対応できる、高い汎化性能が不可欠です。
このように、汎化性能は、人工知能が現実世界で真に役立つために欠かせない要素です。未知の状況に立ち向かうための羅針盤と言えるでしょう。今後の更なる技術発展によって、より汎化性能の高い学習模型が開発され、様々な分野で活躍していくことが期待されます。 より多くのデータで学習させることや、学習方法を工夫することで、汎化性能の向上に繋げることができると考えられています。
| 概念 | 説明 | 例 | 重要性 |
|---|---|---|---|
| 汎化性能 | 学習時に存在しなかった未知の情報に対しても、正しい予測や分類を行える能力 | 医療診断AI:未知の症例でも正しく診断 自動運転:天候の急変、予期せぬ歩行者など、学習データにない状況にも対応 |
AIが現実世界で役立つために不可欠 |
| 汎化性能の向上方法 | より多くのデータで学習 学習方法の工夫 |
汎化性能の評価方法

学習した知識をどれだけ未知のデータに適用できるかを示す指標が汎化性能です。この汎化性能を正しく測るためには、学習に使うデータと、性能の評価に使うデータをきちんと分けておくことがとても大切です。
まず、学習に使うデータを訓練データと呼びます。これは、いわば教科書のようなもので、機械学習モデルはこの訓練データから知識を吸収します。
次に、性能評価に使うデータがテストデータです。これは、訓練データを使って学習したモデルが、本当に新しいデータに対してもきちんと対応できるかを試すためのテストのようなものです。このテストデータは、モデルの学習には一切使いません。
なぜ、訓練データとテストデータを分ける必要があるのでしょうか?それは、過学習を防ぐためです。過学習とは、訓練データの内容は完全に覚えていても、新しいデータに対してはうまく対応できない状態のことです。まるで、教科書の例題は全て暗記しているのに、少し違う問題が出されると途端に解けなくなってしまう生徒のようです。
モデルが訓練データに過剰に適応してしまうと、訓練データに対する精度は非常に高いものの、未知のデータに対する精度は低くなってしまいます。これは、モデルが訓練データの特定の特徴や雑音までも学習してしまい、データの背後にある本質的な規則を捉えられていないことを意味します。
テストデータを使うことで、この過学習の影響を取り除き、モデルが真に未知のデータにどれだけ対応できるかを測ることができます。これが汎化性能の評価です。テストデータはモデルにとって全く新しいデータなので、モデルがどれだけ学習した内容を応用できるかを正確に評価できるのです。
| 用語 | 説明 | 目的 |
|---|---|---|
| 汎化性能 | 学習した知識を未知のデータに適用できるかを示す指標 | モデルが新しいデータにどれだけ対応できるかを評価 |
| 訓練データ | 学習に使うデータ (教科書のようなもの) | モデルに知識を学習させる |
| テストデータ | 性能評価に使うデータ (テストのようなもの) | モデルが新しいデータにきちんと対応できるか検証 |
| 過学習 | 訓練データに過剰に適応し、未知のデータにうまく対応できない状態 | 防ぐべき現象 |
訓練データとテストデータ

機械学習では、学習のために使うデータと、学習した結果を確かめるために使うデータを分けて考えることがとても大切です。この二つを、それぞれ訓練データとテストデータと呼びます。
訓練データは、例えるなら生徒が学ぶための教科書のようなものです。教科書には様々な問題と解答が載っており、生徒はそれらを繰り返し解くことで、問題の解き方や考え方を学びます。機械学習のモデルもこれと同じで、訓練データから様々なパターンや規則性を学びます。訓練データが多様で質が高いほど、モデルはより多くのことを学び、より良い結果を出せるようになります。まるで、たくさんの教科書で勉強した生徒が、より多くの知識を身につけるのと同じです。
一方、テストデータは、生徒の実力を測るための試験のようなものです。試験問題は、生徒が教科書で勉強した内容をもとに、どれだけ理解しているか、応用できるかを試すために作られます。機械学習でも同様に、テストデータを使って、訓練データで学習したモデルが、未知のデータに対してもきちんと予測や分類ができるかを確かめます。
テストデータは、モデルの学習には絶対に使用してはいけません。これは、試験問題を事前に生徒に教えてしまうと、本当の学力が測れないのと同じです。テストデータで学習したモデルは、テストデータに特化した解答を導き出すだけで、他のデータには対応できない可能性があります。これでは、まるでカンニングをして良い点を取った生徒のように、真の実力を持っているとは言えません。
このように、訓練データとテストデータをきちんと分けて使うことで、モデルの本当の力を正しく評価することができます。そして、より信頼できる、様々な状況で役立つモデルを作ることができるのです。
| 項目 | 説明 | 例え |
|---|---|---|
| 訓練データ | 機械学習モデルが学習に用いるデータ。モデルはここからパターンや規則性を学ぶ。データの質と量がモデルの性能に影響する。 | 生徒が学習に用いる教科書 |
| テストデータ | 学習済みモデルの性能を評価するためのデータ。モデルが未知のデータに対してどれくらい正確に予測・分類できるかを測る。学習には使用しない。 | 生徒の実力を測る試験 |
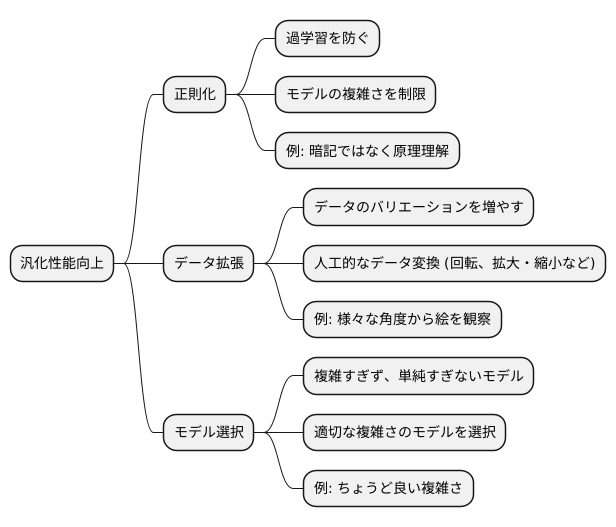
汎化性能を高めるための工夫

機械学習モデルの開発において、未知のデータに対しても正確な予測ができる能力、すなわち汎化性能は非常に重要です。この汎化性能を高めるためには、様々な工夫が凝らされています。
まず、過学習を防ぐための正則化は有効な手段の一つです。学習の過程で、モデルは訓練データの特徴を過度に捉えすぎてしまうことがあります。この状態を過学習と呼び、未知のデータに対する予測精度が低下する原因となります。正則化は、モデルの複雑さを制限することで、この過学習を抑える働きをします。例えるなら、暗記に偏った勉強方法ではなく、基本的な原理を理解することに重きを置くことで、応用問題にも対応できるようになる、といった具合です。
次に、データ拡張も汎化性能向上に貢献します。限られた訓練データに対して、回転や拡大・縮小などの変換を施すことで、人工的にデータのバリエーションを増やす手法です。これは、様々な角度から物事を見る訓練をさせることで、モデルの対応力を高めます。一枚の絵を色々な角度から観察することで、その絵の全体像をより深く理解できるようになるのと同じです。
さらに、問題の性質に適したモデルの選択も重要です。複雑すぎるモデルは、訓練データの些細な特徴まで捉えすぎて過学習を起こしやすくなります。反対に、単純すぎるモデルでは、データの重要な特徴を捉えきれず、予測精度が低下します。ちょうど良い複雑さのモデルを選ぶことが、汎化性能を高める鍵となります。
これらの工夫は単独で用いられるだけでなく、組み合わせて使用されることもあります。目的に合わせて適切な手法を選択・組み合わせることで、より汎化性能の高い、実用的な機械学習モデルを構築することが可能になります。