
データの集まりを見つける:クラスタリング

AIを知りたい
先生、『クラスタリング』ってよく聞くんですけど、一体どんなものなんですか?

AIエンジニア
良い質問だね。『クラスタリング』とは、データの集まりを、似ているもの同士でグループ分けすることだよ。 例えば、果物屋さんでりんご、みかん、バナナをそれぞれのかごに分けるようなものだね。
AIを知りたい
なるほど!でも、コンピューターはどうやって、どのデータが似ているのかを判断するんですか?
AIエンジニア
データの色や形、大きさなど、色々な特徴を数値で表して、その数値が近いもの同士を同じグループにするんだ。 例えば、りんごなら『赤くて丸い』、みかんは『オレンジ色で丸い』、バナナは『黄色くて長い』といった特徴でグループ分けできるんだよ。
クラスタリングとは。
データの集まりを扱う『集団分け』という手法について説明します。この集団分けは、あらかじめ正解が教えられていない学習方法の代表的なもので、似ているデータ同士をいくつかの集団にまとめて、データが本来持っている構造を見つける方法です。
クラスタリングとは

クラスタリングとは、データ分析における重要な手法の一つで、大量のデータの中から隠れた構造やパターンを見つけ出すことを目的としています。具体的には、様々な性質を持つデータの集まりを、データ同士の似ている部分に基づいて、いくつかのグループ(クラスタ)に自動的に分類する手法です。
例えるなら、たくさんの色とりどりのボールが混ざっている状態を想像してみてください。クラスタリングは、色の似たボールを同じ箱に入れ、最終的に複数の箱にボールを仕分ける作業に似ています。赤いボールは赤いボール同士、青いボールは青いボール同士といった具合に、似た特徴を持つデータを同じグループにまとめることで、データ全体を整理し、理解しやすくします。
この手法は、様々な分野で活用されています。例えば、会社の販売戦略においては、顧客の購買履歴データに基づいて顧客をいくつかのグループに分け、それぞれのグループに合わせた販売促進活動を行うことができます。また、画像認識の分野では、似た画像を自動的にグループ分けすることで、大量の画像データの中から特定の画像を効率的に検索することが可能になります。医療分野では、患者の症状データから似た症状を持つ患者をグループ分けし、病気の診断や治療に役立てるといった応用も考えられます。
クラスタリングは、データの背後に潜む関係性を発見するための強力なツールと言えるでしょう。大量のデータに圧倒され、そこから意味のある情報を抽出することが難しい場合でも、クラスタリングを用いることで、データ全体を俯瞰し、隠れたパターンを明らかにすることができます。これにより、データに基づいた的確な意思決定を行うための、重要な手がかりを得ることができるのです。
| 概要 | 説明 | 例 |
|---|---|---|
| クラスタリングとは | データ分析手法の一つ。データの類似性に基づいて、データをグループ(クラスタ)に分類。 | 色とりどりのボールを色の似たもの同士で箱に仕分ける。 |
| 目的 | 大量のデータの中から隠れた構造やパターンを見つけ出す。 | |
| 活用例 |
|
|
| メリット | データ全体を俯瞰し、隠れたパターンを明らかにすることで、データに基づいた的確な意思決定を行うための手がかりを得られる。 |
教師なし学習との関係

教師なし学習とは、正解ラベルを用いずにデータの構造や特徴を掴み取る機械学習の手法です。まるで、宝の地図なしに広大な島を探索し、似たような植物が生えている場所や地形が似ている場所を見つけて、島をいくつかのエリアに分け、それぞれのエリアの特徴を明らかにするようなものです。この教師なし学習の中で、データの似ているものを自動的にグループ分けする手法がクラスタリングです。
例えば、たくさんの果物を種類分けすることを考えてみましょう。りんご、みかん、ぶどう、バナナなどが混ざっています。これらの果物に「これはりんご」「これはみかん」といったように、あらかじめ名前を付けて教えることはしません。クラスタリングでは、果物の色、形、大きさといった特徴だけを見て、似ている果物同士をまとめていきます。赤い色の小さな丸い果物はまとめて「りんごのグループ」、オレンジ色の皮を持つ丸い果物はまとめて「みかんのグループ」といった具合です。
このように、クラスタリングは、データ自身の特徴を捉えてグループ分けを行います。そのため、新しい果物、例えば「いちご」が来たときでも、その色や形、大きさから「りんごのグループ」に近いと判断し、自動的に分類することができます。
従来の教師あり学習では、あらかじめ果物の種類を一つ一つ教えておく必要がありました。しかし、クラスタリングのような教師なし学習では、その手間がかかりません。データを集めるだけで、データの背後にある隠れた構造や関係性を発見できるため、データの準備にかかる時間や労力を大幅に減らすことができます。これは、大量のデータが容易に手に入る現代において、大きな利点と言えるでしょう。
クラスタリングの種類

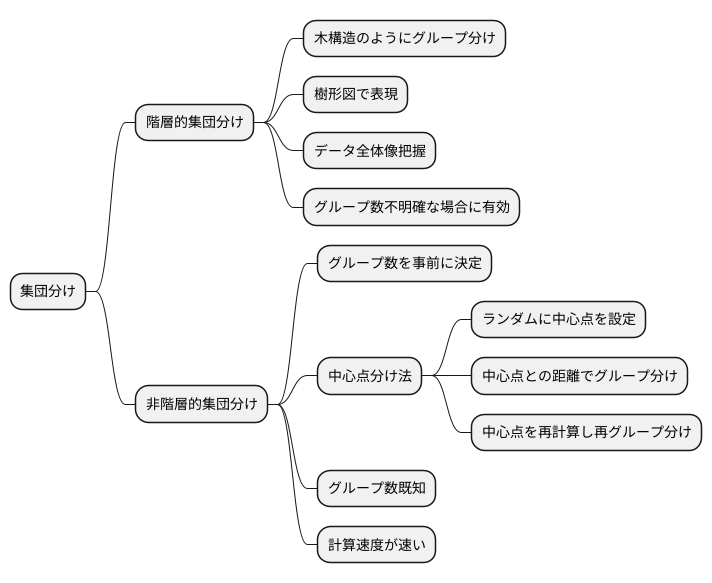
データの集まりを似た者同士でグループ分けする手法は、集団分けと呼ばれ、データ分析において重要な役割を担っています。集団分けには様々な方法があり、それぞれに得意とするデータの種類や目的が異なります。大きく分けて、階層的な集団分けと非階層的な集団分けという二つの種類があります。
階層的な集団分けは、まるで木を枝分かれさせていくように、データを段階的にグループ分けしていく手法です。まず、全てのデータが一つずつの小さなグループとして始まります。次に、最も似ている二つのグループを統合し、より大きなグループを作ります。この手順を繰り返すことで、最終的には全てのデータが一つの大きなグループに統合されるまで、階層構造が形成されます。この階層構造は、樹形図と呼ばれる図で視覚的に表現されます。樹形図を見ることで、データ間の類似度やグループの階層関係を容易に把握できます。階層的な集団分けは、データの全体像を把握したい場合や、グループの数があらかじめ分からない場合に有効です。
一方、非階層的な集団分けは、あらかじめグループの数を決めておき、データをその数のグループに分割する手法です。代表的な方法として、中心点分け法が挙げられます。中心点分け法では、まずランダムに中心点を設定します。次に、各データを中心点との距離に基づいて、最も近い中心点のグループに割り当てられます。その後、各グループの平均値を新たな中心点として再計算し、再度データを割り当て直します。この手順を繰り返すことで、最終的に各グループの中心点が安定し、データの分割が完了します。非階層的な集団分けは、グループの数をあらかじめ指定できる場合や、計算速度が速いという利点があります。
集団分けに用いる手法は、データの特性や分析の目的に合わせて適切に選択することが重要です。例えば、データが階層構造を持っている場合は階層的な集団分けが適していますし、グループの数が既知である場合は非階層的な集団分けが適しています。適切な手法を選ぶことで、より正確で意味のある結果を得ることができ、データ分析の精度向上に繋がります。
クラスタリングの活用例

集団分けの技術である、クラスタリングは、様々な分野で活用されています。
まず、販売促進の分野では、顧客をいくつかの集団に分け、それぞれの集団に合った広告配信や商品開発を行うことができます。例えば、ある会社の顧客を年齢や購買履歴に基づいて「若年層向け」「ファミリー層向け」「高齢層向け」といった具合に分類することで、それぞれの集団に適した広告を配信したり、新商品を開発したりすることが可能になります。これにより、広告の効果を高めたり、顧客満足度を向上させたりすることができます。
医療の分野でも、クラスタリングは役立っています。患者の症状や検査データに基づいて集団分けを行うことで、病気の診断や治療方針の決定を支援することができます。例えば、似た症状を持つ患者を同じ集団に分類することで、共通する原因や治療法を見つけ出す手がかりになります。また、検査データに基づいて患者のリスクを予測し、適切な予防措置を講じることも可能になります。
画像処理の分野では、画像認識や画像検索にクラスタリングが応用されています。似た特徴を持つ画像を同じ集団にまとめることで、効率的な画像管理を実現できます。例えば、大量の画像データの中から、特定の人物や物体が写っている画像を素早く探し出すことができます。また、画像認識技術と組み合わせることで、自動的に画像に写っている物体を識別したり、画像の内容を理解したりすることも可能になります。このように、クラスタリングは、データ分析の基盤技術として、様々な分野で応用され、データに基づいた意思決定を支援しています。今後も、人工知能技術の発展に伴い、クラスタリングの活用範囲はさらに広がっていくと予想されます。
| 分野 | 活用例 | 効果 |
|---|---|---|
| 販売促進 | 顧客を年齢や購買履歴に基づいて「若年層向け」「ファミリー層向け」「高齢層向け」といった具合に分類し、それぞれの集団に適した広告を配信したり、新商品を開発したりする。 | 広告の効果を高めたり、顧客満足度を向上させたりする。 |
| 医療 | 患者の症状や検査データに基づいて集団分けを行い、病気の診断や治療方針の決定を支援する。
|
病気の診断や治療方針の決定を支援、適切な予防措置 |
| 画像処理 | 似た特徴を持つ画像を同じ集団にまとめることで、効率的な画像管理を実現する。
|
効率的な画像管理、画像認識、画像理解 |
クラスタリングの課題

集団分けの技法は、データの背後にある構造を見つけるための強力な手段ですが、いくつかの難しさも抱えています。これらの難しさを理解し、適切な対応策を施すことで、より効果的な集団分け分析を行うことができます。
まず、集団の数をあらかじめ決めておく必要がある方法の場合、適切な集団の数を設定することが非常に難しいです。データの性質によっては、最適な集団の数が不明確な場合もありますし、分析者の主観によって結果が変わってしまう可能性もあります。例えば、顧客を購買行動に基づいて集団分けする場合、3つの集団に分けるのが良いのか、5つに分けるのが良いのか、判断が難しい場合があります。このような場合には、試行錯誤を繰り返しながら、最もデータの特徴を捉えていると思われる集団の数を選択する必要があります。
次に、データの尺度や雑音の影響を受けやすいという問題があります。例えば、ある変数の値が他の変数に比べて極端に大きい場合、その変数が集団分けの結果に過大な影響を与えてしまう可能性があります。また、データに雑音が多く含まれている場合、雑音によって本来の集団構造が覆い隠されてしまう可能性があります。このような場合には、データの尺度を調整したり、雑音を取り除くための前処理が必要となります。具体的な前処理としては、変数を標準化したり、異常値を除去したりする方法が挙げられます。
最後に、得られた集団の意味を理解することが難しい場合があります。集団分けによってデータがいくつかの集団に分けられたとしても、それぞれの集団が何を表しているのか、どのような特徴を持っているのかを解釈するのは容易ではありません。分析者の経験や知識に基づいて、それぞれの集団に適切な名前を付けたり、集団の特徴を説明したりする必要があります。例えば、顧客を年齢や収入に基づいて集団分けした場合、それぞれの集団に「若年層」「高所得者層」といった名前を付けることで、集団の意味を分かりやすくすることができます。このように、集団分けの結果を解釈するためには、分析者の洞察力が重要となります。
| 難しさ | 説明 | 対応策 | 例 |
|---|---|---|---|
| 集団数の決定 | 適切な集団数を事前に決めるのが難しい。分析者の主観に影響されやすい。 | 試行錯誤を行い、データの特徴を捉える最適な数を選択する。 | 顧客の購買行動に基づいた集団分けで、3つにするか5つにするかの判断。 |
| データの尺度や雑音の影響 | 特定の変数の値が大きすぎたり、データに雑音が多いと、結果が歪む。 | データの尺度調整、雑音除去のための前処理(標準化、異常値除去など)。 | 極端な値を持つ変数が結果に過大な影響を与える場合。 |
| 集団の意味の解釈 | 得られた集団の特徴や意味を理解するのが難しい。 | 分析者の経験や知識に基づき、各集団に名前を付けたり特徴を説明する。 | 年齢や収入による顧客の集団分けで、「若年層」「高所得者層」のような名前を付ける。 |
今後の展望

データの量は増え続け、種類も様々になってきています。それに伴い、集団分けの技術も進化していくと考えられます。これまで以上に複雑なデータの繋がり方にも対応できる仕組み作りや、邪魔な情報や場違いな情報に惑わされない強い方法の研究が盛んに行われています。まるで人間の脳のように情報を処理する技術と組み合わせた、新しい集団分けの方法も期待されています。
具体的には、従来の方法では難しかった、動画や音声、文章といったデータ形式にも対応できる集団分けの技術が求められています。これらのデータは、数値データとは異なり、複雑な構造や意味を持っているため、より高度な分析手法が必要となります。例えば、動画データであれば、映像の内容や登場人物の感情といった情報を考慮しながら、似たような動画をまとめていく必要があります。
また、大量のデータの中から、本当に重要な情報だけを取り出す技術も重要です。データの中に含まれる雑音や外れ値は、分析結果の精度を低下させる原因となるため、これらを適切に処理する必要があります。さらに、集団分けの結果を人間が理解しやすい形で示すことも重要です。複雑なデータ分析の結果を、分かりやすい図表やグラフで表現することで、より多くの人が分析結果を理解し、活用できるようになります。
このように、集団分けの技術は、様々な分野で応用され、新しい発見や革新的な技術を生み出す力を持っています。例えば、医療分野では、患者の症状や遺伝子情報を分析することで、より効果的な治療法を開発することができます。また、マーケティング分野では、顧客の購買履歴や嗜好を分析することで、より効果的な広告配信や商品開発を行うことができます。集団分け技術の進歩は、私たちの生活をより豊かに、より便利にする可能性を秘めています。
| 課題 | 詳細 | 例 |
|---|---|---|
| データ量の増加と多様化 | データ量が膨大になり、種類も多様化している。 | – |
| 複雑なデータの繋がり | データ間の関係性が複雑化している。 | – |
| ノイズへの対応 | 邪魔な情報や場違いな情報に惑わされないようにする必要がある。 | 雑音、外れ値 |
| 様々なデータ形式への対応 | 従来の数値データだけでなく、動画、音声、文章といったデータ形式にも対応する必要がある。 | 動画の映像内容、登場人物の感情、文章の意味 |
| 重要な情報の抽出 | 大量のデータから重要な情報だけを取り出す必要がある。 | – |
| 結果の可視化 | 分析結果を人間が理解しやすい形で示す必要がある。 | 図表、グラフ |
| 応用分野 | 様々な分野で応用され、新しい発見や革新的な技術を生み出す可能性がある。 | 医療、マーケティング |