データバランスの重要性:機械学習の精度向上

AIを知りたい
『バランス調整』って、AIの学習で何をすることですか?

AIエンジニア
簡単に言うと、AIの学習データの中に、ある種類の特徴を持つデータばかりが多くて、他の種類の特徴を持つデータが少ない場合、その量の偏りを調整することだよ。 例えば、猫の画像をAIに学習させたいのに、学習データの中に犬の画像が大量にあって猫の画像が少ない場合、猫の特徴をうまく学習できない可能性があるよね?
AIを知りたい
なるほど。偏りがあると、AIがうまく学習できないんですね。具体的にどうやって調整するんですか?
AIエンジニア
少ない種類のデータを人工的に増やしたり、多い種類のデータを減らしたりする方法があるよ。どの方法が一番良いかは、データの種類やAIの目的によって変わるんだ。重要なのは、AIが色々な種類の特徴をバランス良く学習できるようにすることだよ。
Balancingとは。
人工知能で使われる言葉で「均衡化」というものがあります。これは、学習に使うデータの中に、ある種類のデータが他の種類のデータよりも極端に多い場合の調整を指します。たとえば、猫と犬を見分ける人工知能を作るとして、学習データに猫の画像が100枚、犬の画像が1枚しかないといった状態です。これを「不均衡な種類」と呼び、機械学習ではきちんと考えなければいけない問題です。データの均衡化は、データ分析をする人にとって、ごく当たり前の作業です。もし、データの量の偏りをそのままにしておくと、分析の正確さが大きく下がったり、人工知能が偏った判断をするようになってしまうかもしれません。この問題に対処するには、少ない種類のデータを人工的に増やすなどの方法がありますが、最適な方法はデータの性質によって変わってきます。
はじめに

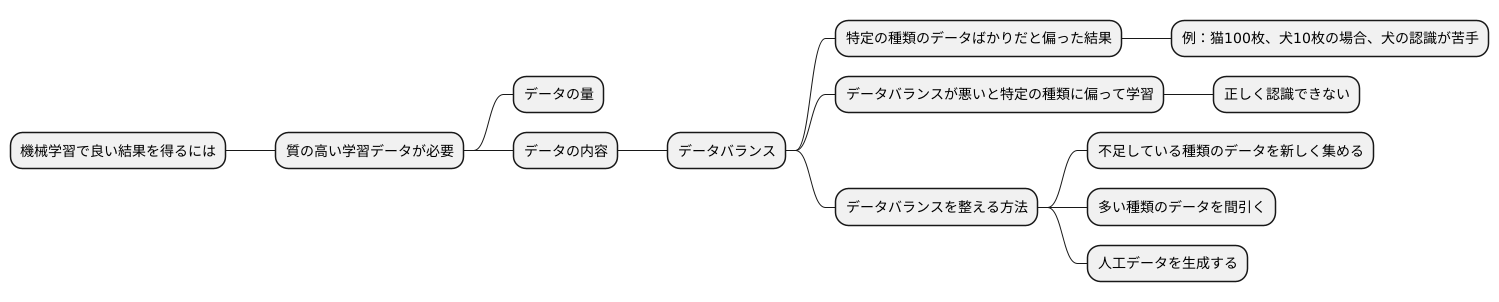
機械学習の世界では、良い結果を得るためには、質の高い学習データが欠かせません。データの質の高さを決める要素は様々ありますが、データの量だけでなく、データの内容にも注意を払う必要があります。いくら大量のデータを集めても、特定の種類のデータばかりが集まっていては、偏った結果しか得られません。
例えば、猫と犬を見分ける機械学習モデルを訓練する場合を考えてみましょう。学習データとして猫の画像が100枚、犬の画像が10枚しか集まらなかったとします。この場合、モデルは猫の特徴をより多く学習するため、犬を見つけるのが苦手になってしまうかもしれません。このように、学習データの種類ごとの量のバランス、つまりデータバランスが非常に重要なのです。
データバランスが悪いと、モデルは特定の種類のデータに偏って学習してしまい、他の種類のデータを正しく認識できないという問題が生じます。これは、まるで偏った情報ばかりを耳にして育った子供のように、正しい判断ができなくなってしまうようなものです。
データバランスを整えるためには、様々な方法があります。不足している種類のデータを新しく集める、あるいは多い種類のデータを間引くといった方法が考えられます。また、少ない種類のデータと似たような人工データを生成する技術も存在します。
機械学習で良い成果を上げるためには、データバランスに配慮することが不可欠です。データの量だけでなく、質にもこだわり、バランスの取れたデータセットを用意することで、より精度の高い、信頼できるモデルを作ることができるでしょう。
不均衡データの問題点

情報を扱う場面で、特定の種類のデータが他の種類に比べて極端に多い場合、これを『不均衡データ』と呼びます。この不均衡データは、様々な問題を引き起こす可能性があります。例えば、クレジットカードの不正利用を検出するシステムを考えてみましょう。通常、不正利用の件数は、正規利用の件数に比べてはるかに少ないです。このような偏ったデータを使ってシステムを学習させると、システムは数の多い正規利用のパターンばかりを学習してしまい、少ない不正利用のパターンをうまく学習できません。
これは、まるで、白い猫ばかり見て育った子供が、黒い猫を見たときに猫だと認識できないようなものです。システムは、データの偏りに合わせて学習してしまうため、数の少ないデータの特徴を捉えにくくなります。結果として、不正利用を見逃してしまう可能性が高まり、大きな損害につながる恐れがあります。
他にも、医療診断の分野でも同様の問題が起こり得ます。ある特定の病気の患者数は、健康な人に比べて非常に少ない場合があります。この場合、少ない患者データを使って診断システムを学習させると、システムは健康な人のパターンばかりを学習し、病気の人の特徴を捉えにくくなります。結果として、病気の早期発見が遅れ、適切な治療の機会を逃してしまう可能性があります。
このように、不均衡データは、システムの学習に悪影響を与え、予期せぬ結果を招く可能性があります。そのため、不均衡データを適切に処理することは、情報処理において非常に重要な課題となります。偏りをなくすための様々な方法が研究されており、例えば、少ないデータを人工的に増やす方法や、データの重み付けを変える方法などがあります。これらの方法を適切に用いることで、不均衡データによる問題を軽減し、より精度の高いシステムを構築することが可能になります。
| 問題 | 例 | 結果 |
|---|---|---|
| 不均衡データ | クレジットカード不正利用検知、医療診断 | システム学習への悪影響、予期せぬ結果 |
| 少数データ学習不足 | 不正利用検知で正規利用パターンばかり学習、医療診断で健康な人のパターンばかり学習 | 不正利用の見逃し、病気の早期発見の遅れ |
データバランス調整の必要性

機械学習を行う上で、学習に用いるデータの質は非常に重要です。学習データの質が低いと、精度の高い予測モデルを作ることができません。学習データの質に影響を与える要素の一つとして、データの偏り、つまりデータバランスの問題が挙げられます。例えば、病気の診断を行うモデルを開発する場合を考えてみましょう。診断対象の病気の発生率が非常に低い場合、学習データの大部分は「病気でない」というデータで占められることになります。このような偏ったデータで学習したモデルは、「病気でない」という予測に偏りがちになり、病気の兆候を見逃す可能性が高くなってしまいます。
このような問題を避けるため、データバランスの調整が必要となります。データバランス調整とは、各分類のデータ数を均等に近づけるための技術です。病気の診断の例で言えば、「病気である」データと「病気でない」データの数を調整することを意味します。データバランス調整には、いくつかの方法があります。例えば、少ない方のデータを複製して水増しする方法や、多い方のデータを間引いて削減する方法などが考えられます。また、データを人工的に生成することでバランスを調整することも可能です。どの方法が適切かは、データの特性やモデルの性質によって異なります。
適切なバランス調整を行うことで、モデルは全ての分類を平等に学習し、より正確な予測を行うことができるようになります。これは、モデルの汎化性能向上にもつながります。汎化性能とは、未知のデータに対しても正確な予測を行う能力のことです。データバランス調整によって、特定のデータに偏ることなく学習できるため、汎化性能の高い、安定した性能を発揮できるモデルを構築することができます。結果として、様々な状況において信頼性の高い予測結果を得ることが可能となります。
具体的な調整方法

データの偏りを調整する手法は様々ですが、大きく分けて二つの手法があります。一つは、少ないデータを増やす手法で、よく「水増し」と呼ばれています。この手法は、少ないデータと同じような特徴を持つデータを人工的に作り出すことでデータの数を増やします。例えば、少ない種類の画像データを増やす場合には、既存の画像を回転させたり、少し色を変えたり、あるいはノイズを加えたりすることで、新しい画像データを生成します。このようにして、少ないデータを人工的に増やすことで、データの偏りを解消することができます。
もう一つの手法は、多いデータを減らす手法で、よく「間引き」と呼ばれています。この手法は、多いデータの中から一部のデータを取り除くことで、データの数を減らします。例えば、ある種類のデータが非常に多く、他の種類のデータが少ない場合、多いデータの中からランダムにデータを削除することで、データの偏りを解消することができます。この手法は、単純ではありますが、場合によっては重要な情報が失われてしまう可能性があるため、注意が必要です。
水増しと間引き以外にも、近年ではより高度な調整技術が開発されています。これらの技術は、機械学習の手法を用いて、データの偏りをより効果的に解消することができます。例えば、少ないデータの特徴を学習し、その特徴に基づいて新しいデータを生成する手法や、データの分布を解析し、偏りを自動的に調整する手法などがあります。これらの高度な技術は、従来の手法よりも効果的にデータの偏りを解消できる場合が多いですが、計算に時間がかかる場合もあるため、状況に応じて適切な手法を選択する必要があります。適切な調整手法を選択することで、データの偏りによる悪影響を最小限に抑え、より正確な分析結果を得ることができます。
| 手法 | 説明 | メリット | デメリット |
|---|---|---|---|
| 水増し | 少ないデータを増やす。例えば、画像を回転、色変更、ノイズ付加など。 | 少ないデータを人工的に増やし偏りを解消できる。 | – |
| 間引き | 多いデータを減らす。多いデータからランダムに削除。 | 単純で実装しやすい。 | 重要な情報が失われる可能性がある。 |
| 高度な調整技術 | 機械学習を用いて偏りを解消。少ないデータの特徴学習、データ分布解析など。 | 従来手法より効果的に偏りを解消できる。 | 計算に時間がかかる場合がある。 |
データ特性に合わせた調整

機械学習モデルの精度は、学習に用いるデータの質に大きく左右されます。特に、分類問題においては、各分類のデータ数が大きく偏っている場合、モデルが偏った予測をする可能性が高くなります。これを防ぐためには、データの特性に合わせた調整、つまりデータの均衡化が不可欠です。
例えば、ある病気の診断モデルを開発する場合を考えてみましょう。病気の患者数は、健康な人に比べて非常に少ないのが一般的です。このようなデータでモデルを学習させると、モデルは健康な人ばかりを予測するようになってしまい、病気の患者を見逃してしまう可能性があります。このような状況では、少数派のデータ、つまり病気の患者のデータを人工的に増やす手法が有効です。これを過剰抽出と言い、少数のデータを複製したり、似たようなデータを生成することでデータ数を増やします。
一方、健康な人のデータが膨大にある場合、全てのデータを学習に用いると計算に時間がかかりすぎてしまう可能性があります。この場合は、多数派のデータ、つまり健康な人のデータを減らす手法が有効です。これを過少抽出と言い、データの中から一部を削除することでデータ数を減らし、計算の負担を軽減します。
データの均衡化には、過剰抽出と過少抽出以外にも様々な手法が存在し、どの手法が最適かはデータの特性によって異なります。例えば、データにノイズ(誤りや不確かな情報)が多い場合は、ノイズの影響を受けにくい手法を選ぶ必要があります。また、データの分布に偏りがある場合は、その偏りを考慮した調整が必要になります。熟練したデータ分析の専門家は、これらの要素を総合的に判断し、データの特性に最適な均衡化手法を選択することで、モデルの精度向上を目指します。適切な均衡化は、モデルが偏った予測をすることを防ぎ、より信頼性の高い結果を得るために重要です。
| データの均衡化 | 説明 | 適用場面 |
|---|---|---|
| 過剰抽出 (Oversampling) | 少数派のデータを人工的に増やす。少数のデータを複製したり、似たようなデータを生成する。 | 病気の診断など、少数派のデータが重要な意味を持つ場合。 |
| 過少抽出 (Undersampling) | 多数派のデータの一部を削除する。 | 多数派のデータが膨大で計算に負担がかかる場合。 |
| その他 | データの特性に合わせた様々な手法が存在する。 | データにノイズが多い場合、データの分布に偏りがある場合など。 |
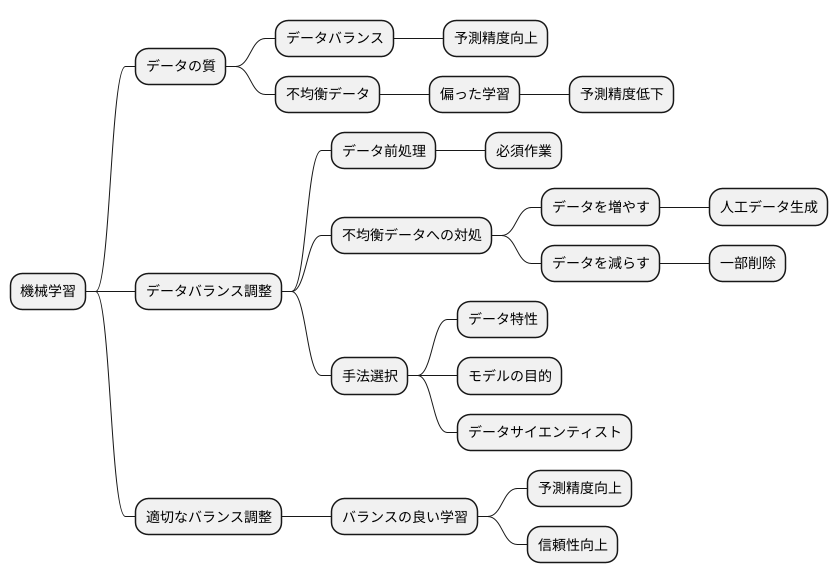
まとめ

機械学習の分野では、学習データの質がモデルの性能を大きく左右します。中でも、データのバランス、つまり各分類データの量の均衡は、モデルの精度と信頼性に直結する重要な要素です。もし特定の分類データが他の分類データに比べて極端に多い場合、偏った学習が行われ、予測の精度が低下する可能性があります。これを防ぐため、データバランスの調整は、データの前処理段階で必ず検討すべき重要な作業と言えます。
データのバランスが崩れている状態、つまり不均衡データとは、例えば、ある病気の診断モデルを学習させる際に、病気の症例データが健康な人のデータに比べて極端に少ないといった状況を指します。このようなデータで学習したモデルは、病気の症例を正しく診断できない可能性が高くなります。これは、モデルが多数派のデータの特徴に偏って学習してしまうためです。つまり、少ないデータの特徴を十分に学習できないことが原因です。
このような問題に対処するために、様々なデータバランス調整の手法が開発されています。例えば、少ないデータを人工的に増やす手法や、多いデータを減らす手法などがあります。少ないデータを人工的に増やす手法は、既存のデータの特徴を元に、似たようなデータを生成することでデータ量を増やす方法です。一方、多いデータを減らす手法は、多数派のデータの中から一部を削除することで、データのバランスを調整する方法です。どの手法が適切かは、データの特性やモデルの目的によって異なります。データサイエンティストは、データの状況を注意深く分析し、最適なバランス調整手法を選択する必要があります。
適切なバランス調整を行うことで、モデルは全ての分類データの特徴をバランス良く学習できるようになります。その結果、モデルの予測精度が向上し、より信頼性の高い結果を得ることが可能になります。これは、様々な分野における機械学習の応用において、実用的なモデルを構築するために不可欠な要素と言えるでしょう。常にデータバランスに気を配り、適切な調整を行うことで、高精度で信頼性の高い機械学習モデルを実現できます。