決定木:データ分析の強力な手法

AIを知りたい
先生、『決定木』って、何ですか?難しそうでよくわからないんです…

AIエンジニア
そうだね、最初は難しいかもしれないね。簡単に言うと、物事をいくつかの特徴で分けていくことで、最終的に答えを導き出す方法だよ。たとえば、果物を『赤い』『甘い』『丸い』といった特徴で分けていくと、最終的にリンゴやイチゴなどにたどり着ける、そんなイメージだよ。
AIを知りたい
あ!なんとなくわかりました!特徴で分けていくんですね!でも、その分け方はどうやって決めるんですか?
AIエンジニア
いい質問だね!どの特徴で分けるのが一番良いかを、コンピュータがデータを見ながら自動的に決めてくれるんだ。たくさんのデータから、一番うまく答えを導き出せるように分けていくんだよ。
決定木とは。
人工知能でよく使われる『決定木』について説明します。決定木は、どの特徴がどんな値を持っているかを順番に見ていくことで、枝分かれを作り、最終的に一つの結果を予測する方法です。例えるなら、木の根っこから出発して、枝分かれを進んでいくと、葉っぱの先端にたどり着き、そこで数値などの答えが得られます。それぞれの枝分かれは、ある特徴についての『もし~ならば』という条件で表されます。そのため、出来上がった予測の仕組みが分かりやすいのが特徴です。
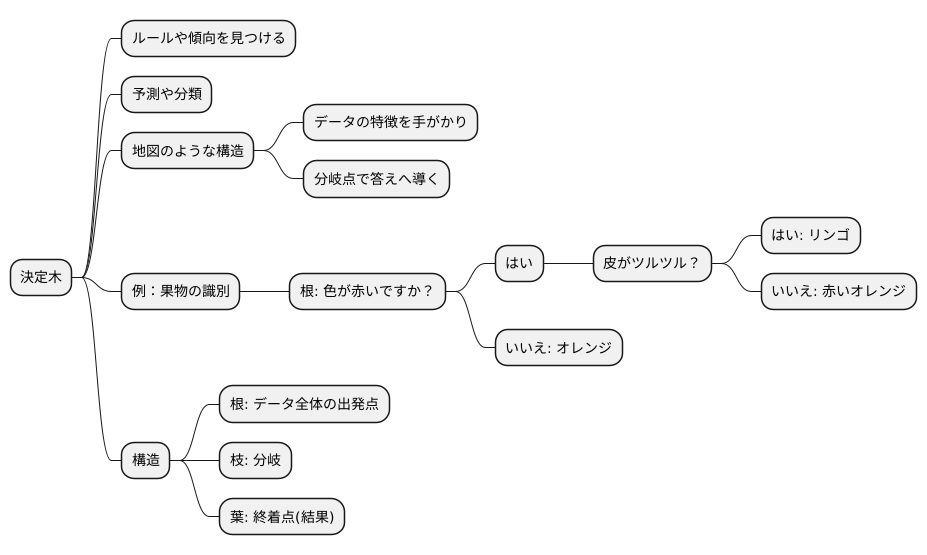
決定木の基本

決定木は、多くの情報から法則や傾向を見つけるために使われる手法で、予測や分類に役立ちます。まるで複雑な問題を解くための地図のように、データの特徴を手がかりに道筋を作り、答えへと導いてくれます。この道筋は、分岐点のある分かれ道のような構造をしています。
例として、ある果物をリンゴかオレンジかを見分ける場面を想像してみましょう。まず、果物の色を確認します。「色が赤いですか?」という質問に対して、「はい」であればリンゴ、「いいえ」であればオレンジと判断できます。しかし、中には赤いオレンジもあるかもしれません。そこで、次に「皮の表面はツルツルしていますか?」という質問を追加します。赤い果物の中でも、皮がツルツルしていればリンゴ、そうでなければ赤いオレンジの可能性が高いでしょう。このように、決定木は質問を繰り返すことで、データの特徴を段階的に絞り込み、最終的な答えを導き出します。この質問はデータの様々な特徴に基づいて行われ、「もし〇〇ならば、△△。そうでなければ、□□。」といった条件分岐を繰り返していきます。
決定木の構造は、根、枝、葉で表現されます。データ全体の出発点を「根」と呼び、そこから分岐していく部分を「枝」と呼びます。そして、最終的にたどり着く終着点を「葉」と呼びます。それぞれの葉には、予測された結果や分類された種類が割り当てられています。果物の例で言えば、最初の質問「色が赤いですか?」が根となり、「はい」と「いいえ」の二つの枝に分かれます。さらに「皮の表面はツルツルしていますか?」という質問が枝となり、最終的に「リンゴ」と「オレンジ」、そして「赤いオレンジ」という葉へとたどり着きます。このように、決定木は複雑な情報を分かりやすい形で整理し、問題解決を助けてくれる強力な手法と言えるでしょう。
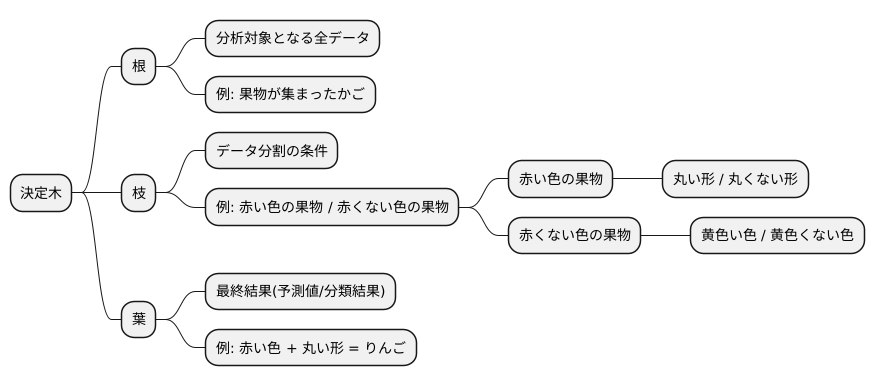
決定木の構造

決定木は、データを木構造で表現したものです。この木構造は、根、枝、葉という3つの主要な要素から成り立っています。まるで植物の根が地中深く広く伸び、枝が空に向かって広がり、葉が光合成を行うように、決定木もデータ分析において重要な役割を果たします。
まず、根にあたる部分は、分析対象となる全てのデータが集まっている場所です。すべてのデータはここから出発し、様々な条件によって枝分かれしていきます。例えるなら、たくさんの種類の果物が集まったかごのようなものです。このかごから、果物の特徴によって一つずつ分けていきます。
次に、枝は、データを分割するための条件を表しています。根から伸びる枝は、データのある特徴に基づいてデータをグループ分けします。例えば、果物のかごから、「赤い色の果物」と「赤い色でない果物」に分けるといった具合です。この枝分かれは、さらに続く枝によって、より細かくグループ分けされていきます。「赤い色の果物」の中から、「丸い形」と「丸くない形」に分けたり、「赤い色でない果物」の中から、「黄色い色」と「黄色い色でない色」に分けたりする、といった具合です。
そして最後に、葉は、最終的な結果を示す部分です。枝分かれを繰り返していくと、最終的に葉にたどり着きます。葉には、データの予測値や分類結果が示されます。果物の例で言えば、「赤い色」「丸い形」という条件を満たした果物は「りんご」である、といった具合です。
このように、決定木は、根から葉へと続く道筋を辿ることで、データの予測や分類を行います。それぞれの道筋は、データの特徴に基づいた一連の質問と答えの連鎖であり、複雑なデータを分かりやすく整理し、視覚的に表現することを可能にします。そして、新しいデータが来た時でも、この木構造を辿ることで、そのデータがどのグループに属するかを予測したり、分類したりすることができます。
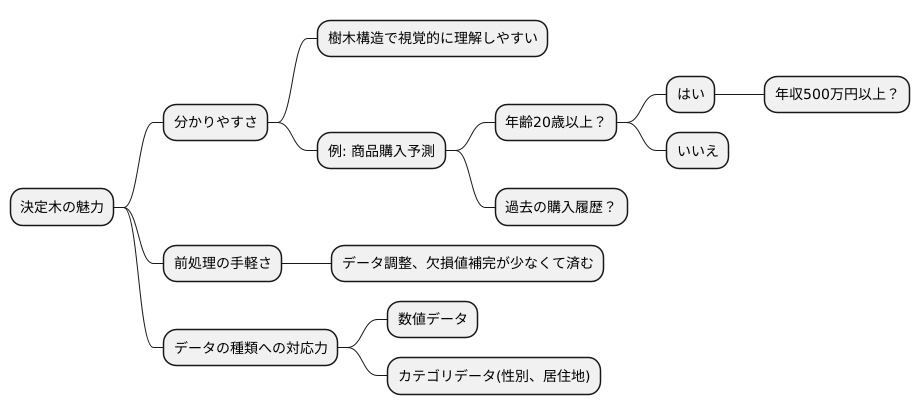
決定木の利点

決定木は、データ分析において、その分かりやすさが大きな魅力です。まるで樹木の枝のように、データの特徴に基づいて段階的に分岐していく構造をしているため、視覚的に理解しやすいという特徴があります。
例えば、ある商品を購入するかどうかを予測するモデルを作る場合を考えてみましょう。決定木では、「年齢は20歳以上か?」という問いから始まり、「はい」の場合は次の分岐に進み、「いいえ」の場合は別の分岐に進むといった具合に、条件分岐を繰り返していきます。それぞれの分岐は「年収は500万円以上か?」「過去の購入履歴はあるか?」といったように、私たちが普段使っている言葉で表現できるため、専門家でなくてもモデルの予測の過程を容易に追うことができます。これは、複雑な計算式を用いる他の手法にはない、決定木の大きな強みと言えます。
さらに、決定木は、データの前処理にあまり手間がかからない点もメリットです。多くの機械学習手法では、分析を行う前に、データを一定の範囲に収まるように調整したり、欠けている値を補完したりといった前処理が必要になります。しかし、決定木の場合は、これらの作業をそれほど念入りに行わなくても、ある程度の精度の予測モデルを作ることができます。そのため、データ分析の経験が少ない人でも、比較的簡単に利用することができます。
また、決定木は、数値データだけでなく、性別や居住地のようなカテゴリデータも扱うことができます。例えば、「性別が男性か女性か」といった条件も分岐に組み込むことが可能です。この柔軟性は、様々な種類のデータを取り扱う必要がある場面で、決定木を強力なツールにします。
このように、分かりやすさ、前処理の手軽さ、データの種類への対応力の高さといった多くの利点を持つ決定木は、データ分析の初心者から熟練者まで、幅広い層に利用されています。
決定木の欠点

決定木は、様々な分野で活用される有用な手法ですが、いくつかの弱点も抱えています。その一つが、学習しすぎることです。これは、訓練に使ったデータの特徴を細部まで捉えすぎてしまい、初めて見るデータに対してはうまく対応できない状態を指します。例えるなら、過去問の解答を丸暗記した生徒が、少し問題文が変わっただけで解けなくなってしまうようなものです。決定木は、データを完全に分類できるまで枝分かれを続けることができるので、このような過学習に陥りやすい性質を持っています。
二つ目の弱点は、データの小さな変化に影響されやすいことです。訓練に使うデータが少し変わっただけで、木の形が大きく変わってしまうことがあります。まるで、積み木の塔がちょっとした振動で崩れてしまうように、決定木の構造は不安定で、予測の信頼性を揺るがしかねません。
さらに、単純な関係しか捉えられないという弱点もあります。現実世界のデータは複雑な関係で繋がっていることが多く、例えば、気温とアイスクリームの売上の関係は単純な直線ではなく、ある気温までは売上は上がり続け、それを超えると逆に下がっていくでしょう。このような複雑な関係を、決定木はうまく表現できません。
これらの弱点を補うため、決定木を複数組み合わせるなどの工夫が用いられています。これは、様々な視点を持つ専門家の意見をまとめて、より精度の高い判断を下すようなものです。それぞれの木の弱点を補い合うことで、より良い予測結果を得ることができるのです。
| 弱点 | 説明 | 例え |
|---|---|---|
| 過学習 | 訓練データの特徴を細部まで捉えすぎてしまい、未知のデータにうまく対応できない。 | 過去問の解答を丸暗記した生徒が、問題文が少し変わっただけで解けなくなる。 |
| データの小さな変化に影響されやすい | 訓練データの小さな変化で、木の形が大きく変わってしまう。 | 積み木の塔がちょっとした振動で崩れてしまう。 |
| 単純な関係しか捉えられない | 複雑な関係をうまく表現できない。 | 気温とアイスクリームの売上の関係(ある気温までは売上は上がり続け、それを超えると逆に下がっていく)を表現できない。 |
決定木の応用例

決定木は、その分かりやすさと使い勝手の良さから、様々な分野で活用されています。まるで木の枝のように分岐していく構造で、様々な条件に基づいて判断を進めていくため、結果に至るまでの過程を理解しやすいという利点があります。
医療の分野では、患者の症状や検査結果といった情報から病気を診断する際に役立っています。例えば、熱があるかないか、咳が出るかどうかといった簡単な質問から始まり、段階的に病気を絞り込んでいくことができます。これにより、医師の診断を支援したり、患者の自己診断を助けるツールとしても活用されています。
金融業界では、顧客の信用力を評価する際に決定木が用いられています。年齢や収入、過去の借入状況といったデータから、顧客が返済能力を持っているかどうかを判断します。これにより、融資の可否や金利設定といった重要な決定を支援することができます。
商品の販売戦略を立てるマーケティング分野でも、決定木の活用が進んでいます。顧客の年齢や性別、購買履歴といったデータから、どのような商品に興味を持っているかを予測し、効果的な広告配信や商品推奨につなげることができます。
さらに、近年注目を集めている画像認識や自然言語処理といった分野でも、決定木は重要な役割を果たしています。画像に写っている物体を識別したり、文章の意味を理解する際に、決定木をベースとした高度な手法が開発されています。
このように、決定木は様々な分野で広く活用されており、データに基づいた意思決定を支援する強力な道具となっています。その解釈のしやすさと、様々な種類のデータに対応できる柔軟性から、今後も応用範囲はますます広がっていくと期待されています。
| 分野 | 決定木の活用例 |
|---|---|
| 医療 | 患者の症状や検査結果から病気を診断。医師の診断支援、患者の自己診断ツール。 |
| 金融 | 顧客の信用力評価。融資の可否や金利設定の決定支援。 |
| マーケティング | 顧客の属性や購買履歴から商品への興味を予測。効果的な広告配信や商品推奨。 |
| 画像認識/自然言語処理 | 画像認識、文章の意味理解といった高度な手法の基盤。 |
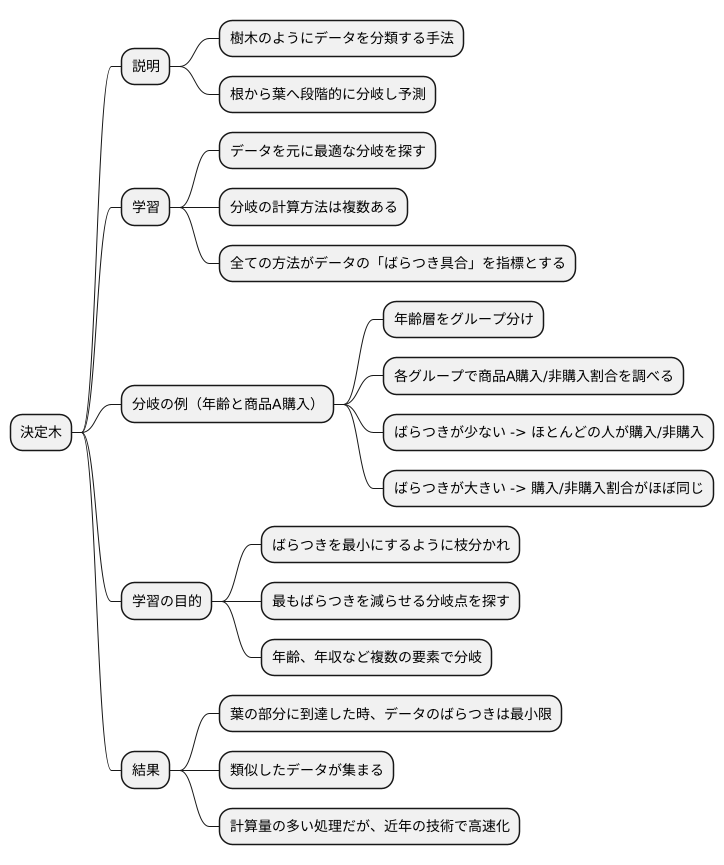
決定木の学習

決定木は、まるで樹木の枝のようにデータを分類していく手法です。根っこから幹、枝、そして葉へとデータが流れていくように、段階的に分岐していくことで予測を行います。この決定木を作る作業が、まさに決定木の学習にあたります。
決定木を学習するには、たくさんのデータが必要です。このデータを教材として、木をどのように枝分かれさせていくのが最適かを探し出すのです。この最適な分岐を見つけるための計算方法には、いろいろな種類があります。しかし、どの方法もデータの「ばらつき具合」を指標にしている点は共通しています。
たとえば、ある年齢層の人々が商品Aを買うか買わないかを予測したいとします。年齢層をいくつかのグループに分け、それぞれのグループで商品Aを買う人の割合と買わない人の割合を調べます。もし、ある年齢層のグループでほとんどの人が商品Aを買っているなら、そのグループは「ばらつきが少ない」と言えます。逆に、買う人と買わない人がほぼ同じ割合なら、「ばらつきが大きい」と判断できます。
決定木の学習は、このばらつきをなるべく小さくするように枝分かれを繰り返していく作業です。どの年齢で分岐するのが一番ばらつきを減らせるかを計算し、その年齢を分岐点として決定木を作っていきます。さらに、次の分岐では、別の要素、例えば年収などで同じようにばらつきが小さくなるように分岐していきます。
このようにして、葉の部分まで到達した時には、それぞれの葉に分類されたデータはできるだけばらつきが少なくなるように、つまり、同じような性質のデータが集まるように木が成長していくのです。この学習作業は、たくさんの計算が必要な複雑な作業ですが、近年のコンピュータ技術の進歩によって、膨大なデータからでも比較的高速に決定木を作ることができるようになりました。