
ブートストラップサンプリングで精度向上

AIを知りたい
『ブートストラップサンプリング』って、一部のデータを使うんですよね?どうして全部のデータを使わないんですか?

AIエンジニア
いい質問ですね。全部のデータを使うと、特定のデータに過剰に適合してしまう『過学習』という現象が起こる可能性があります。一部のデータを使うことで、様々なデータパターンに柔軟に対応できるようになります。
AIを知りたい
なるほど。でも、一部のデータだけだと、学習が不十分になるんじゃないですか?
AIエンジニア
ブートストラップサンプリングでは、ランダムに何度もデータを抽出するので、結果的に多くのデータが学習に使われます。また、それぞれの学習で異なるデータを使うことで、多様なモデルが作られ、より精度の高い予測が可能になります。
ブートストラップサンプリングとは。
『ブートストラップサンプリング』という、人工知能の分野でよく使われる言葉について説明します。これは、学習に全てのデータを使うのではなく、それぞれの決定木を作る際に、一部のデータを無作為に選んで学習させる方法のことです。
はじめに

機械学習という、まるで機械が自ら学ぶように見える技術は、世の中に溢れる様々な情報をうまく活用することで、私たちの生活をより便利で豊かにする可能性を秘めています。しかし、機械学習を行う上で重要なのが、学習させるためのデータの質と量です。十分な量の質の高いデータがあれば、精度の高い予測や判断を行うモデルを構築することができます。しかし、現実的には質の高いデータを大量に集めることは容易ではありません。限られたデータでいかに高精度なモデルを作るかが、機械学習における大きな課題となっています。
このような状況で、限られたデータを有効活用するための強力な手法の一つが「ブートストラップサンプリング」です。ブートストラップサンプリングは、元々統計学の分野で開発された手法ですが、近年の機械学習の進展に伴い、その重要性が再認識されています。
この手法は、手元にあるデータセットから重複を許してランダムにデータを抽出し、同じサイズの新しいデータセットを複数作成するというシンプルな仕組みです。まるで、手持ちの材料を組み合わせて、似たような料理をたくさん作るようなイメージです。それぞれの新しいデータセットは、元々のデータセットと全く同じではありませんが、元々のデータの特徴を反映しています。これらのデータセットを用いてそれぞれモデルを学習させ、最終的にそれらのモデルの予測結果を統合することで、より精度の高い頑健なモデルを構築することができます。
ブートストラップサンプリングは、データの偏りを軽減し、過学習を防ぐ効果があります。また、複数のモデルを組み合わせることで、個々のモデルの弱点を補い合い、全体的な性能を向上させることができます。特に、決定木のように結果が不安定になりやすいアルゴリズムと組み合わせることで、その効果が顕著に現れます。ブートストラップサンプリングは、まるで限られた食材から様々な料理を作り出す名料理人のように、限られたデータから最大限の価値を引き出す、機械学習における重要な技術と言えるでしょう。
手法の仕組み

この手法は、靴紐を引っ張って自らを空中に持ち上げるという意味を持つ言葉「ブートストラップ」に由来します。まるで少ないデータから多くのデータを作り出すかのように見えることから、このように名付けられました。具体的には、元のデータから何度も繰り返し、同じ大きさの新しいデータの集まりを作ります。
例として、100個のデータがあるとします。この手法では、元のデータから一つを選び、それを書き留めます。そして、選んだデータを元に戻し、再び100個の中から一つを選びます。これを100回繰り返すと、新しい100個のデータの集まりができます。
重要なのは、一度選んだデータを元に戻す点です。同じデータを何度も選ぶ可能性があるため、新しいデータの集まりには、元のデータと全く同じものが複数含まれる場合もあります。逆に、元のデータの一部が新しいデータの集まりに全く入らない場合もあります。これは、まるでサイコロを何度も振るように、偶然によってデータが選ばれるためです。
このようにして作った、似たようなデータの集まりをたくさん用意し、それぞれで学習を行います。そして、学習結果を組み合わせることで、一つ一つのデータの集まりで学習するよりも、より信頼性の高い結果を得ることができます。
さまざまなデータの組み合わせで学習することで、特定のデータに偏ることなく、様々な状況にも対応できるようになります。この手法は、データが少ない場合でも有効であり、限られた情報からより多くの知見を引き出すのに役立ちます。
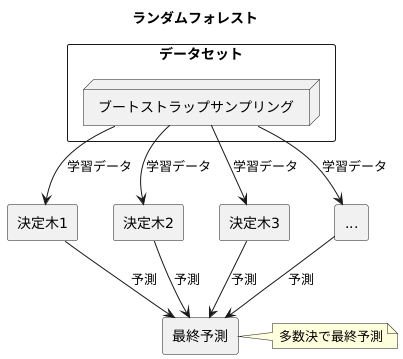
ランダムフォレストとの関係

ランダムフォレストは、複数の決定木を組み合わせることで高い予測精度と安定性を実現する手法であり、その中でブートストラップサンプリングは重要な役割を担っています。ランダムフォレストは、森のように多数の決定木を作り、それらの予測結果を統合することで最終的な判断を下します。個々の木は、データの一部だけを使って学習するため、それぞれ異なる特徴を持つようになります。
ブートストラップサンプリングは、データセットから重複を許してランダムにデータを取り出し、同じ大きさの新しいデータセットを作成する手法です。ランダムフォレストでは、このブートストラップサンプリングを使って、それぞれの決定木に学習させるためのデータセットを生成します。元のデータセットと同じ大きさの新しいデータセットを、何度も繰り返し作成することで、一つ一つの決定木が異なるデータで学習することになります。このように、一部のデータしか使わないこと、そして異なるデータで学習させることで、個々の決定木の過学習、つまり特定のデータの特徴に偏りすぎて新しいデータへの対応力が低くなることを防ぎます。
さらに、ランダムフォレストでは、決定木の分岐に使う特徴もランダムに選択します。これらのランダム性により、多様な決定木が生成され、全体としてより頑健で汎化性能の高いモデルが構築されます。ブートストラップサンプリングによって生成された多様な決定木が、それぞれの予測を持ち寄り、多数決のように最終的な予測を決定することで、単一の決定木よりも精度の高い、安定した予測が可能となります。ランダムフォレストは、様々な分野で活用されている強力な機械学習手法であり、ブートストラップサンプリングはその中核を担う重要な要素と言えるでしょう。
手法の利点

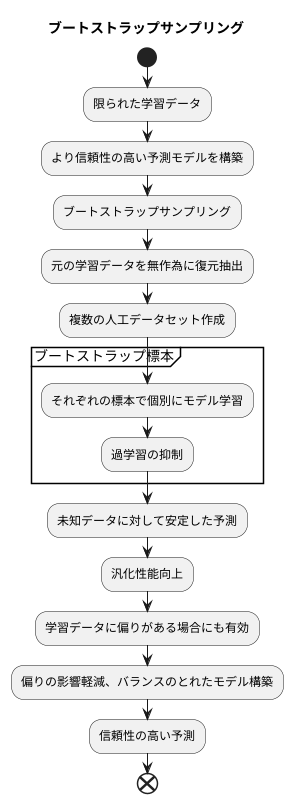
限られた量の学習データから、より信頼性の高い予測モデルを作る手法として、ブートストラップサンプリングは有効です。この手法は、もとの学習データを何度も無作為に復元抽出することで、複数の人工データセットを作成します。復元抽出とは、一度抽出したデータを元に戻してから次の抽出を行う方法です。つまり、同じデータが複数回抽出される可能性もあれば、全く抽出されないデータが存在する可能性もあります。こうして作られた一つ一つの人工データセットをブートストラップ標本と呼びます。それぞれのブートストラップ標本は、元の学習データと同じ数のデータを含みますが、データの組み合わせは様々です。
これらの多様なブートストラップ標本を用いて、それぞれ個別にモデルを学習させます。それぞれの標本ごとに異なるモデルが学習されることで、特定のデータの特徴に過剰に適応することを防ぎます。学習データだけに過剰に適応したモデルは、学習データには高い精度を示しますが、新しいデータに対してはうまく予測できないことが多く、これは過学習と呼ばれます。ブートストラップサンプリングは、この過学習を抑える効果があります。
それぞれのブートストラップ標本から学習された複数のモデルは、未知のデータに対しても安定した予測を行うことができます。これは、モデルの汎化性能が向上したことを意味します。
さらに、ブートストラップサンプリングは、学習データに偏りがある場合にも役立ちます。偏りのあるデータから学習したモデルは、その偏りを反映した予測をしてしまう可能性があります。しかし、ブートストラップサンプリングを用いることで、データの偏りの影響を軽減し、よりバランスのとれたモデルを構築することができます。結果として、より信頼性の高い予測が可能となります。
手法の限界

ブートストラップサンプリングは、統計学や機械学習の分野で広く使われている強力な手法です。観測データから何度も無作為にデータを抽出し、擬似的なデータセットをたくさん作り出すことで、もとのデータが少なくても、母集団の統計的な性質を推定したり、モデルの精度を評価したりできます。しかし、ブートストラップサンプリングは万能ではなく、いくつかの限界があります。
まず、元のデータに偏りがある場合、ブートストラップ法で作られるデータセットもまた、元のデータと同じ偏りを持ちます。例えば、ある地域の特定の年齢層の人々だけを対象に調査を行い、そのデータからブートストラップサンプリングを行うと、生成されるデータセットもまた、同じ年齢層に偏ったものになります。この偏りは、母集団全体の傾向を正しく反映しない可能性があり、分析結果の信頼性を損なう可能性があります。このような場合は、偏りを補正するための追加の処理、例えば、重み付けや層化抽出法などを検討する必要があります。
次に、計算コストの増加も考慮すべき重要な点です。ブートストラップサンプリングでは、何度もデータを抽出し、その度にモデルの学習や評価を行う必要があります。そのため、データセットが大きくなればなるほど、計算時間が増大します。特に、深層学習などの複雑なモデルを扱う場合、計算コストは非常に大きくなる可能性があります。限られた計算資源や時間的な制約の中でブートストラップサンプリングを行う場合は、サンプリングの回数やモデルの複雑さを調整するなど、計算資源と時間的な制約を考慮した適切な設定を行う必要があります。
まとめると、ブートストラップサンプリングは強力な手法ですが、データの偏りや計算コストといった限界があります。これらの限界を理解し、適切に対処することで、ブートストラップサンプリングをより効果的に活用できます。例えば、データの偏りを補正する手法を組み合わせたり、計算資源に合わせてサンプリングの回数を調整したりするなど、工夫が必要です。適用する際には、これらの点に注意を払い、必要に応じて他の手法と組み合わせるなど、柔軟な対応が求められます。
| メリット | デメリット | 対策 |
|---|---|---|
| 少数のデータから母集団の統計的な性質を推定できる | 元のデータの偏りが、ブートストラップデータセットにも反映される | 偏りを補正するための追加処理(重み付け、層化抽出法など) |
| モデルの精度を評価できる | 計算コストが増加する | サンプリング回数やモデルの複雑さを調整 |
まとめ

限られた量のデータから、より信頼性の高い予測モデルを構築することは、機械学習における重要な課題です。ブートストラップサンプリングは、この課題を解決するための強力な手法の一つです。元のデータセットから重複を許してランダムにデータを抽出し、同じサイズの新しいデータセットを複数作成します。これを擬似的なデータセットとして扱うことで、限られたデータからでも様々なデータのばらつきを再現し、モデルの精度を高めることができます。
ブートストラップサンプリングは、データの偏りを軽減する効果があります。元のデータに特定の傾向があったとしても、ランダムに抽出することでその影響を弱め、より一般化されたモデルを構築できます。これは、未知のデータに対しても安定した予測を行うために重要です。
ブートストラップサンプリングは、ランダムフォレストのようなアンサンブル学習手法と組み合わせることで、さらに大きな効果を発揮します。ランダムフォレストは、複数の決定木を組み合わせることで、高い予測精度を実現する手法です。それぞれの決定木は、ブートストラップサンプリングによって作成された異なるデータセットで学習されます。これにより、多様な決定木が生成され、予測の頑健性が向上します。個々の決定木の予測結果を統合することで、より正確で安定した予測が可能になります。
ブートストラップサンプリングは強力な手法ですが、いくつかの注意点もあります。例えば、元のデータに強い偏りがある場合、ブートストラップサンプリングでもその偏りを完全に解消できない可能性があります。また、多数の擬似的なデータセットを作成するため、計算コストが高くなる場合もあります。
このように、ブートストラップサンプリングはデータの量や質、計算資源などを考慮しながら適切に適用する必要があります。しかし、その効果と汎用性の高さから、機械学習の実践において非常に重要なツールと言えるでしょう。今後、データの規模がますます大きくなり、複雑化する中で、ブートストラップサンプリングはさらに重要な役割を担っていくと考えられます。