
バギングとランダムフォレスト

AIを知りたい
先生、バギングとランダムフォレストの違いがよくわからないのですが、教えていただけますか?

AIエンジニア
そうですね。バギングは、たくさんのデータを少しずつ分けて、それぞれで学習させて、みんなの結果を合わせる方法です。ランダムフォレストは、バギングの一種ですが、学習の際に使う情報もランダムに絞り込んでいます。
AIを知りたい
情報もランダムに絞り込むというのはどういうことでしょうか?
AIエンジニア
例えば、たくさんの情報から、今回はこの情報とこの情報だけを使って学習させる、というようにランダムに選ぶということです。そうすることで、より多様な結果が得られ、最終的な精度が向上することがあります。例えるなら、色んな人が色んな視点で考え、多数決をとることで、より良い答えに近づくようなイメージです。
バギングとは。
人工知能の用語で『バギング』というものがあります。バギングとは、データを復元抽出で何度も選び出し、たくさんの学習モデルを作ります。そして、それぞれのモデルが出した結果を多数決でまとめて、最終的な答えを出す方法です。ランダムフォレストは、決定木というモデルを使ってバギングを行います。さらに、それぞれのモデルを作る際には、使うデータの特徴もランダムに選びます。
バギングの概要

たくさんの学習器を組み合わせて、より賢い予測を生み出す方法、それが「バギング」です。まるで、様々な専門家の意見を聞き、最終的な判断を多数決で決めるようなものです。
バギングは、機械学習における「アンサンブル学習」という手法の一つです。アンサンブル学習とは、複数の学習器を組み合わせ、単体よりも優れた性能を目指す学習方法です。バギングは、このアンサンブル学習の中でも特に広く使われており、その高い汎用性と効果から多くの場面で活躍しています。
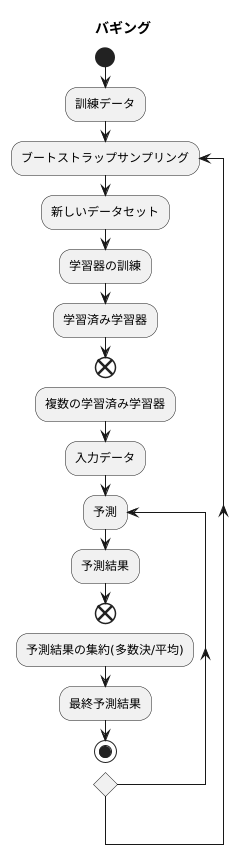
バギングの仕組みは、次のとおりです。まず、もとの訓練データから、重複を許してランダムにデータを取り出し、複数の新しいデータセットを作ります。これを「ブートストラップサンプリング」と言います。それぞれの新しいデータセットは、もとのデータと同じ大きさになりますが、データの一部は重複し、一部は含まれていない状態になります。
次に、それぞれの新しいデータセットを用いて、同じ種類の学習器を個別に訓練します。こうして作られた学習器は、それぞれ異なるデータで学習しているため、異なる視点を持つことになります。
最後に、これらの学習器に同じ入力データを与え、それぞれの予測結果を得ます。そして、これらの予測結果を多数決や平均値などで集約し、最終的な予測結果とします。
このように、バギングは多様な学習器の予測結果を組み合わせることで、個々の学習器の欠点を補い合い、より正確で安定した予測を実現します。特に、訓練データのわずかな変化に大きく影響される「不安定な学習器」、例えば決定木のような学習器に対して、バギングは非常に効果的です。バギングを用いることで、予測の精度と安定性が向上し、より信頼性の高い結果を得ることができるのです。
ランダムフォレスト

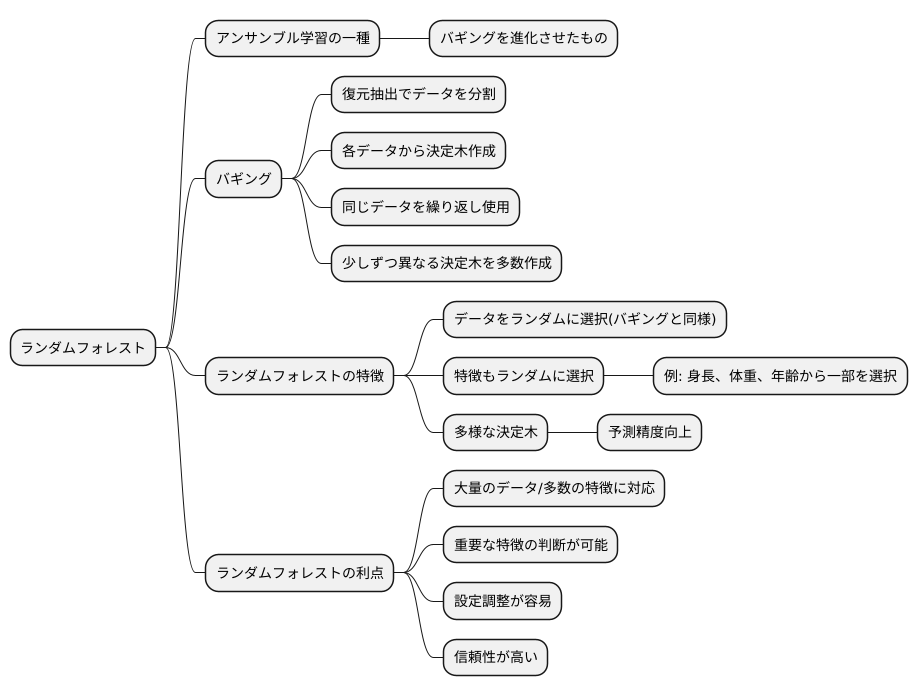
たくさんの木を組み合わせることで、森のように複雑な問題を解く方法、それがランダムフォレストです。この手法は、複数の決定木を組み合わせるアンサンブル学習という種類の学習方法の一つで、バギングという手法をさらに進化させたものと言えます。
バギングでは、データを復元抽出という方法でいくつかに分けて、それぞれのデータから決定木を作ります。まるで同じデータを何回も使って、少しずつ異なる決定木をたくさん作るようなイメージです。ランダムフォレストも、この考え方を引き継いでいます。しかし、ランダムフォレストは、さらに工夫を加えています。
ランダムフォレストでは、決定木を作る際に使うデータだけでなく、データの特徴もランダムに選びます。例えば、あるデータに身長、体重、年齢といった特徴があるとします。バギングでは、これらの特徴を全て使って決定木を作りますが、ランダムフォレストは、これらの特徴からいくつかをランダムに選び出して決定木を作ります。ある木は身長と体重だけ、別の木は年齢と体重だけ、といった具合です。
このように、データも特徴もランダムに選ぶことで、一つ一つの決定木の特徴がより際立ちます。まるで森の中に様々な種類の木が生えているように、多様な決定木が集まることで、全体としての予測精度が向上するのです。
さらに、ランダムフォレストは様々な利点を持っています。まず、大量のデータや多くの特徴を持つデータにも対応できます。また、どの特徴が予測に重要なのかを判断することも可能です。そして、設定を細かく調整する必要がないため、比較的簡単に利用できます。そのため、様々な分野で活用されている、信頼性の高い手法と言えるでしょう。
決定木の役割

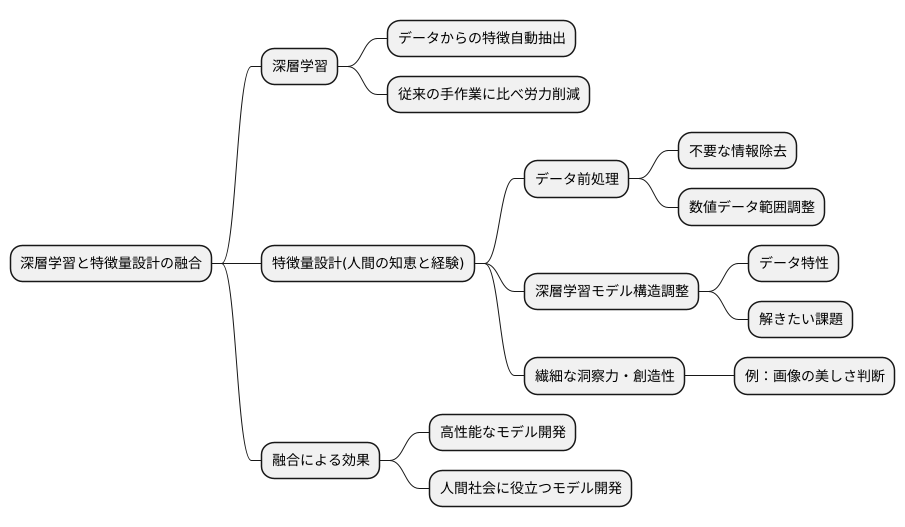
決定木は、物事を順序立てて判断していく木のような構造をもっています。まるで樹木の枝のように、データの特徴を一つずつ見ていき、条件に合うかどうかで経路を分岐させながら進んでいきます。最終的にたどり着いた葉の部分が、予測結果を表します。例えば、果物の種類を当てる決定木を考えてみましょう。最初の分岐で「色は赤いですか?」という問いがあり、「はい」の場合はリンゴ、「いいえ」の場合はバナナというように、段階的に絞り込んでいきます。
この決定木という手法は、人が理解しやすいという大きな利点があります。分岐の条件が明確なので、なぜその予測結果になったのかを説明しやすいのです。また、データの複雑な関係性も捉えることができます。例えば、果物の種類を当てる際に、色だけでなく大きさや形なども考慮することで、より正確な判断ができます。これは、直線的な関係だけでなく、曲線的な関係も表現できるということを意味します。
しかし、決定木には弱点もあります。それは、学習データに過剰に適応しすぎてしまう傾向があるということです。訓練データの細かな特徴にまで合わせ込んでしまうため、未知のデータに対してはうまく予測できないことがあります。これは、まるで特定の状況に特化した解答を丸暗記している生徒が、少し問題文が変わると解けなくなってしまうようなものです。
そこで、バギングやランダムフォレストといった手法が登場します。これらの手法は、複数の決定木を組み合わせて使います。それぞれの決定木は、異なるデータや特徴を使って学習するため、個々の木の偏りを抑えることができます。これは、複数の専門家の意見を聞き、総合的に判断することで、より正確な結論を導き出すことに似ています。さらに、決定木は計算の手間が少ないため、たくさんの木を効率よく学習させることができます。これは、大量の資料を扱う場合に特に役立ちます。
多様性の重要性

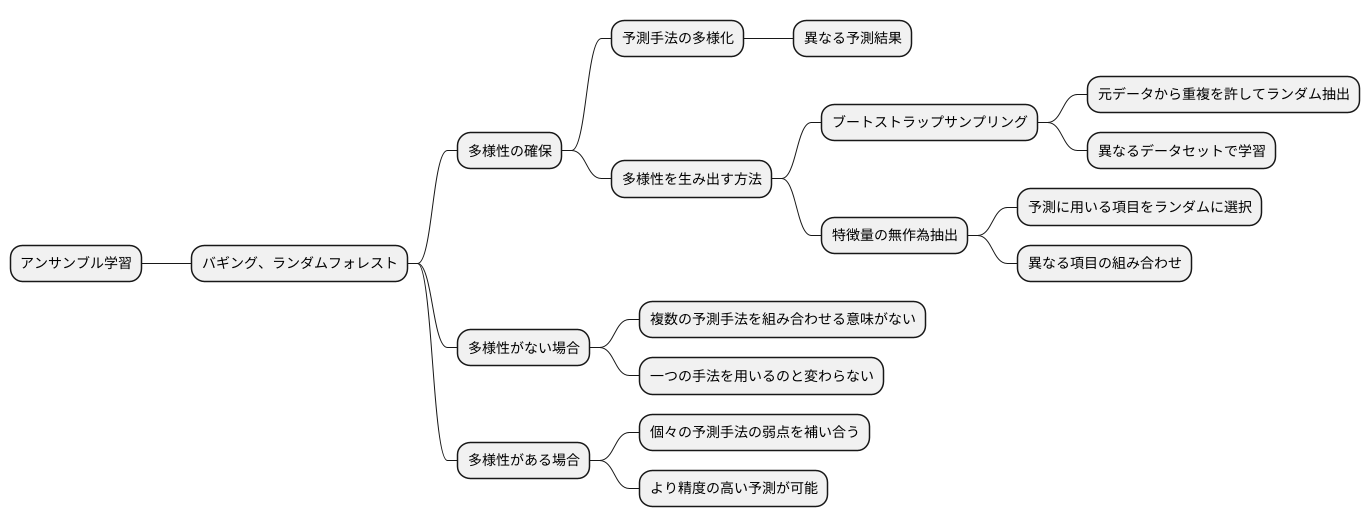
複数の予測手法を組み合わせる手法は、全体として高い予測精度を達成するために有効な手段です。これをアンサンブル学習と呼び、代表的な手法としてバギングやランダムフォレストがあります。これらの手法が高い効果を発揮する秘訣は、個々の予測手法の多様性を確保することにあります。
多様性とは、それぞれの予測手法が異なる予測結果を出すことを意味します。もし、全ての予測手法が同じ結果を出してしまうと、それらを組み合わせても予測精度は上がりません。多数決で最終的な予測を決める場合を考えてみてください。もし全員が同じ意見であれば、一人に意見を聞くだけで十分であり、複数の人に意見を聞く意味はありません。逆に、それぞれが異なる視点や考え方で意見を述べれば、より妥当な結論に至る可能性が高まります。
バギングやランダムフォレストでは、主に二つの方法で多様性を生み出しています。一つは、ブートストラップサンプリングと呼ばれる手法で、これは、元の学習データから一部を重複を許してランダムに抽出するものです。それぞれの予測手法は、こうして抽出された異なるデータセットで学習されるため、異なる予測結果を出すようになります。まるで、異なる経験を積んだ人が異なる判断をするように、学習データの違いが予測結果の多様性につながります。
もう一つは、特徴量の無作為抽出です。これは、予測に用いるデータの項目を、ランダムに選択する手法です。それぞれの予測手法は、異なる項目の組み合わせに着目して学習するため、これも多様性を高めることに貢献します。顔のパーツで例えるなら、ある予測手法は目と鼻に注目し、別の予測手法は口と耳に注目するといった具合です。このように、注目する情報を変えることで、多様な予測結果が得られます。
これらの工夫によって、予測手法間の多様性が確保され、アンサンブル学習の効果が最大限に発揮されます。多様性がなければ、複数の予測手法を組み合わせる意味はなく、一つの手法を用いるのと変わりません。多様性を高めることで、個々の予測手法の弱点を補い合い、より精度の高い予測が可能になります。
ブートストラップサンプリング

ブートストラップサンプリングとは、統計学や機械学習の分野でよく使われる技術で、限られた量のデータから多くの学びを得るための方法です。
この技術は、元のデータから同じ大きさの新しいデータの集まりをたくさん作ります。新しいデータの集まりを作る際は、元のデータから同じものを選んでも良いというルールで、くじ引きのようにランダムにデータを選びます。つまり、あるデータが何度も選ばれることもあれば、全く選ばれないこともあるということです。
この同じものを選んでも良いという点が、ブートストラップサンプリングの重要な特徴です。たとえば、1から10までの数字が書かれたくじを10枚用意し、1枚引いては数字を記録し、くじを戻すという作業を10回繰り返すとします。すると、同じ数字が複数回記録されることもあれば、ある数字は一度も記録されないこともあります。
ブートストラップサンプリングでもこれと同じことが起こります。こうして作った新しいデータの集まりは、元のデータとよく似ていますが、微妙に異なる部分があるため、それぞれ少しずつ違った特徴を持つことになります。
この技術は、複数の学習機械を訓練する際に特に役立ちます。それぞれの学習機械に少しずつ異なるデータの集まりを与えることで、各学習機械は異なる特徴を学習し、多様な予測を行うようになります。
ブートストラップサンプリングは、バギングやランダムフォレストといった、複数の学習機械を組み合わせる手法でよく使われます。限られたデータからより多くの情報を引き出し、予測の精度を高めるために、シンプルながらも強力な手法と言えるでしょう。
実用例

袋詰め法とランダム森法は、様々な分野で広く使われています。その汎用性と高い性能が理由です。
医療の分野では、病気の診断や治療方針を決めるのに役立っています。例えば、患者の症状や検査結果などのデータから、病気を正確に診断したり、最適な治療法を選択したりするために使われます。膨大な医療データから、これまで見落とされていた病気の兆候や治療効果の関連性を見つけ出すことも期待されています。
画像を認識する分野でも、物の検出や画像の分類などに使われています。自動運転の技術では、周りの状況を把握するために、カメラで撮影した画像から歩行者や車などを識別する必要があります。ランダム森法はこのような画像認識技術において、高い精度を実現するのに貢献しています。また、製造業では、製品の外観検査に画像認識技術が用いられています。ランダム森法によって、製品の欠陥を自動的に検出し、品質管理を向上させることができます。
お金を扱う分野では、信用リスクの評価や不正を検知するために使われています。例えば、融資の審査では、顧客の属性や過去の取引データから、返済能力を評価する必要があります。ランダム森法を用いることで、より正確なリスク評価を行い、貸し倒れのリスクを減らすことが可能になります。また、クレジットカードの不正利用を検知するためにも、ランダム森法が活用されています。不審な取引パターンを学習することで、不正利用を早期に発見し、被害を最小限に抑えることができます。
販売促進の分野では、顧客の購買行動を予測したり、宣伝広告の対象を絞り込んだりするために使われています。顧客の過去の購買履歴やWebサイトの閲覧履歴などのデータから、将来どのような商品を購入しそうかを予測することができます。この予測に基づいて、顧客一人ひとりに合わせたおすすめ商品を提示することで、購買意欲を高めることができます。また、効果的な広告配信にも役立ちます。
このように、袋詰め法とランダム森法は、実社会の様々な課題を解決するために役立っています。使いやすさと高い性能から、今後ますます多くの分野で活用されることが期待されます。特に、大量の情報と複雑な関係性を扱う必要のある分野において、袋詰め法とランダム森法は強力な道具となるでしょう。
| 分野 | 用途 | 具体例 |
|---|---|---|
| 医療 | 病気の診断、治療方針の決定 | 患者の症状や検査結果から病気を診断、最適な治療法を選択 |
| 画像認識 | 物の検出、画像の分類 | 自動運転における歩行者や車の識別、製品の外観検査 |
| 金融 | 信用リスク評価、不正検知 | 融資審査における返済能力評価、クレジットカード不正利用検知 |
| 販売促進 | 顧客の購買行動予測、広告ターゲティング | おすすめ商品の提示、効果的な広告配信 |