
変分オートエンコーダ:画像生成の新技術

AIを知りたい
先生、「変分オートエンコーダ」がよくわからないのですが、教えていただけますか?

AIエンジニア
そうだね。「変分オートエンコーダ」は、簡単に言うと、絵の特徴を覚えて、似た絵を新しく作り出すことができる技術だよ。たとえば、たくさんの猫の絵を覚えさせると、新しい猫の絵を描くことができるんだ。
AIを知りたい
猫の絵を覚えるということは、猫の特徴を覚えるということですね。どのようにして覚えるのですか?
AIエンジニア
良い質問だね。絵を分解して、重要な特徴を数値に変換する「エンコーダ」と、その数値から絵を復元する「デコーダ」という二つの部分があるんだ。エンコーダで特徴を抽出し、デコーダでその特徴から絵を再現することで、新しい絵を作り出せるんだよ。
変分オートエンコーダとは。
人工知能でよく使われる言葉に「変分自動符号化器」というものがあります。これは、学習データの特徴を覚えて、似たような画像を作ることができる技術です。仕組みとしては、まず「符号化器」という部分で元の画像を、その画像の特徴を表すデータに変換します。次に「復号化器」という部分で、変換されたデータから新しい画像を作ります。この特徴を表すデータは、元のデータの特徴をうまく捉えた分布になっていることが重要です。しかし、この特徴データを直接計算するのはとても難しいので、神経回路網を使って近似的に求めます。
変分オートエンコーダとは

変分自動符号化器(略して変分自動符号化器)は、近頃話題の人工知能の技術の一つで、絵や写真といった画像を機械が自動で作り出すことを可能にします。まるで人が様々な絵を参考にしながら新しい作品を描くように、この技術も多くの画像データから特徴やパターンを学び、それらを基に新しい画像を生み出します。
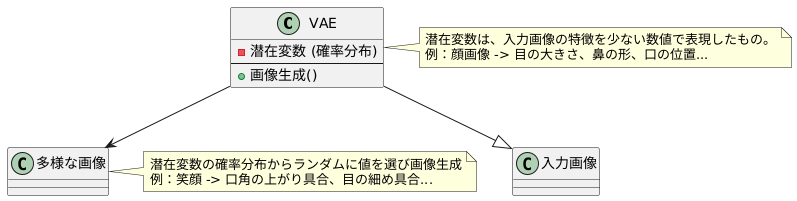
変分自動符号化器は、大きく二つの部分から成り立っています。一つは符号化器と呼ばれる部分で、これは入力された画像を、より少ない情報量で表現するための「潜在変数」と呼ばれるものに変換します。この潜在変数は、画像の重要な特徴を抽象的に表現したもので、例えば顔の画像であれば、目や鼻、口の位置や形といった情報が含まれます。もう一つは復号化器と呼ばれる部分で、これは符号化器で得られた潜在変数をもとに、元の画像を復元しようとします。
変分自動符号化器の最大の特徴は、潜在変数に確率的な要素を取り入れている点です。潜在変数は単なる数値ではなく、確率分布として表現されます。これにより、復号化器は潜在変数から様々な画像を生成することが可能になります。例えば、同じ顔の潜在変数であっても、少しだけ変化を加えることで、笑顔の顔や怒った顔など、様々な表情の顔を生成できます。これは、まるで画家が同じモチーフを元に様々なバリエーションの絵を描くようなものです。
この技術は、単に既存の画像を組み合わせるのではなく、学習した特徴を元に全く新しい画像を生成するという点で画期的です。そのため、娯楽、設計、医療など、様々な分野での活用が期待されています。例えば、新しいデザインの製品を生み出したり、病気の診断を支援したりといった応用が考えられます。今後、更なる発展が期待される技術です。

仕組みを理解する

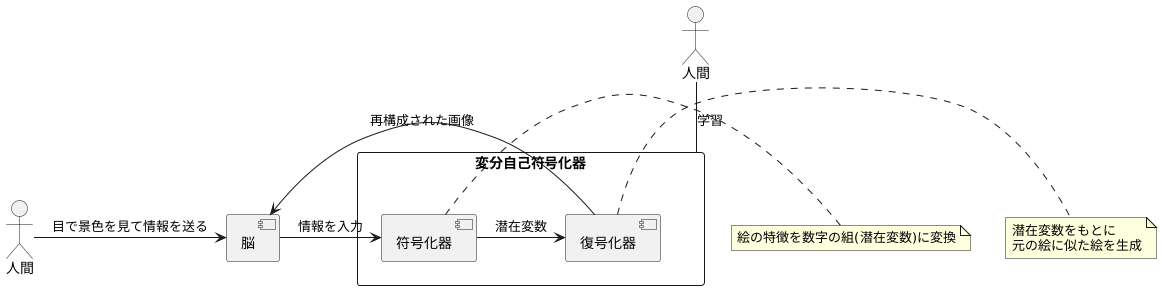
人の脳の働きを参考に作られた仕組みである、変分自己符号化器の働きについて説明します。
まず、人間の目は周りの景色を見て、脳に情報を送ります。脳は受け取った情報を整理して、重要な特徴だけを覚えます。変分自己符号化器では、この「情報を整理して、重要な特徴だけを覚える」という部分を「符号化器」という部品が担当します。符号化器は、入力された絵を細かく分析し、その絵の特徴をいくつかの数字の組に変えます。この数字の組を潜在変数と呼びます。
次に、脳は覚えた特徴を使って、見た景色の姿を思い出します。変分自己符号化器では、この「覚えた特徴を使って、景色を思い出す」という部分を「復号化器」という部品が担当します。復号化器は、符号化器が作った数字の組を受け取り、それを元に、もとの絵に似た絵を新しく作り出します。
変分自己符号化器の学習は、入力された絵と、復号化器が新しく作り出した絵の差が小さくなるように、符号化器と復号化器の部品を調整する作業です。学習を通して、符号化器と復号化器は少しずつ改良されていきます。
この学習によって、変分自己符号化器は絵の重要な特徴をうまく捉えられるようになるので、もとの絵に近い、質の高い絵を作り出せるようになるのです。たとえば、色々な人の顔の絵をたくさん学習させると、変分自己符号化器は「目」「鼻」「口」といった顔の特徴を学習します。そして、学習した特徴を組み合わせることで、実在しない人の顔の絵を新しく作り出すことができるようになります。このように、変分自己符号化器は新しい絵を作り出すことができるという点で、とても優れた技術だと言えます。
潜在変数の役割

変分自動符号化器(VAE)の肝となるのが「潜在変数」です。これは、入力された画像が持つ特徴を、少ない数の数値の集まりで表現したものです。例として、人の顔の画像を学習させる場合を考えてみましょう。このとき、潜在変数は目の大きさや、鼻の形、口の位置といった、顔の特徴を表す数値の集まりになります。これらの数値を調整することで、作り出される顔画像の表情や印象を自由に変えることができます。
VAEは、この潜在変数を確率分布として扱います。これが、多様な画像を生み出す鍵となっています。つまり、潜在変数は単に数値が集まったものだけでなく、画像の特徴がどのように分布しているかを示すものなのです。そして、この分布から潜在変数をランダムに選び出すことで、様々なバリエーションの画像を作り出すことができるのです。
具体的に説明すると、例えば「笑顔」の画像を学習させたとします。潜在変数には、口角の上がり具合や目の細め具合といった情報が含まれます。これらの数値が、平均値を中心としたある範囲に分布しているとします。VAEは、この分布に従って潜在変数をランダムに選び出し、画像を生成します。分布の平均値に近い数値が選ばれれば、典型的な「笑顔」の画像が生成されます。一方、分布の端の方の数値が選ばれれば、より誇張された笑顔や、少し控えめな笑顔など、様々なバリエーションの笑顔が生成されるのです。
これは、まるで画家が様々な表情やポーズを描くのと同じです。画家は頭の中で理想の表情やポーズを思い描き、それをキャンバスに表現します。VAEも同様に、潜在変数を操作することで、多様な画像を創造できるのです。このように、潜在変数はVAEが持つ創造力の源泉と言えるでしょう。
学習の難しさ

学習には様々な困難が伴いますが、中でもVAE(変分自己符号化器)の学習は特に難しいものです。VAEは、データをより少ない情報量で表現するための技術であり、その学習過程は複雑な計算を伴います。
VAEは、隠れた変数を確率的な分布として捉えるという特徴があります。しかし、この隠れた変数の分布を直接計算することは非常に困難です。そのため、VAEでは「変分推論」と呼ばれる手法を用いて、この隠れた変数の分布を近似的に求めます。VAEの名前の由来も、まさにこの「変分推論」からきています。変分推論を用いることで、複雑な隠れた変数の分布を効率的に学習することが可能になります。
具体的には、人工の脳を模した仕組みである「ニューラルネットワーク」を用いて、隠れた変数の分布を近似する関数を学習します。この関数を最適化することで、真の隠れた変数の分布にできるだけ近い分布を推定することが目指されます。この学習過程は、例えるならば、広大な迷路の中で最適な出口を探すようなものであり、複雑な最適化問題を解くことに相当します。そのため、高度な計算技術が必要とされます。
さらに、VAEの学習には、適切な調整が必要です。学習がうまくいかない場合、様々な要因が考えられます。例えば、ニューラルネットワークの構造が適切でない場合や、学習データの質が悪い場合などが挙げられます。このような問題を解決するためには、試行錯誤を繰り返しながら、最適な設定を見つける必要があります。そのため、VAEの学習には、深い知識と経験が求められるのです。
| 項目 | 説明 |
|---|---|
| VAE (変分自己符号化器) | データをより少ない情報量で表現する技術。学習が難しい。 |
| 隠れた変数 | 確率的な分布として捉えられる。直接計算が困難。 |
| 変分推論 | 隠れた変数の分布を近似的に求める手法。VAEの名前の由来。 |
| ニューラルネットワーク | 隠れた変数の分布を近似する関数を学習する人工の脳を模した仕組み。 |
| 学習の難しさ | 複雑な最適化問題を解く必要があるため、高度な計算技術が必要。適切な調整(ニューラルネットワーク構造、データの質)も重要。 |
画像生成への応用

変分自動符号化器(VAE)は、画像を作り出す技術として、様々な分野で活用されています。まるで画家が様々な絵を描くように、VAEも多様な画像を生み出せます。
例えば、人の顔の画像を新しく作り出すことができます。これは、実在しない人物の顔や、特定の条件に合う顔(例えば、笑顔の女性、高齢の男性など)を生成することを意味します。また、手書きの文字を生成することも可能です。学習データとして様々な手書き文字を与えれば、VAEはそれらの特徴を捉え、新しい手書き文字を作り出せます。さらに、物体の立体模型を作ることも可能です。これは、物体の形や質感などを学習し、コンピュータ上で3次元モデルを生成することを指します。
VAEの技術は常に進化しており、より高品質な画像生成を可能にする改良型も開発されています。より鮮明で、よりリアルな画像を作り出すために、様々な工夫が凝らされています。例えば、敵対的生成ネットワーク(GAN)と呼ばれる技術と組み合わせることで、より本物に近い画像を生成する手法も研究されています。GANは、VAEが生成した画像を評価する役割を担い、まるで画家の先生のように、より自然でリアルな画像生成を促します。
VAEは、単に画像を複製するだけでなく、画像の特徴を学習し、その特徴に基づいて新しい画像を生成するという点で、従来の画像生成技術とは大きく異なります。これは、画家が様々な絵画を参考にしながら、独自の表現で新しい絵を描くことに似ています。VAEは、学習データから得られた特徴を組み合わせたり、変化させたりすることで、全く新しい画像を生み出すことができます。この革新的な技術は、今後ますます発展し、様々な分野で画期的な応用が期待されています。例えば、エンターテイメント、デザイン、医療など、幅広い分野での活用が考えられます。
| 機能 | 説明 | 改良型 |
|---|---|---|
| 顔画像生成 | 実在しない人物の顔や特定の条件に合う顔(例:笑顔の女性、高齢の男性)を生成 | GANとの組み合わせ:VAEが生成した画像をGANが評価することで、よりリアルな画像生成が可能 |
| 手書き文字生成 | 学習データに基づいて、新しい手書き文字を生成 | |
| 立体模型生成 | 物体の形や質感などを学習し、コンピュータ上で3次元モデルを生成 |
今後の展望

変分自己符号化器(VAE)は、これからの画像を作り出す技術の中心となる大切な技術です。まるで画家が様々な絵を描くように、VAEはコンピュータの中で新しい画像を生み出します。この技術は、今後ますます発展していくと見られています。なぜなら、コンピュータの計算能力はどんどん上がっていて、VAEの仕組みも改良され続けているからです。これによって、今よりももっと精巧で、様々な種類の画像が作れるようになるでしょう。例えば、写真のようにリアルな絵や、想像上の生き物の絵、あるいは芸術的な抽象画なども、VAEによって生み出されるかもしれません。
VAEの使い道は、ただ絵を描くだけではありません。VAEは、普段とは違う様子を見つけることにも役立ちます。例えば、工場で作られた製品の中に、壊れたり傷ついたものがないか探すことができます。また、病院で撮った体の写真から、病気の部分を見つけるのにも役立ちます。このように、VAEは、ものづくりや医療といった様々な分野で活躍が期待されています。最近では、VAEを他の機械学習の技術と組み合わせる研究も進んでいます。他の技術と組み合わせることで、もっと難しい問題を解決できる可能性があるからです。例えば、自動運転の車にVAEを組み込めば、周りの状況をより正確に理解し、安全な運転ができるようになるかもしれません。
このように、VAEは様々な可能性を秘めた技術です。今後、VAEは人工知能の進歩に大きく貢献し、私たちの生活をより豊かにしてくれるでしょう。VAEは、まるで魔法の筆のように、未来の絵を描いていくのです。
| 項目 | 説明 |
|---|---|
| 概要 | VAEは、画像生成の中心技術であり、今後、コンピュータの計算能力向上と技術改良により、さらに発展が期待される。 |
| 将来の可能性 | より精巧で多様な画像生成(リアルな絵、想像上の生き物、抽象画など) |
| 応用分野 |
|
| 今後の発展 | 他の機械学習技術との組み合わせにより、より複雑な問題解決への貢献、人工知能の進歩、生活の向上 |