
オートエンコーダ:データ圧縮と特徴表現学習

AIを知りたい
オートエンコーダって、次元削減の手法だっていうのはなんとなくわかるんですけど、過学習の防止にも役立つってどういうことですか?

AIエンジニア
良い質問だね。オートエンコーダは、情報を一度圧縮して、それから元に戻そうとするところがポイントなんだ。たとえば、たくさんの絵を覚えるとき、全部をそのまま覚えるんじゃなくて、重要な特徴だけを覚えて、それからそれを元に絵を再現するようなイメージだよ。
AIを知りたい
重要な特徴だけを覚えるっていうのが、過学習の防止に繋がるんですか?
AIエンジニア
そうだよ。細かい情報に囚われすぎずに、本質的な特徴を捉えることで、未知の絵に対しても、うまく対応できるようになるんだ。つまり、データの細かなノイズに過剰に反応しなくなるので、過学習を防ぐ効果があると言えるんだよ。
オートエンコーダとは。
人工知能でよく使われる言葉に「自動符号化器」というものがあります。これは、データの大きさを縮小する方法の一つです。人工知能の仕組みの一つである神経回路網では、複雑な情報を扱うため、学習に使ったデータにぴったり合いすぎてしまい、新しいデータに対応できない「過学習」という問題が起こりやすくなります。自動符号化器は、神経回路網の中間層で一度情報を圧縮し、それを元の大きさに戻すことで、データの特徴を抽象的に捉えることができ、過学習を防ぐのに役立つとされています。
概要

自動符号化器とは、人の手を借りずに学習を行うことで、情報の要約と特徴の抽出を同時に行うことができる人工神経回路網の一種です。 この回路網は、入力された情報をより少ない情報量で表現できるように圧縮し、その後、その圧縮された表現から元の情報を復元しようと試みます。
例えるならば、たくさんの書類の山の中から重要な情報だけを抜き出し、小さなメモ用紙に書き留めるようなものです。その後、そのメモ用紙を見ながら、元の書類の山にあった内容を思い出そうとする作業に似ています。自動符号化器もこれと同じように、大量のデータから重要な特徴だけを抽出し、少ない情報量で表現します。そして、その少ない情報から元のデータの復元を試みる過程で、データの持つ本質的な構造を学習していくのです。
この学習過程で、自動符号化器はデータに含まれる雑音を取り除いたり、データの次元を削減したりする能力も獲得します。雑音を取り除くとは、書類の山に紛れ込んだ不要な紙を取り除く作業、次元を削減するとは、書類の山を整理して、より少ない種類の書類にまとめる作業に例えることができます。つまり、自動符号化器は、データの本質的な特徴を捉えることで、データの整理やノイズ除去といった作業を自動的に行うことができるのです。
このように、自動符号化器は、データの圧縮と復元を通して、データの持つ隠された特徴を学習し、様々な応用を可能にする強力な道具と言えるでしょう。まるで、複雑な情報を一度ぎゅっと握りしめ、それから再びそれを開くことで、本当に必要な情報だけを手に残すような、巧妙な技を持っていると言えるでしょう。
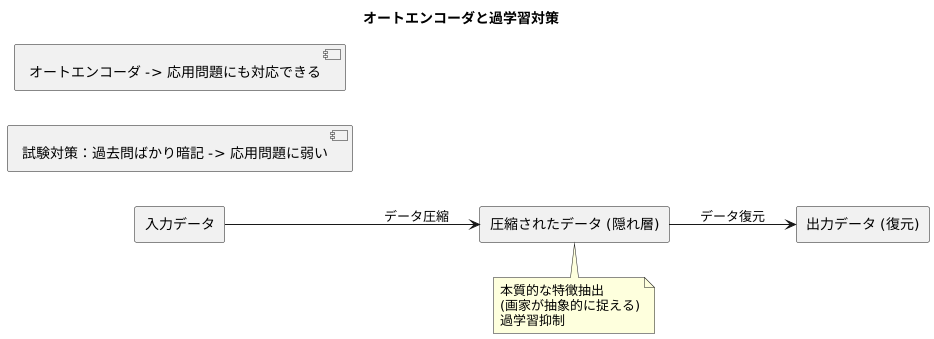
仕組み

自動符号化器は、符号化器と復号化器という二つの主要な部分から出来ています。
まず、符号化器について説明します。符号化器は、入力されたデータを受け取ります。そして、そのデータの特徴を保持しながら、より少ない情報量で表現するように変換します。この変換されたデータのことを潜在空間と呼びます。潜在空間は、入力データの重要な特徴を、ギュッと凝縮した表現と言えます。例えば、たくさんの文章を要約して、短いメモにするような作業をイメージすると分かりやすいでしょう。この作業こそが、符号化器の役割です。
次に、復号化器について説明します。復号化器は、符号化器が作った潜在空間を受け取ります。そして、その潜在空間をもとに、元の入力データを再現しようとします。先ほどの例で言えば、短いメモから元の文章を復元するような作業です。もちろん、完全に元の文章と同じにはなりません。しかし、重要な情報は残っているので、復元された文章は大まかな内容を捉えているはずです。
このように、符号化器と復号化器を組み合わせることで、自動符号化器はデータの重要な特徴を抽出しながら、データの圧縮と復元を同時に行うことができます。これは、まるで翻訳者が一度原文を要約し、それからその要約に基づいて原文を再現しようとする作業に似ています。つまり、一度情報を圧縮し、それから展開するという手順を踏むことで、データの核となる特徴を浮かび上がらせることができるのです。

過学習への対応

機械学習において、学習に使ったデータに過度に適合しすぎてしまい、新たなデータに対してうまく対応できないという問題がよく発生します。これを過学習と言います。ちょうど、試験対策として過去問ばかりを暗記し、試験本番では応用問題に対応できないような状態です。特に、ニューラルネットワークは表現力の高さがゆえに、この過学習に陥りやすい性質があります。
この過学習への対策の一つとして、オートエンコーダという手法が有効です。オートエンコーダは、データを一度圧縮し、それから元の形に戻すという仕組みを持っています。例えるなら、たくさんの荷物を小さな箱に詰め込み、その後、再び箱から取り出すようなものです。この過程で、本当に必要な情報だけが残ります。
オートエンコーダでは、隠れ層と呼ばれる層で情報を圧縮することで、データの本質的な特徴を抽出します。これは、画家が対象物を描く際に、一度抽象的に捉え、それから具体的な絵を描くのと似ています。細部にとらわれず、対象物の本質を捉えることで、より汎用的な表現が可能になります。
オートエンコーダによって抽出された本質的な特徴は、過学習を抑制し、未知のデータに対しても高い精度で予測できるモデルの構築に役立ちます。つまり、過去問だけでなく、応用問題にも対応できる能力を身につけることができるのです。これは、モデルの汎化性能の向上につながります。
このように、オートエンコーダは、データの本質を捉え、過学習を抑制することで、より信頼性の高い予測モデルを構築するための強力な手法と言えるでしょう。
様々な種類

情報の自動圧縮と復元を担う仕組み、それが自動符号化器です。まるで職人が様々な道具を使い分けるように、自動符号化器にも多くの種類があり、それぞれ異なる目的や特性に合わせた使い分けが必要です。
最も基本的な自動符号化器は、入力された情報をそのまま出力する、いわば鏡のような役割を担います。これは、情報の本質的な特徴を捉え、無駄な情報を削ぎ落とすための土台となります。この基本形を応用し、様々な機能を持つ自動符号化器が開発されています。
例えば、あえて入力情報に雑音を加え、そこから元の情報を復元するように学習させる雑音除去型自動符号化器があります。これは、まるで汚れた写真から元のきれいな景色を復元するような作業です。この技術は、データに含まれるノイズを取り除き、より鮮明な情報を得るために役立ちます。
また、入力情報の一部を隠して、隠された部分を予測するように学習させる変分型自動符号化器もあります。これは、パズルの欠けたピースを推測して埋めるような作業です。この技術は、データの欠損部分を補完したり、新たなデータを生成したりするために利用できます。
このように、自動符号化器は多種多様であり、データの特性や分析の目的に最適な種類を選択することが重要です。適切な自動符号化器を用いることで、データに隠された価値ある情報を引き出し、新たな発見へと繋げることができます。
| 自動符号化器の種類 | 機能 | 例え |
|---|---|---|
| 基本型 | 入力情報をそのまま出力 | 鏡 |
| 雑音除去型 | 雑音を加えた入力から元の情報を復元 | 汚れた写真から元の景色を復元 |
| 変分型 | 入力情報の一部を隠して、隠された部分を予測 | パズルの欠けたピースを推測して埋める |
応用例

様々な分野で活用されている技術である、自己符号化器について説明します。自己符号化器とは、入力された情報を一度圧縮し、その後元の情報に復元するように学習された仕組みのことです。まるで、一度折りたたんだ紙を再び開くように、情報を一度圧縮して、また広げるのです。この自己符号化器は、様々な場面で応用されています。
例えば、画像のノイズ除去に活用できます。画像に含まれる不要なノイズを取り除き、より鮮明な画像を生成します。雨や霧でぼやけた写真も、自己符号化器によって鮮明になるかもしれません。
また、高次元データを低次元データに変換する次元削減にも役立ちます。膨大な量のデータも、自己符号化器によって重要な情報だけを抽出し、データの可視化や処理の効率化を実現できます。たくさんの情報の中から必要な情報だけを選び出す、まさにデータ整理の達人です。
さらに、異常検知にも応用できます。正常なデータから学習した自己符号化器を用いることで、普段とは異なる異常なデータを見つけ出します。いつもと違うデータを検知することで、機械の故障予兆検知や不正アクセス検知などに役立ちます。
そして、特徴表現学習にも使われます。自己符号化器によって学習した潜在表現は、他の機械学習の入力として用いることで、性能の向上に繋がります。他の機械学習を助ける、縁の下の力持ちと言えるでしょう。
このように、自己符号化器は様々な分野で応用されている強力な技術です。まるで万能ナイフのように、様々な問題解決に役立ちます。
| 応用分野 | 説明 |
|---|---|
| ノイズ除去 | 画像に含まれる不要なノイズを取り除き、より鮮明な画像を生成する。 |
| 次元削減 | 高次元データを低次元データに変換し、データの可視化や処理の効率化を実現する。 |
| 異常検知 | 正常なデータから学習し、普段とは異なる異常なデータを見つけ出す。機械の故障予兆検知や不正アクセス検知などに役立つ。 |
| 特徴表現学習 | 自己符号化器によって学習した潜在表現は、他の機械学習の入力として用いることで、性能の向上に繋がる。 |
今後の展望

自動符号化器は、まるで成長を続ける若木のように、今後ますます発展し、様々な分野で活躍していくことが期待されています。現在も研究開発が盛んに行われており、その応用範囲は広がり続けています。特に、深層学習との組み合わせは、自動符号化器の性能を飛躍的に向上させる可能性を秘めています。幾重にも積み重ねられた層を持つ深層学習モデルと組み合わせることで、これまで以上に複雑なデータの構造を捉え、より精度の高い符号化と復号化を実現できるようになると考えられます。
例えば、画像認識の分野では、深層学習を用いた自動符号化器は、画像に含まれるノイズを除去したり、画像を圧縮したりするだけでなく、画像の特徴を自動的に抽出し、分類することも可能にします。これは、大量の画像データを扱う必要がある医療診断や自動運転技術などへの応用が期待されています。また、自然言語処理の分野でも、深層学習を用いた自動符号化器は、文章の要約や機械翻訳などのタスクで高い性能を発揮することが期待されます。
さらに、従来の自動符号化器では扱うことが難しかった、より複雑なデータへの適用も研究が進んでいます。例えば、時系列データやグラフ構造を持つデータなど、複雑な構造を持つデータに対しても、適切なモデルを設計することで、効率的な符号化と復号化が可能になると考えられます。これは、金融市場の予測やソーシャルネットワーク分析など、様々な分野への応用が期待されます。
このように、自動符号化器は、深層学習との組み合わせや新たなモデルの開発により、今後ますます強力な道具となり、様々な分野で大きな貢献を果たしていくことでしょう。今後の研究の進展により、自動符号化器が秘める更なる可能性が解き放たれ、私たちの生活をより豊かにしてくれると期待されます。
| 分野 | 応用 | 効果 |
|---|---|---|
| 画像認識 | ノイズ除去、画像圧縮、特徴抽出、分類 | 医療診断、自動運転技術 |
| 自然言語処理 | 文章要約、機械翻訳 | – |
| 時系列データ、グラフ構造データ | 効率的な符号化と復号化 | 金融市場の予測、ソーシャルネットワーク分析 |