
ダブルDQNで強化学習を改良

AIを知りたい
先生、ダブルDQNって、普通のDQNと何が違うんですか?

AIエンジニア
いい質問だね。普通のDQNでは、行動を選ぶのと、その行動の価値を評価するのが同じ仕組みだったんだ。ダブルDQNでは、それが別々になっているんだよ。
AIを知りたい
別々にすることで、何かいいことがあるんですか?
AIエンジニア
そうなんだ。DQNだと、自分の行動の価値を高く見積もりすぎてしまうことがあった。 ダブルDQNでは、行動を選ぶのと評価するのを分けることで、この過大評価を抑えることができるんだよ。
ダブルDQNとは。
人工知能の分野でよく使われる『二重の深いキューネットワーク』(ダブルDQN)について説明します。この技術は、行動の選択と、その行動の良し悪しを評価する部分を、それぞれ別のネットワーク(人工的な脳のようなもの)で行います。元となった『深いキューネットワーク』(DQN)では、行動の価値を高く見積もりすぎてしまう欠点がありました。これは、行動を選ぶ部分と、その行動の価値を評価する部分が同じネットワークだったことが原因です。ダブルDQNでは、この部分を二つに分けることで、より正確な評価を行えるようにしています。
はじめに

機械学習の分野の中で、強化学習は特に注目を集めています。強化学習とは、まるで人間が成長していくように、試行錯誤を繰り返しながら学習を進める人工知能の一種です。学習の主体はエージェントと呼ばれ、周囲の環境と関わり合う中で、より多くの報酬を得られるように行動を改善していきます。
例えるなら、迷路の中を進むネズミを想像してみてください。ネズミはゴールを目指して様々な道を進みます。行き止まりにぶつかったり、遠回りをしてしまったりしながら、最終的にゴールにたどり着いた時にチーズという報酬を得ます。この経験を繰り返すうちに、ネズミは最短ルートでゴールにたどり着けるようになります。強化学習のエージェントもこれと同じように、試行錯誤を通じて報酬を最大化する行動を学習します。
この学習の過程で重要な役割を担うのが、行動価値関数と呼ばれる概念です。これは、ある状況下で特定の行動をとった場合に、将来どれだけの報酬が期待できるかを示す数値です。迷路の例で言えば、ある分岐点で右に進むのと左に進むのとでは、どちらがより早くゴールに近づけるか、つまりより多くの報酬(チーズ)を得られる可能性が高いかを判断するための指標となります。
行動価値関数を正確に計算することは、エージェントが最適な行動を選ぶ上で欠かせません。もし行動価値関数の推定が間違っていると、エージェントは遠回りな道を選んでしまったり、最悪の場合、ゴールに辿り着けなくなってしまうかもしれません。そのため、強化学習の研究においては、行動価値関数をいかに効率よく、かつ正確に推定するかが重要な課題となっています。 様々な手法が提案されており、状況に応じて適切な方法を選択することが重要です。
従来手法の問題点

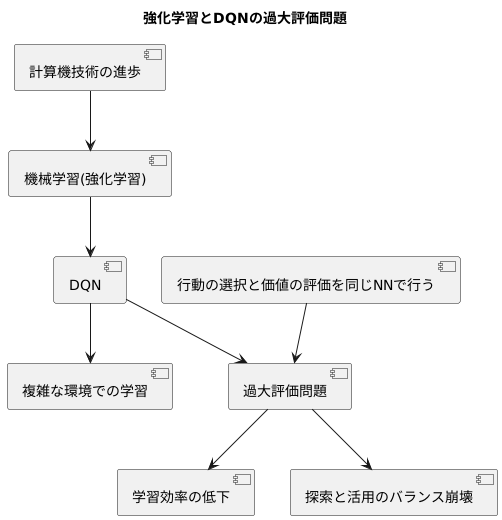
近年の計算機技術の進歩に伴い、機械学習、特に強化学習は目覚ましい発展を遂げてきました。強化学習は、試行錯誤を通じて環境に適応する学習方法であり、様々な分野で応用されています。その中で、従来の強化学習手法の一つであるディープ・キュー・ネットワーク(DQN)は、複雑な環境での学習を可能にした革新的な手法でした。この手法は、人間の脳の神経回路網を模倣したニューラルネットワークを用いて、行動の価値を予測する関数、すなわち行動価値関数を近似することで、複雑な状況における最適な行動を学習します。
しかし、DQNは行動価値関数を過大評価してしまうという欠点を持っています。これは、行動の選択と価値の評価を同じニューラルネットワークで行っていることに起因します。同じ計算機構が行動を選び、その行動の価値を評価するため、楽観的な予測に偏ってしまう傾向があります。具体的には、特定の行動が実際よりも高く評価され、その行動ばかりが選択される可能性があります。これは、まるで宝くじの当選確率を過大評価して買い続けてしまうようなもので、学習の効率を低下させる要因となります。
さらに、この過大評価は、探索と活用のバランスを崩す可能性も懸念されます。強化学習では、現状で最も良いと思われる行動を繰り返し選択する「活用」だけでなく、未知の行動を試す「探索」も重要です。過大評価によって特定の行動に固執してしまうと、他のより良い行動を見つける機会が失われ、最適な方策を学習する妨げとなる可能性があります。そのため、この過大評価問題への対策は、DQNを用いた強化学習において重要な課題となっています。
ダブルDQNの登場

強化学習という分野では、コンピュータに試行錯誤を通して学習させる手法が研究されています。この学習において、行動の価値を適切に評価することは非常に重要です。しかし、従来のDQNと呼ばれる手法では、行動の価値を過大評価してしまうという問題がありました。
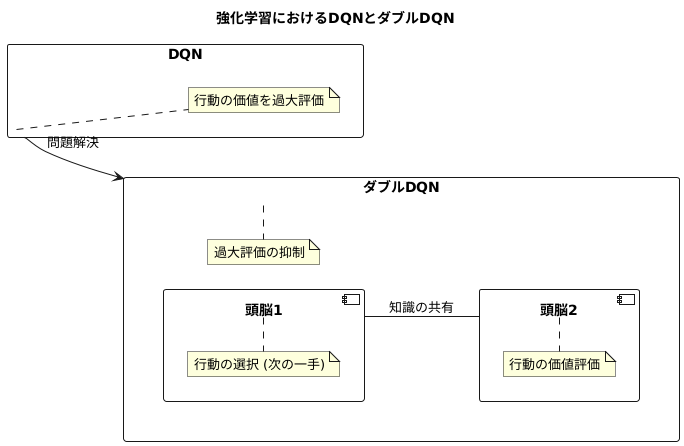
この過大評価は、学習の精度を下げ、最適な行動を見つけることを難しくします。そこで、この問題を解決するために、ダブルDQNという新しい手法が登場しました。ダブルDQNの最大の特徴は、二つの頭脳(ネットワーク)を使って学習を行う点にあります。
一つ目の頭脳は、どの行動をとるかを決める役割を担います。様々な行動の中から、最も価値の高いと判断した行動を選択します。まるで将棋で次の一手を決めるかのようです。そして、二つ目の頭脳は、選択された行動の価値を評価する役割を担います。一つ目の頭脳が選んだ行動が、実際にはどれだけの価値があるのかを冷静に判断します。
この二つの頭脳を交互に使い分けることで、行動の選択と価値の評価が分離されます。これは、まるで裁判で判決を下す際に、検察と裁判官が別々になっているのと似ています。検察は証拠を集めて犯罪の有無を判断しますが、最終的な判決は裁判官が下します。このように役割を分担することで、より公平で正確な判断が可能になります。
ダブルDQNも同様に、二つの頭脳がそれぞれの役割を分担することで、過大評価のリスクを抑え、より正確な学習を実現しています。一つ目の頭脳は、常に最新の情報を基に行動を選択します。そして、二つ目の頭脳は、定期的に一つ目の頭脳の知識を取り込みながら、行動の価値を評価します。このように二つの頭脳が協力しながら学習を進めることで、従来の手法よりも高い精度で学習を行うことが可能になります。
ダブルDQNの仕組み

強化学習における価値ベースの手法であるDQNは、行動価値を過大評価してしまうという問題を抱えています。この問題を解決するために考案されたのがダブルDQNです。DQNでは、行動価値の推定と、その価値に基づく行動の選択を同じネットワーク、つまりメインネットワークで行います。ところが、常に最大の価値を持つ行動を選択しようとすると、実際よりも価値が高いと推定された行動が選ばれやすくなり、これが過大評価につながってしまいます。
ダブルDQNでは、この問題に対処するために、行動の選択と評価を別々のネットワークで行うという工夫をしています。具体的には、まずメインネットワークを使って、今の状態における各行動の価値を推定します。次に、やはりメインネットワークを使って、次の状態での価値が最大になる行動を選びます。ここまではDQNと同じですが、ダブルDQNでは、選んだ行動の価値の評価をターゲットネットワークという別のネットワークを使って行う点が異なります。
このように、行動の選択にはメインネットワーク、評価にはターゲットネットワークというように、二つのネットワークを使うことで、特定の行動の価値を過大評価してしまう可能性を下げることができます。例えるなら、ある商品を買うかどうか迷っているときに、商品の良さを説明する店員と、実際に商品を使う人の両方の意見を聞くようなものです。店員は商品の良い面ばかりを強調するかもしれませんが、実際に使った人の意見も聞くことで、より正確な判断ができます。ダブルDQNも同様に、二つのネットワークを使うことで、より正確な価値評価を行い、過大評価による学習の不安定さを抑え、より効率的な学習を実現しています。
| 手法 | 行動価値の推定 | 行動の選択 | 評価 | 過大評価 |
|---|---|---|---|---|
| DQN | メインネットワーク | メインネットワーク | メインネットワーク | 発生しやすい |
| ダブルDQN | メインネットワーク | メインネットワーク | ターゲットネットワーク | 抑制される |
ダブルDQNの利点

深層強化学習における行動価値の学習において、従来のDQNと呼ばれる手法では、しばしば学習が不安定になり、期待した性能が得られないことがありました。これは、行動価値を過大に見積もってしまうことが原因の一つでした。この過大評価は、実際にはそれほど良くない行動を、あたかも非常に良い行動であるかのように誤って学習してしまうことにつながり、結果として最適な戦略を学習することを妨げていました。
この問題に対処するために開発されたのが、ダブルDQNと呼ばれる手法です。ダブルDQNは、行動価値の評価と行動の選択を別々のネットワークで行うという工夫を取り入れることにより、従来のDQNで発生していた過大評価を効果的に抑えることができます。具体的には、ある行動の価値を評価する際には、一方のネットワークで最適な行動を選び、もう一方のネットワークでその選ばれた行動の価値を評価します。この仕組みにより、特定の行動の価値が過剰に高く見積もられることを防ぎ、より正確な価値評価が可能になります。
ダブルDQNの利点は、過大評価の抑制だけではありません。DQNの拡張として実装できるため、既存のDQNのコードに少し手を加えるだけで導入できます。複雑な変更を必要としないため、導入にかかる手間や時間は比較的少なく済みます。また、計算量の増加もわずかであるため、計算資源の制約が厳しい場合でも利用しやすい手法です。
過大評価の抑制による学習の安定化と、実装の容易さ、計算コストの低さといった利点から、ダブルDQNは様々な強化学習の課題に適用され、成果を上げています。ロボット制御やゲームプレイなど、様々な分野でエージェントの性能向上に貢献しており、今後も幅広い応用が期待される、大変有力な手法です。
| 手法 | 課題 | 解決策 | 利点 | 応用分野 |
|---|---|---|---|---|
| DQN | 学習の不安定さ、行動価値の過大評価 | – | – | – |
| ダブルDQN | DQNの課題 | 行動価値の評価と行動の選択を別々のネットワークで行う | 過大評価の抑制、学習の安定化、DQNからの実装が容易、計算コストが低い | ロボット制御、ゲームプレイなど |
適用事例

二重の深い価値学習、略して二重価値学習は、様々な場面で成果を上げています。この技術は、試行錯誤を通じて機械に学習させる方法、いわゆる強化学習の中でも特に注目されています。具体的には、ゲームの操作や機械の動きを制御するといった課題に広く応用されています。
例えば、家庭用ゲーム機で昔懐かしい遊びを学習させる実験では、従来の深い価値学習よりも高い得点を出せるようになりました。画面の状況を見て、どのボタンを押せばよいかを学ぶのが上手くなったのです。二重価値学習を用いることで、機械はより賢く行動を選び、結果としてゲームの腕前が上がることが示されました。
また、二足歩行の機械を歩かせる、あるいは目的地まで誘導するといった課題にも、この技術が役立っています。歩く、曲がるといった動作のタイミングや方向を、機械は自分で学習します。従来の方法では、うまく学習させるのが難しかった複雑な動きも、二重価値学習によって効率的に習得できるようになりました。これは、機械に新しい技能を教える上で大きな進歩と言えます。
さらに、無人搬送車のように、荷物を目的地まで運ぶ機械にも応用が期待されています。周囲の状況を把握し、障害物を避けながら効率的なルートを見つけ出す必要があるため、高度な判断力が求められます。二重価値学習は、このような複雑な状況下での判断を機械に学習させるのに適しています。
このように、二重価値学習は、ゲーム、機械制御、搬送など、様々な分野で成果を上げており、強化学習における重要な技術として、今後ますますの発展と応用が期待されます。より複雑な課題を解決し、私たちの生活を豊かにする可能性を秘めていると言えるでしょう。
| 分野 | 適用例 | 効果 |
|---|---|---|
| ゲーム | 家庭用ゲーム機の操作学習 | 従来の深層学習より高得点 |
| 機械制御 | 二足歩行ロボットの歩行・誘導 | 複雑な動作の効率的な学習 |
| 搬送 | 無人搬送車のルート探索・障害物回避 | 複雑な状況下での高度な判断 |