
SegNetによる画像分割

AIを知りたい
先生、『セグネット』ってよく聞くんですけど、どんなものなんですか?

AIエンジニア
『セグネット』は、絵を細かく分けて、それぞれの部分が何なのかを判別する技術だよ。例えば、写真のどこに人が写っているか、どこに車が写っているかを判別するのに使われるんだ。
AIを知りたい
どうやって判別するんですか?
AIエンジニア
縮小コピーを作る機械と拡大コピーを作る機械を組み合わせたようなものだと考えてみよう。まず、縮小コピーを作る機械で絵の特徴をどんどん抽出して小さくしていく。そして、拡大コピーを作る機械で、縮小された情報をもとに元の大きさに戻しながら、それぞれの部分が何なのかを判別していくんだ。この縮小と拡大の過程で、絵の細かい部分を認識していくんだよ。
SegNetとは。
『セグネット』という人工知能にまつわる言葉について説明します。セグネットは、深層学習という技術を使った、画像の領域分割をするものです。仕組みとしては、符号化器と復号化器という二つの部分からできています。符号化器では、入力された画像から特徴となる情報を取り出します。そして、復号化器では、取り出された特徴情報をもとに、元の画像と同じ大きさの領域分割地図を作ります。
概要

絵分けの技術、セグネットは、写真の中のものを細かく分類して色分けする、まるで地図を作るような技術です。例えば、街並みの写真を与えると、空は青、道路は灰色、建物は茶色、木々は緑といった具合に、一つ一つのものを別々の色で塗り分けてくれます。この技術は、人の目では見分けにくい細かい部分まで正確に分類できるので、様々な分野で役立っています。
自動運転では、周りの状況を正確に把握するために使われます。例えば、道路と歩道の境界線や、他の車や歩行者、信号機などを識別することで、安全な運転を支援します。また、医療の分野では、レントゲン写真やCT画像から、腫瘍などの異常部分を正確に見つけるのに役立ちます。さらに、衛星写真から土地の種類や植生を分析するなど、地図作りにも応用されています。
セグネットの仕組みは、二つの主要な部分から成り立っています。一つは「縮小器」、もう一つは「拡大器」です。縮小器は、入力された写真の情報を少しずつ要約して、重要な特徴だけを抜き出す役割を担います。これは、写真の全体像を把握するような作業です。次に、拡大器は、縮小器が抜き出した重要な特徴をもとに、元の写真のサイズにまで情報を復元します。そして、一つ一つの部分が何であるかを判断し、色分けした地図のような画像を作り出します。
この縮小と拡大の組み合わせが、セグネットの大きな特徴です。縮小することで重要な特徴を効率的に捉え、拡大することで元の画像の細部まで復元できるため、高精度な絵分けを実現しています。まるで、一度全体像を掴んでから細部を描き込む、熟練の絵描きのようですね。
符号化器の役割

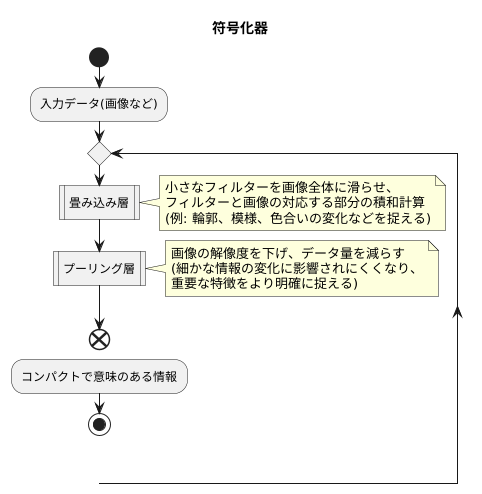
符号化器は、画像などの入力データから本質的な特徴を抜き出す役割を担います。まるで職人が材料から必要な部品を切り出すように、入力データから重要な情報だけを抽出するのです。この抽出作業は、畳み込み層とプーリング層と呼ばれる二つの主要な処理を繰り返すことで行われます。
まず、畳み込み層では、小さなフィルターを画像全体に滑らせながら、フィルターと画像の対応する部分の積和計算を行います。このフィルターは、画像の特定の特徴、例えば輪郭や模様、色合いの変化などを捉える役割を果たします。フィルターを画像全体に適用することで、これらの特徴が画像のどこに、どのように現れているのかを検出します。この処理は、まるで虫眼鏡で画像の細部をくまなく調べるようなものです。畳み込み層を重ねることで、単純な特徴からより複雑で抽象的な特徴を段階的に抽出できます。例えば、最初の層では線の向きや端を検出し、次の層ではそれらを組み合わせて円や四角などの形を認識し、さらに後の層では顔のパーツや物体全体といった高度な特徴を捉えることができます。
次に、プーリング層では、画像の解像度を下げ、データ量を減らします。これは、写真のサイズを小さくするようなものです。解像度を下げることで、細かな情報の変化に影響されにくくなり、重要な特徴をより明確に捉えることができます。また、データ量が減ることで、処理速度の向上にも繋がります。プーリング層は、畳み込み層で抽出された特徴の位置のずれやわずかな変化を吸収し、より頑健な特徴表現を獲得する役割を果たします。
このように、符号化器は畳み込み層とプーリング層を繰り返し適用することで、入力データから様々なレベルの特徴を抽出し、最終的にコンパクトで意味のある情報へと変換します。これは、複雑な情報を整理し、本質を捉えるための重要な処理であり、様々な画像認識技術の基礎となっています。
復号化器の役割

復号化器は、符号化器で圧縮された情報を元の形に戻す役割を担います。画像の分割においては、符号化器によって抽出された特徴地図をもとに、元の画像と同じ大きさの分割地図を作成します。
復号化器は、段階的に画像の解像度を上げる処理を行います。これは、まるで地図を拡大していくように、縮小された情報を元々の大きさに戻していく作業です。この処理は、一般的に拡大処理と呼ばれています。
分割地図を作るためのネットワークの一つであるSegNetでは、この拡大処理に特別な工夫が凝らされています。SegNetでは、符号化器で情報を圧縮する際に、どの位置の情報がどのように縮小されたかを記録しています。復号化器では、この記録された位置情報を参照することで、より正確に元の画像を再現することができます。
復号化器も符号化器と同様に、複数の畳み込み層と呼ばれる処理を積み重ねています。畳み込み層は、画像の特徴を抽出するための層で、複数の層を重ねることで、より複雑な特徴を捉えることができます。復号化器では、この畳み込み層を用いて、符号化器で抽出された特徴を統合し、最終的に各画素がどの種類に属するのかを予測します。
そして、この予測結果が分割地図として出力されます。分割地図は、元の画像の各画素がどの種類に属するのかを示した地図で、例えば、人物、車、道路など、画像中に存在する物体を識別するために利用できます。
位置情報の活用

物の場所を示す情報を使うことで、画像の中の物の種類を正確に判別する技術があります。これを「セグメンテーション」と言います。この技術でよく使われる「セグネット」という手法は、画期的な工夫によって、高い精度を実現しています。
セグネットは、二つの主要な部分、「エンコーダー」と「デコーダー」から成り立っています。エンコーダーは、画像の特徴を捉え、縮小する役割を担います。この縮小の過程で、一番目立つ特徴の位置を記録しておきます。この記録がセグネットの重要な点です。
デコーダーは、エンコーダーで縮小された画像を元の大きさに戻す役割を担います。通常、画像を拡大する際には、単純に周りの色を参考に色を補完します。しかし、この方法では細かい情報が失われ、境界線がぼやけてしまうことがあります。
セグネットでは、エンコーダーで記録しておいた一番目立つ特徴の位置情報を使って、拡大時の色の補完を行います。これにより、重要な特徴が元の位置に正確に戻り、境界線がぼやけることなく、鮮明な画像が得られます。
例えるなら、地図を使って宝探しをする場面を想像してみてください。エンコーダーは、広い範囲の地図を縮小して、宝の場所をマークします。デコーダーは、縮小された地図を元の大きさに戻す際に、マークされた宝の場所の情報を利用することで、正確な宝の位置を特定できます。
このように、セグネットは位置情報を活用することで、画像の細部まで正確に判別することを可能にし、セグメンテーション技術の精度向上に大きく貢献しています。
応用例

絵分け神経網(SegNet)は、その高い正確さと処理の速さから、様々な分野で使われています。自動運転の分野では、周りの状況を理解するために欠かせない技術となっています。道路や歩道、歩行者や自転車、信号機や標識など、周囲の物体を正確に見分けることで、安全な自動運転が可能になります。たとえば、SegNetは、カメラで捉えた映像から、道路と歩道の境界線を正確に区別したり、歩行者や自転車を素早く見つけることができます。
医療画像診断の分野でも、SegNetは重要な役割を果たしています。CTやMRIなどの画像から、臓器や腫瘍などの位置や形状を特定するのに役立ちます。例えば、肺がんの早期発見では、CT画像から小さな腫瘍を見つけるためにSegNetが活用されています。また、心臓病の診断では、心臓の筋肉や血管の状態を詳しく調べるために利用されています。これにより、医師はより正確な診断を下し、適切な治療方針を立てることができます。
衛星画像解析の分野では、SegNetは、土地の使い方を調べたり、災害の状況を把握したりするために利用されています。例えば、森林や農地、都市部などの土地の種類を分類したり、洪水や地震などの災害で被害を受けた地域を特定したりするのに役立ちます。
さらに、ロボット工学の分野では、ロボットが周囲の環境を理解し、適切な行動をとるためにSegNetが活用されています。ロボットは、SegNetを使って物体を認識し、掴んだり、動かしたりすることができます。また、精密農業の分野では、作物の生育状況を監視したり、病害虫を早期に発見したりするためにSegNetが使われています。ドローンで撮影した画像から、作物の種類や生育状況を把握し、肥料や農薬を必要な場所に必要なだけ散布することで、効率的な農業を実現できます。このように、画像認識技術が重要な役割を果たす様々な分野で、SegNetは広く活用されており、今後、技術がさらに進歩することで、応用範囲はますます広がっていくと期待されます。
| 分野 | SegNetの役割 | 具体例 |
|---|---|---|
| 自動運転 | 周囲の状況理解 | 道路/歩道、歩行者/自転車、信号/標識の識別 |
| 医療画像診断 | 臓器/腫瘍の位置・形状特定 | 肺がんの早期発見(CT画像から腫瘍特定)、心臓病診断(心臓筋肉/血管の状態把握) |
| 衛星画像解析 | 土地利用調査、災害状況把握 | 土地分類(森林、農地、都市部など)、災害被害地域特定 |
| ロボット工学 | ロボットの環境理解、行動支援 | 物体認識、掴む/動かす |
| 精密農業 | 作物生育状況監視、病害虫早期発見 | 作物種類/生育状況把握、肥料/農薬散布 |
今後の展望

画像分割技術のSegNetは、既に高い成果を上げていますが、更なる発展が期待されています。今後、どのような改良が考えられるか、幾つかの点について詳しく見ていきましょう。
まず、現状のSegNetは比較的単純な画像には高い精度で対応できますが、複雑な場面での認識精度は課題となっています。例えば、多くの物体が重なり合っていたり、照明条件が複雑な状況では、正確な分割が難しくなります。この問題を解決するためには、より深い層を持つネットワーク構造の開発が必要です。層を深くすることで、より複雑な特徴を捉え、より高度な状況にも対応できるようになります。
次に、処理速度の向上も重要な課題です。SegNetは高い精度を実現していますが、処理に時間がかかる場合があります。特に、自動運転やロボット制御といった、リアルタイムでの処理が必要な分野では、迅速な応答が求められます。そのため、計算量を削減し、高速化するための技術開発が不可欠です。具体的には、演算アルゴリズムの最適化や、不要な計算の省略といった手法が考えられます。
最後に、様々な種類のデータに対応できる汎用性の向上が求められています。SegNetは特定のデータセットで学習されていますが、異なる種類のデータに適用する場合、性能が低下する可能性があります。例えば、医療画像や衛星画像など、学習データとは異なる特性を持つデータにも対応できるよう、より柔軟で適応性の高いモデルの開発が必要です。
これらの課題を解決することで、SegNetは更なる進化を遂げ、様々な分野で活用されることが期待されます。自動運転や医療診断、工場の自動化など、幅広い分野で、その高い精度と柔軟性を活かした応用が期待されています。
| 課題 | 詳細 | 解決策 |
|---|---|---|
| 認識精度の向上 | 複雑な場面(物体同士の重なり、複雑な照明条件など)での認識精度が低い | より深い層を持つネットワーク構造の開発 |
| 処理速度の向上 | 処理に時間がかかる場合がある | 計算量を削減し、高速化するための技術開発(演算アルゴリズムの最適化、不要な計算の省略など) |
| 汎用性の向上 | 学習データと異なる種類のデータへの適用時に性能が低下する可能性がある | より柔軟で適応性の高いモデルの開発 |