二つの網で文脈把握:翻訳の仕組み

AIを知りたい
先生、「Encoder-Decoder Attention」ってよく聞くんですけど、難しくてよくわからないんです。簡単に説明してもらえますか?

AIエンジニア
そうか、難しいよね。簡単に言うと、翻訳機で文章を翻訳する時みたいに、元の文章を別の文章に変換する仕組みだよ。元の文章を読み込む部分を「Encoder」、変換後の文章を作る部分を「Decoder」と言うんだ。そして「Attention」は、Decoderが文章を作ると際に、Encoderが読み込んだ元の文章のどの部分に注目するかを決める仕組みのことだよ。
AIを知りたい
なるほど。元の文章のどの部分に注目するかが重要なんですね。具体的にはどのように注目するんですか?
AIエンジニア
そうだね。例えば、「私は猫が好きです」を英語に翻訳する場合を考えてみよう。Decoderが「I」を出力するときは「私」に、「like」を出力するときは「好き」に注目する。つまり、翻訳先の単語を作る際に、元の文章の関連する単語に注目することで、より正確な翻訳ができるんだ。
Encoder-Decoder Attentionとは。
人工知能で使われる「エンコーダー・デコーダー・アテンション」という仕組みについて説明します。これは、エンコーダーとデコーダーと呼ばれる二つの再帰型ニューラルネットワーク(特にLSTMと呼ばれるもの)を組み合わせ、アテンションという仕組みを使ったものです。主に、系列から系列への変換、例えば機械翻訳などに使われています。
符号化と復号化

言葉の壁を越えるためには、異なる言語間で意味を正確に伝える仕組みが必要です。近年、この難題を解決する手段として、機械翻訳の技術が急速に発展しています。その中心的な役割を担うのが「符号化」と「復号化」と呼ばれる処理です。
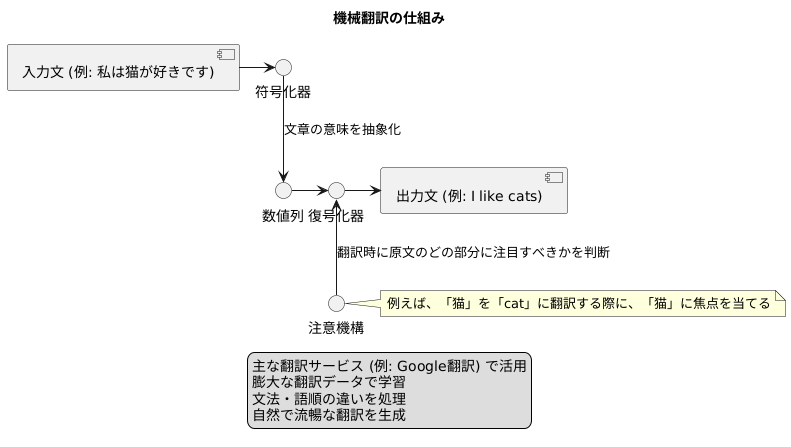
まず「符号化」は、入力された文章をコンピュータが理解できる形に変換する作業です。人間の言葉は複雑で、同じ言葉でも文脈によって意味が変わるため、コンピュータがそのまま扱うのは困難です。そこで、符号化器(エンコーダー)は、入力された文章を分析し、その意味をベクトルと呼ばれる数値の列に変換します。これは、文章の意味を一種の暗号に変換するようなものです。ベクトルは、文章の特徴や意味を抽象的に表現しており、コンピュータが処理しやすい形になっています。
次に「復号化」は、符号化された情報を元に、目的の言語で文章を生成する作業です。復号化器(デコーダー)は、エンコーダーが生成したベクトルを受け取り、それを基に翻訳先の言語で文章を組み立てます。これは、暗号を解読し、元の文章の意味を別の言語で表現するようなものです。復号化器は、ベクトルに含まれる情報をもとに、文法や語彙の規則に則りながら、自然で正確な文章を生成しようとします。
符号化と復号化は、まるで翻訳者のように連携して働きます。エンコーダーが文章のエッセンスを抽出し、デコーダーがそれを受け取って新たな言語で表現することで、より自然で精度の高い翻訳が可能になります。この技術は、グローバル化が進む現代社会において、言葉の壁を取り払い、人々の相互理解を深める上で重要な役割を担っています。
注意機構

翻訳の質を大きく向上させる技術として、「注意機構」というものがあります。この技術は、文章を別の言語に置き換える際に、訳文のどの部分を元の文章のどの部分に対応させるかを自動的に判断する仕組みです。
従来の翻訳技術では、「符号化器」と「復号化器」と呼ばれる二つの部品を用いていました。符号化器は元の文章全体を一つの情報のかたまりに変換し、復号化器はその情報をもとに訳文を作成します。しかし、この方法では、元の文章の細かいニュアンスが失われてしまうことがありました。例えば、長い文章の場合、重要な情報とそうでない情報がまとめて扱われてしまい、訳文の精度が低下する可能性がありました。
注意機構はこの問題を解決するために開発されました。注意機構を用いると、復号化器は訳文の各単語を作成する際に、元の文章のどの単語に注目すべきかを自動的に判断できます。例えば、「私は赤いりんごを食べた」という文章を英語に翻訳する場合、「赤い」という単語を翻訳する際に、注意機構は元の文章の「赤い」という単語に注目します。そして、「赤い」に対応する英単語「red」を選択し、訳文に組み込みます。このように、注意機構は文脈を理解しながら翻訳を行うため、より自然で正確な訳文を作成できます。
注意機構は人間が翻訳を行う際の思考プロセスに似ています。私たちが翻訳を行う際、訳文の各単語に対応する元の文章の単語を無意識に探しています。注意機構はこのプロセスを自動化することで、翻訳の精度を飛躍的に向上させています。そのため、現在では多くの機械翻訳システムに注意機構が導入され、高品質な翻訳を実現しています。
二つの網の連携

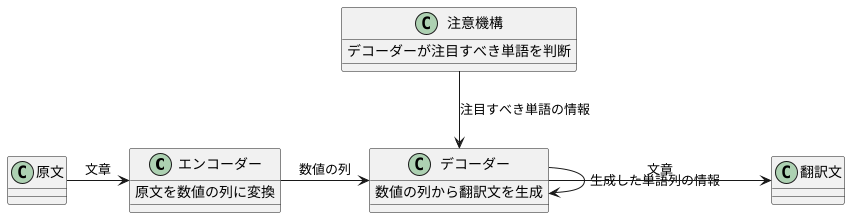
翻訳の仕組みは、まるで二つの網が巧みに連携して魚を捕らえるかのようです。一つ目の網は「エンコーダー」と呼ばれ、原文となる言語の文章を受け取ると、それぞれの単語を数値の列に変換します。これは、コンピュータが言葉を理解するための第一歩です。変換された数値の列は、単語の意味や文中の位置関係といった情報を持ち、まるで魚の鱗のように一つ一つが重要な意味を持っています。これらの数値の列は、全体として一つの系列となり、二つ目の網である「デコーダー」へと送られます。
デコーダーは、エンコーダーから受け取った数値の列を基に、翻訳先の言語で文章を作り出す役割を担います。まるで受け取った魚を丁寧に料理するように、一つずつ単語を予測し、並べていきます。この時、デコーダーは既に生成した単語列の情報も利用します。例えば、「こんにちは」の後に続く単語は、「世界」や「ございます」といった可能性が高いといった具合です。しかし、ただエンコーダーからの情報と既に生成した単語列の情報だけで単語を予測するのでは、文脈を捉えきれていない場合があります。そこで登場するのが「注意機構」です。
注意機構は、デコーダーがどの単語に注目すべきかを判断する重要な役割を果たします。エンコーダーが生成した数値の列の中で、次に生成する単語に関連性の高い部分を見つけ出し、その部分を重点的に利用することで、より正確な翻訳を実現します。例えば、「私は赤いリンゴが好きです」という文を英語に翻訳する場合、「赤い」という単語を翻訳する際に、エンコーダーが生成した「リンゴ」に対応する数値の列に注目することで、「red apple」と正しく翻訳することができます。もし「私」に注目してしまうと、「my apple」といった誤訳につながる可能性があります。このように、エンコーダーとデコーダー、そして注意機構が三つの連携により、まるで二つの網が協力して魚を捕らえるように、高精度な翻訳を実現しているのです。
再帰型ネットワーク

ことばを順番に処理していく人工知能の仕組みである再帰型ネットワークは、過去の情報を覚えている特別なネットワークです。 これは、まるで人間が文章を読むように、前の単語を記憶しながら次の単語を読むことで、文章全体の理解を深めていくことに似ています。この再帰型ネットワークは、エンコーダー・デコーダーモデルという二つの部分からなる仕組みの中で活躍しています。
エンコーダーは、入力された文章を単語ごとに分解し、順番に読み込んでいきます。そして、読み込んだ単語の一つ一つと、それまでの単語の流れを踏まえて、文章の意味をぎゅっと凝縮した情報に変換します。 この凝縮された情報はベクトル表現と呼ばれ、文章の全体像を小さな塊にまとめたものと例えることができます。
デコーダーは、エンコーダーから受け取ったこの凝縮された情報と、自分がそれまでに作り出した単語列をもとに、次に来る単語を予測します。 まるで文章を書き進めるように、一つずつ単語を生成していくのです。 このとき、エンコーダーの情報は文章全体の文脈を理解するのに役立ち、より自然で正確な文章生成を可能にします。
このように、再帰型ネットワークは、時系列データ、つまり順番に並んだデータの処理に非常に優れています。 例えば、文章は単語が順番に並んでいるため、時系列データと考えることができます。再帰型ネットワークは、この単語の並び順を理解し、前の単語の情報を使って次の単語を予測する能力を持つため、文章の翻訳や要約、文章生成など、様々な自然言語処理の課題に役立っています。そして、エンコーダー・デコーダーモデルの性能向上にも大きく貢献しています。まさに、人工知能によることばの理解と生成を支える重要な技術と言えるでしょう。
長・短期記憶

{巡回型神経網(RNN)の一種である長・短期記憶(LSTM)は、長期にわたる繋がりを学習できる能力を持つため、符号化器・復号化器モデルで広く使われています}。通常のRNNは、長い一続きの情報を扱う際に、過去の情報が次第に薄れてしまう勾配消失問題が起こりやすいという欠点があります。これは、長い鎖のようなもので、鎖の端を引っ張ると、遠い側の力は弱まってしまうイメージです。
しかし、LSTMにはこの問題を解決する特別な仕組みが備わっています。LSTMは、情報を保持するための特別な記憶領域を持っており、例えるなら、必要な情報を書き込んだり、消したり、読み出したりできるノートのようなものです。このノートのおかげで、LSTMは過去の情報を適切に保ち、長期にわたる繋がりを学習することが可能になります。
例えば、長い文章を翻訳する場合を考えてみましょう。通常のRNNでは、文章の最初の部分が持つ情報が、文章の最後の部分まで伝わりにくいため、正確な翻訳が難しくなります。しかし、LSTMを用いることで、文章全体の文脈を理解し、より自然で正確な翻訳結果を得ることができます。これは、LSTMが文章全体の情報をノートに記録し、必要な時に参照できるおかげです。
このように、LSTMは、符号化器・復号化器モデルの性能向上に大きく貢献している重要な技術です。LSTMの持つ特別な記憶領域は、長期的な依存関係の学習を可能にし、様々な自然言語処理タスクにおいて高い精度を実現する鍵となっています。まるで人間の記憶のように、LSTMは過去の情報を適切に活用することで、複雑な処理を可能にしているのです。
| RNNの課題 | LSTMの仕組み | LSTMの利点 | 例 |
|---|---|---|---|
| 勾配消失問題(長いシーケンスの処理で過去の情報が薄れる) | 情報の保持、書き込み、消去、読み出しが可能な記憶領域(ノートのようなもの) | 長期にわたる繋がりを学習可能 | 長い文章の翻訳で、文脈を理解した自然で正確な翻訳が可能 |
機械翻訳への応用

言葉の壁を取り払う技術として、機械翻訳は近年目覚ましい発展を遂げてきました。この発展を支える中心的な技術の一つが、符号化器・復号化器・注意機構です。この技術は、まるで人間の翻訳者のように、文章の意味を理解し、異なる言語へと変換することを可能にします。
まず、符号化器は、入力された文章を分析し、その意味を抽象的な数値列に変換します。これは、文章の骨組みを掴み、重要な情報を見極める作業に例えられます。次に、復号化器が、この数値列を受け取り、別の言語の文章へと組み立て直します。この過程で、注意機構が重要な役割を果たします。注意機構は、翻訳の際に、原文のどの部分に注目すべきかを判断する働きをします。例えば、「私は猫が好きです」という日本語を英語に翻訳する場合、「猫」という単語に対応する英語の「cat」を生成する際に、注意機構は原文の「猫」に焦点を当てます。これにより、文脈に沿った適切な翻訳が可能になります。
グーグル翻訳をはじめとする主要な翻訳サービスでは、既にこの符号化器・復号化器・注意機構が活用されています。膨大な翻訳データを使って学習させることで、この技術は、異なる言語間の文法や語順の違いを巧みに処理し、より自然で流暢な翻訳を生成できるようになりました。例えば、日本語の「明日は雨が降るでしょう」という未来表現を、英語の「It will rain tomorrow」という表現に正しく変換できます。
今後も、機械翻訳技術の進化において、符号化器・復号化器・注意機構は中心的な役割を果たしていくと考えられます。より多くの言語に対応し、より高度な翻訳を実現することで、この技術は、人々のコミュニケーションをより豊かにし、国際交流を促進する力となるでしょう。