音声認識の立役者:CTC

AIを知りたい
先生、CTCってどういうものですか?音声認識でよく聞くんですけど、よくわからなくて。

AIエンジニア
そうですね、CTCは音声データと文字データの長さが違う問題を解決する手法です。例えば「こんにちは」と言うとき、音声データは長くても「こん、に、ち、は」の4文字より短いことは無いですね。CTCはこの違いを吸収してくれるんです。
AIを知りたい
なるほど。でも、音声データの方が長いと、文字はどうなるんですか?「こんにちは」の音が伸びていたら、「こんんんにちは」とかになるんですか?
AIエンジニア
良い質問ですね。「こんんんにちは」のような場合も正解として扱うんです。他にも「こ_ん_に_ち_は」のように空白を入れて、正解の文字列と同じ長さになるように調整します。こういった調整もCTCが行います。
CTCとは。
音声認識などで使われるAI技術の用語「CTC」について説明します。RNNという仕組みでは、入力データと出力データの数は必ず同じになります。しかし、音声を扱う場合は、入力された音声データの数と、出力するべき音の記号の数が、必ずしも一致するとは限りません。この違いを埋める方法がCTC(接続時系列分類)です。CTCを使うと、例えば「hello」という言葉の場合、「heello」や「he_llo」、「helloo」といった出力も正解として扱われます。
音声認識における課題

人が話す言葉を機械が理解できるように変換する技術、音声認識は、私たちの暮らしに様々な変化をもたらしています。声で検索したり、文字を入力したり、話しかけるだけで家電を操作したりと、音声認識を使った便利な機器や役務は既に広く使われています。しかし、この音声認識を完璧なものにするには、まだいくつかの壁を越えなければなりません。
音声認識の難しさの一つに、入力される音声の情報量と、出力される音の単位の数の差が挙げられます。人の声は、音の波形を短い時間で区切って記録したデータとして扱われます。このデータは、例えば一秒間に何万回も記録されるため、非常に多くの情報量を含んでいます。一方、言葉の基本となる音の単位は、音声データに比べてずっと数が少ないです。例えば、「こんにちは」という言葉は複数の音から成り立っていますが、その基本単位となる音の数は限られています。この入力と出力の数の大きな差が、音声認識を複雑にしているのです。
機械に人の声を理解させるためには、膨大な音声データの中から、意味を持つ音の単位を正確に抽出する必要があります。この作業は、まるで砂浜から小さな貝殻を一つ一つ拾い集めるような、大変な作業です。さらに、周囲の雑音や、話す人の口調、滑舌、方言なども、音声認識の精度を下げる要因となります。静かな場所でハッキリと話された言葉は認識しやすいですが、騒がしい場所で小声で話された言葉や、訛りの強い言葉は、機械にとって理解するのが難しいのです。
これらの課題を解決するために、様々な技術開発が進められています。音声データから雑音を取り除く技術や、大量のデータから機械が自動的に学習する技術などがその例です。こうした技術革新によって、音声認識の精度は日々向上しており、近い将来、より自然でスムーズな音声認識が実現すると期待されています。
| 項目 | 説明 |
|---|---|
| 音声認識とは | 人が話す言葉を機械が理解できるように変換する技術 |
| 現状 | 声で検索、文字入力、家電操作など、既に広く利用されている。 |
| 課題 | 入力される音声の情報量と出力される音の単位の数の差が大きい。周囲の雑音、話者の口調・滑舌・方言なども精度低下の要因。 |
| 課題の詳細 | 音声データは膨大で、意味のある音の単位を抽出するのが困難。雑音、口調、滑舌、方言などの影響を受けやすい。 |
| 解決策 | 雑音除去技術、機械学習による自動学習技術などの開発が進んでいる。 |
| 将来展望 | 技術革新により、より自然でスムーズな音声認識の実現が期待される。 |
CTCの登場

音声認識の分野では、入力される音声データと、出力される音素や文字といった記号列の長さが一致しないという問題が、長らく課題となっていました。音声データは、時間的な連続性を持つため、同じ言葉を発音しても、その長さは微妙に変化します。一方、文字列は、固定の長さを持つ離散的な記号列です。この、連続的なデータと離散的なデータの長さを一致させることは、従来の手法では困難でした。
この問題を解決するために登場したのが、接続時系列分類と呼ばれる手法です。この手法は、出力系列に特別な空白記号を導入することで、入力と出力の長さの不一致を吸収する仕組みを備えています。
具体的に説明すると、「こんにちは」という言葉を音声認識する場面を想像してみてください。従来の手法では、入力された音声データと「こんにちは」の5つの音に対応する部分を手作業で切り出して、正確に対応付ける必要がありました。しかし、音声データの長さは発話するたびに微妙に変化するため、この対応付け作業は非常に困難でした。
接続時系列分類では、「こんにちは」を表す出力系列に空白記号を挿入することで、この問題を解決します。例えば、「こ_ん_に_ち_は」や「こんんにちは」、「こんにち_はあ」といったように、空白記号や音の重複を許容することで、入力音声データと出力記号列の長さを一致させることができます。
このように、接続時系列分類は、音声データと文字列の対応付けの柔軟性を大幅に向上させました。その結果、音声認識の精度は飛躍的に向上し、様々な場面で音声認識技術が活用されるようになりました。まさに、音声認識技術における革新的な手法と言えるでしょう。
| 手法 | 入力データ | 出力データ | 課題 | 解決策 |
|---|---|---|---|---|
| 従来の手法 | 音声データ(連続的) | 音素/文字列(離散的) | 入力と出力の長さが一致しない。手作業での対応付けが困難。 | – |
| 接続時系列分類 | 音声データ(連続的) | 音素/文字列+空白記号(離散的) | – | 空白記号の導入により、入力と出力の長さの不一致を吸収。柔軟な対応付けが可能。 |
CTCの仕組み

音声認識の分野で、音のつながりを文字に変換する技術は大変重要です。この変換をうまく行う手法の一つにシーティーシー(CTC)というものがあります。シーティーシーは、リカレントニューラルネットワーク(RNN)と呼ばれる、時間的な流れを持つデータの処理に優れた仕組みと組み合わせて使われます。RNNは、音声データのように連続したデータの特徴を捉えるのが得意です。
シーティーシーは、このRNNの出力部分に付け加えられます。RNNが出力した音の情報を元に、実際にどのような音の並びなのかを予測します。この予測は、それぞれの時点で、それぞれの音がどのくらい現れやすいかという確率に基づいて行われます。
シーティーシーのすごいところは、考えられる音の並びを全て考慮する点です。何も音が出ていない状態を表す「空白」も一つの音として扱い、全部の音の並びの中から、一番可能性の高いものを選び出します。この時、同じ音が連続して出ている場合は、一つにまとめられます。また、「空白」は最終的に取り除かれます。
例えば、「あーいーうー」という発声から「あいう」という文字列を作る場合を考えてみましょう。RNNは「あー」や「いー」のように、引き伸ばされた音を認識します。シーティーシーは、「あ」が連続して出力されていることを認識し、「あ」を一つにまとめます。さらに、音と音の間の「空白」を取り除くことで、「あいう」という文字列を出力します。
このように、入力された音の長さと、出力される文字列の長さが違っても、シーティーシーはうまく対応できます。これが、シーティーシーが音声認識で高い精度を実現する理由です。シーティーシーは、音声を文字に変換する複雑な処理を、巧妙な仕組みで解決していると言えるでしょう。
CTCの利点

音声認識の技術において、シーティーシー(CTC)と呼ばれる手法は、多くの利点を持っています。中でも特筆すべきは、入力データと出力データの長さを一致させる必要がないということです。従来の音声認識では、音の波形データと、それに対応する文字列といった、入力と出力の長さを揃えるための複雑な前処理が必要でした。具体的には、音声を細かく切り分け、それぞれの断片に音素を割り当てるといった作業です。これは、まるでパズルのピースをはめるような、緻密で時間のかかる作業でした。しかし、シーティーシーを用いることで、この面倒な前処理を省略することができます。入力データの長さにかかわらず、出力データである文字列を直接得ることができるため、システム開発が飛躍的に容易になります。
シーティーシーのもう一つの利点は、認識精度が高いことです。従来の手法では、前処理の段階でどうしても誤りが生じやすく、それが最終的な認識精度に悪影響を及ぼしていました。シーティーシーでは、そのような誤りが発生する余地が少なく、より正確な認識結果を得ることができます。さらに、シーティーシーはリカレントニューラルネットワーク(RNN)と呼ばれる技術と組み合わせることで、その真価を発揮します。RNNは、過去の情報を記憶しながら処理を行うことができるため、時間とともに変化する音声データの解析に最適です。過去の情報を踏まえることで、現在の音だけでなく、前後の文脈も考慮した認識が可能になるため、より自然で正確な結果が得られます。シーティーシーとRNNの組み合わせは、音声認識の分野に革新をもたらし、既に様々な場面で目覚ましい成果を上げています。今後、更なる技術の進歩によって、私たちの生活をより豊かにする様々な応用が期待されています。
| 項目 | 説明 |
|---|---|
| 入力データと出力データの長さ | 一致させる必要がない。従来の音声認識のような、音の波形データと文字列の長さを揃える前処理が不要。 |
| 認識精度 | 高い。従来手法で問題だった前処理段階での誤りが少なく、正確な認識結果を得られる。 |
| RNNとの組み合わせ | RNNは過去の情報を記憶しながら処理できるため、音声データの解析に最適。シーティーシーと組み合わせることで、文脈を考慮した、より自然で正確な認識が可能。 |
CTCの応用

繋がりあった時系列の情報を扱う技術であるシーティーシーは、音声の認識以外にも、様々な分野で応用されています。この技術は、入力と出力の長さが違う場合でも、うまく対応できるという特徴を持っています。
例えば、手書きの文字を認識する場面を考えてみましょう。ペンで文字を書くと、ペンの動きに合わせてたくさんの位置情報が記録されます。これが入力データとなります。一方、出力は「あいうえお」といった文字列です。入力データに比べて、出力データはずっと短くなります。シーティーシーはこのような入力と出力の長さの差をうまく吸収し、文字を正しく認識することを可能にします。
また、音楽の認識にもシーティーシーは役立ちます。音楽の場合、入力データは録音された音声情報で、出力データは「ドレミファソラシド」といった音符の列です。音声データには、音符以外にも、演奏のニュアンスやノイズなど様々な情報が含まれています。シーティーシーはこれらの情報の中から必要な音符情報だけをうまく抽出し、楽譜を作成するのに役立ちます。
さらに、シーティーシーは動画の解析にも応用できます。動画の場合、入力データは連続した画像データで、出力データは動画の内容を表す短い文章になります。例えば、サッカーの試合の動画を入力すると、「シュートが決まった」といった内容の文章が出力されます。シーティーシーは、大量の画像データの中から重要な場面を捉え、動画の内容を簡潔にまとめることを可能にします。
このように、シーティーシーは様々な分野で活用され、私たちの生活をより便利で豊かなものにしてくれる技術です。今後ますます発展していくことが期待されます。
| 分野 | 入力データ | 出力データ |
|---|---|---|
| 手書き文字認識 | ペンの動き(位置情報) | 文字列(あいうえお) |
| 音楽認識 | 録音された音声情報 | 音符列(ドレミファソラシド) |
| 動画解析 | 連続した画像データ | 動画の内容を表す文章(例:シュートが決まった) |
CTCの今後の展望

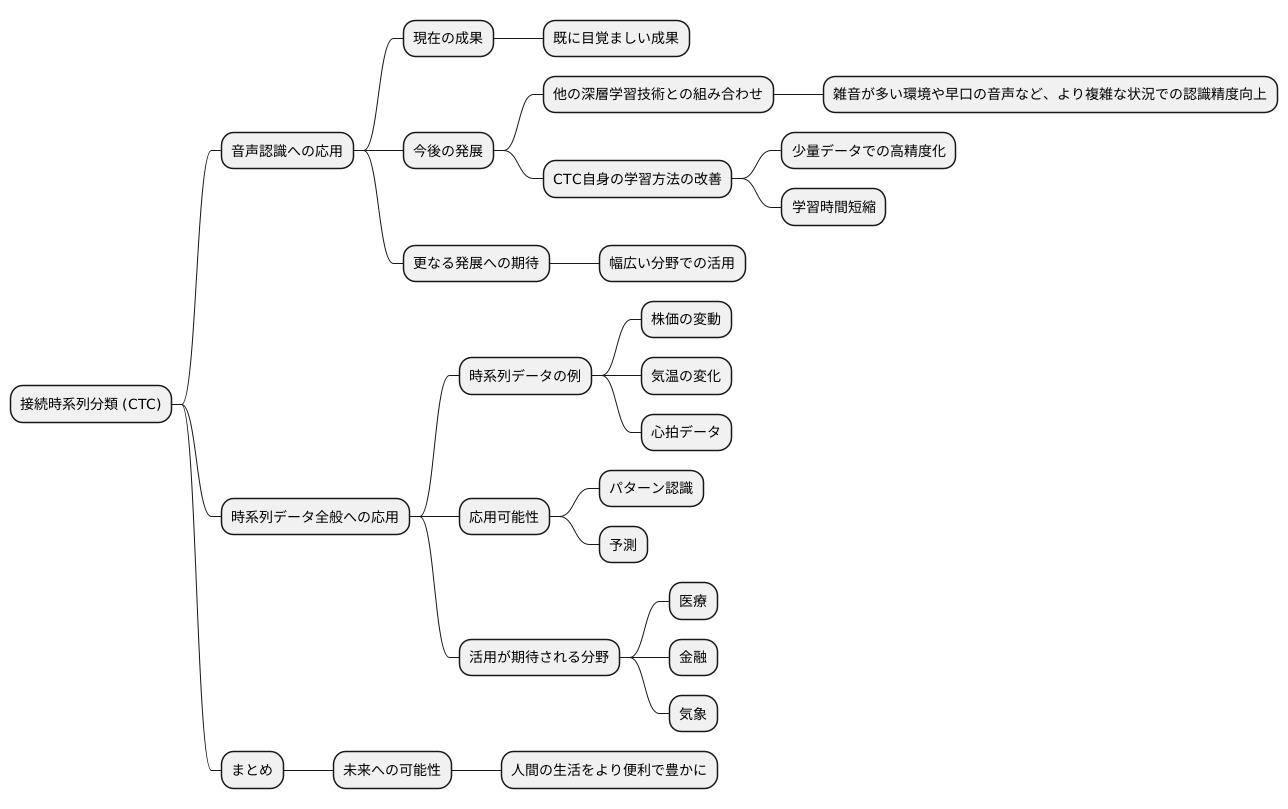
音声で文字を書き起こす技術、接続時系列分類(シーティーシー)は、既に音声認識の分野で目覚ましい成果を上げています。しかし、シーティーシーの進化はこれで終わりではありません。今後、更なる発展が期待されており、様々な角度からの研究開発が活発に進められています。例えば、シーティーシーと他の深層学習技術を組み合わせることで、認識精度を飛躍的に向上させる試みが注目を集めています。他の深層学習技術の長所を取り入れることで、シーティーシー単体では難しかった、雑音が多い環境や早口の音声など、より複雑な状況での認識精度向上を目指しています。また、シーティーシー自身の学習方法を改善する研究も進められています。学習方法を工夫することで、少ないデータ量でも高い精度を実現したり、学習にかかる時間を短縮したりすることが期待されています。これらの研究開発によって、シーティーシーの認識精度は更に向上し、ますます幅広い分野での活用が期待されます。
音声認識以外にも、シーティーシーは時系列データ全般を扱う技術としての可能性を秘めています。時系列データとは、時間とともに変化するデータのことで、例えば株価の変動や気温の変化、心拍データなどが挙げられます。シーティーシーは、これらの時系列データのパターン認識や予測にも応用できる可能性があり、医療、金融、気象など、様々な分野での活用が期待されています。人間と機械との意思疎通をよりスムーズにし、私たちの暮らしをより便利で豊かにしてくれる音声認識技術。シーティーシーは、この技術の進化を支える重要な柱の一つです。今後、シーティーシーがどのように進化し、どのような分野で活躍していくのか、目が離せません。シーティーシーの更なる発展は、私たちの未来を大きく変える可能性を秘めていると言えるでしょう。