
予測ドリフト:精度低下の要因を探る

AIを知りたい
先生、「予測ドリフト」ってよく聞くんですけど、何なのか詳しく教えてもらえますか?

AIエンジニア
ああ、予測ドリフトね。簡単に言うと、AIの予測精度が時間の経過とともに下がってしまう現象のことだよ。たとえば、以前はよく当たっていた天気予報が、だんだん外れるようになってしまう、みたいなイメージだね。
AIを知りたい
なるほど。どうしてそんなことが起きるんですか?
AIエンジニア
主な原因は二つあるよ。「概念ドリフト」と「データドリフト」だ。概念ドリフトは、予測の対象となるもの自体が変わってしまうこと。例えば、流行の服を予測するAIの場合、季節が変わって流行が変わると、予測が外れやすくなるよね。データドリフトは、AIの学習に使ったデータと、実際のデータに違いが出てくること。例えば、商品の売れ行きを予測するAIの場合、新しい競合商品が出てきたら、過去のデータに基づく予測は正確ではなくなるよね。
予測ドリフトとは。
人工知能で使われる「予測のずれ」という言葉について説明します。(機械学習や予測分析といった言葉も使われます。「予測のずれ」の起こる原因によっていろいろな言い方があり、主なものに「概念のずれ」と「データのずれ」があります。)
予測ドリフトとは

機械学習の模型は、過去の情報をもとに未来を予想します。まるで過去の天気図から明日の天気を予想するようにです。しかし、どんなに精巧な天気予報でも、外れることがありますよね。それと同様に、時間の流れとともに、模型の予想精度が落ちてしまうことがあります。これを予測のずれと呼びます。
作ったばかりの時は正確に予想できていた模型も、現実世界の情報は常に変化しています。まるで天気のように、気温や湿度、風の流れは刻一刻と変わっていきます。この変化に模型が対応できなくなると、現実と模型の間にはずれが生じ、予想が外れやすくなるのです。これが予測のずれの問題です。機械学習の模型を使う上で、常に気を付けなければならない重要な課題です。
なぜ模型と現実の間にずれが生じるのか、その原因を突き止め、適切な対策を行うことが、模型の信頼性を保つために欠かせません。原因としては、学習に使ったデータが古くなったり、現実世界で予期せぬ出来事が起こったりすることが考えられます。例えば、新しい流行が生まれたり、大きな社会的な変化が起きたりすると、過去のデータに基づく予想は役に立たなくなるかもしれません。
近年、機械学習の技術は目覚ましく進歩し、様々な分野で予測模型が活用されるようになりました。しかし、それと同時に予測のずれの問題は、これらの模型が長く使えるようにするための大きな壁となっています。模型の予想精度が下がると、仕事の判断に悪影響が出たり、提供する仕事の質が下がったりする危険性があります。そのため、予測のずれに適切に対処することは、機械学習の模型を使う上で避けて通れないと言えるでしょう。まるで天気予報が外れないように工夫を重ねるように、予測のずれを防ぐための努力が常に必要なのです。
二つの主な種類

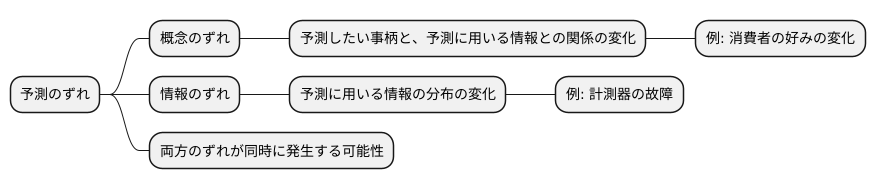
予測のずれには、大きく分けて二つの種類があります。それは、概念のずれと情報のずれです。
概念のずれとは、予測したい事柄と、それを予測するための情報との関係が変わってしまうことを指します。たとえば、ある商品の売れ行きを予測する数式で考えてみましょう。消費者の好みが変わると、以前は売れ行き予測に役立っていた情報が、時間の経過とともに予測の正確さに悪い影響を与えるようになることがあります。まるで、流行が変わって売れる商品が変わってしまうように、予測に使っていた情報が的外れになってしまうのです。
一方、情報のずれとは、予測に使う情報の分布そのものが変わってしまうことです。たとえば、計測器の故障や仕組みの変化などによって、集まる情報の値が以前とは異なる範囲でばらつくようになった場合、情報のずれが起きていると考えられます。温度計が壊れてしまい、いつもより高い温度を示してしまうような状況です。すると、その温度計の情報を使った予測は、本来の値からずれてしまうでしょう。
これらのずれは、別々に起きることもあれば、同時に起きることもあります。たとえば、消費者の好みが変わり(概念のずれ)、同時に新しい計測器を導入したために情報の集め方が変わり(情報のずれ)、両方のずれが同時に起きる可能性もあります。それぞれのずれの特徴をきちんと理解し、適切な対策をとることで、予測のずれによる悪い影響をできるだけ小さくすることができます。日頃からずれに気を付けて、予測の正確さを保つことが大切です。
概念ドリフトへの対処

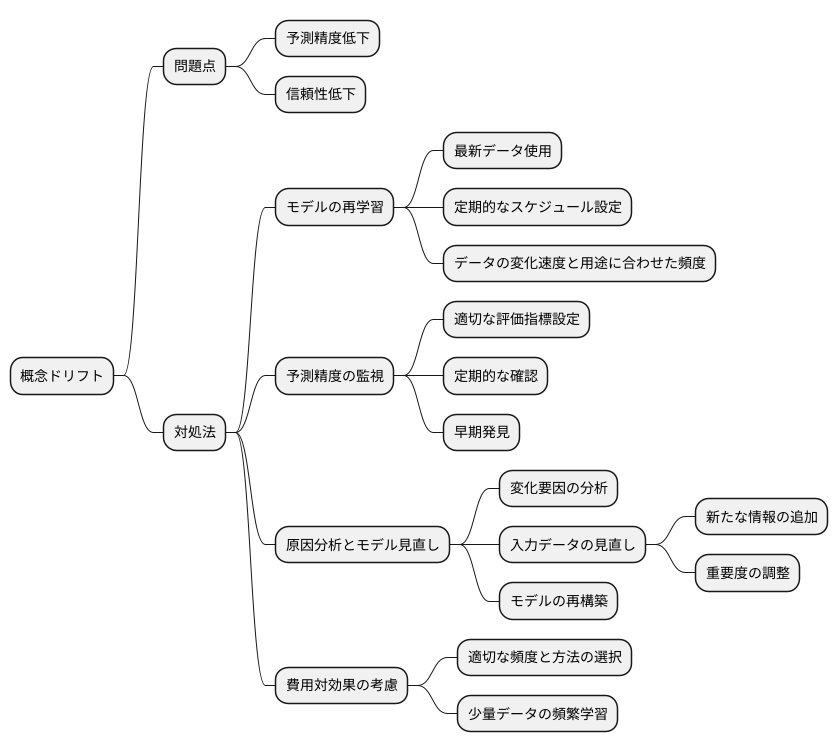
機械学習モデルは、学習時のデータの分布を基に未来を予測します。しかし、現実世界は常に変化し、時間の経過とともにデータの性質も変化していくため、当初の学習データと現実のデータの間にずれが生じることがあります。これが概念ドリフトと呼ばれる現象です。概念ドリフトが発生すると、モデルの予測精度が低下し、信頼できる結果を得ることが難しくなります。
概念ドリフトに対処する上で最も重要なのは、モデルの再学習です。現実世界を反映した最新のデータを使ってモデルを再トレーニングすることで、変化したデータの分布に適応させ、予測精度を回復させることができます。再学習の頻度は、データの変化の速さやモデルの用途によって異なりますが、定期的な再学習のスケジュールを立てておくことが有効です。
さらに、モデルの予測精度を継続的に監視することも重要です。これは、概念ドリフトの兆候を早期に発見するために必要です。予測精度が低下し始めた場合は、概念ドリフトが発生している可能性が高いと言えるでしょう。監視には、適切な評価指標を設定し、定期的にその値を確認することが求められます。
概念ドリフトは、予測対象の事象と入力データとの関係性の変化によって発生します。そのため、変化の要因を分析し、必要に応じてモデルの構造や入力データを見直すことが重要です。例えば、新たな情報を表す入力データを追加したり、既存の入力データの重要度を調整することで、予測精度を向上させることができる場合があります。場合によっては、モデル自体を再構築する必要も出てきます。
ただし、モデルの再学習には計算時間や資源が必要となるため、費用対効果を考慮しながら、適切な頻度と方法を選択することが重要です。一度に大量のデータを再学習するよりも、少量のデータを頻繁に学習させる方が効果的な場合もあります。状況に応じて最適な方法を選択しましょう。
データドリフトへの対処

機械学習モデルは、時間の経過と共に予測精度が低下することがあります。これは、学習時と運用時でデータの性質が変化してしまう「データドリフト」と呼ばれる現象が原因の一つです。このデータドリフトに対処するためには、様々な方法があります。
まず、入力データに紛れ込んだおかしな値、つまり異常値を見つけ出して修正することが重要です。データの性質が変化すると、通常では考えにくい値が出現する可能性が高まります。これらの異常値はモデルの学習を妨げ、予測精度を低下させる原因となります。異常値を適切に見つけ出し、修正、あるいは取り除くことで、データドリフトの影響を和らげることができます。
次に、入力データの正規化も有効な手段です。これは、データの範囲を調整し、一定の範囲内に収める処理のことです。例えば、あるデータの範囲が0から100、別のデータの範囲が0から1万だった場合、これらのデータをそのまま使うと、範囲の広いデータがモデルに過剰な影響を与えてしまう可能性があります。正規化を行うことで、このような偏りを防ぎ、データの分布を安定させることができます。結果として、モデルの予測精度が向上する効果も期待できます。
さらに、データドリフトの根本原因に対処することも重要です。例えば、システムの変更やデータの取得方法の変化がデータドリフトを引き起こしている場合、これらの原因を特定し、修正することで、データドリフトの発生自体を抑えることができます。データの取得方法を見直したり、前処理の方法を改善したりすることで、データの品質を維持し、データドリフトを防ぐことができます。
このように、データドリフトへの対処は、入力データの品質管理と密接に関係しています。データの品質を常に監視し、問題があれば迅速に対処することで、機械学習モデルの性能を維持し、信頼性の高い予測結果を得ることが可能になります。そのため、データの品質を保つための継続的な取り組みが欠かせません。
| 対策 | 説明 | 効果 |
|---|---|---|
| 異常値の検出と修正 | 入力データに紛れ込んだおかしな値(異常値)を見つけ出して修正または削除する。 | データドリフトの影響を和らげ、モデルの学習を改善する。 |
| 入力データの正規化 | データの範囲を調整し、一定の範囲内に収める。 | データの偏りを防ぎ、分布を安定させ、予測精度を向上させる。 |
| データドリフトの根本原因への対処 | システムの変更やデータの取得方法の変化など、ドリフトの原因を特定し修正する。 | データドリフトの発生自体を抑え、データの品質を維持する。 |
監視の重要性

機械学習を用いた予測は、世の中の様々な場面で活用されていますが、時間の経過と共に予測の精度が落ちる「予測ずれ」は常に付きまとう問題です。この予測ずれに対処するには、モデルの予測精度と入力データの傾向を常に見ておく「監視」がとても大切です。
監視によって、予測ずれの兆候を早期に見つけることができれば、素早く対応して、予測精度の低下を最小限に食い止めることができます。では、具体的にどのような監視を行うのでしょうか。まず、モデルの予測精度を評価するためには、正解率や適合率といった指標を使います。正解率は、全体の予測のうちどれだけが当たっていたかを示す割合です。適合率は、当たっていると予測したものの中で、実際に当たっていたものの割合です。これらの指標を見ることで、モデルがどれくらい正確に予測できているかを測ることができます。
入力データの傾向の変化を知るためには、統計的な指標や図表を使うと便利です。例えば、データの平均値やばらつき具合を示す標準偏差といった統計値を計算することで、データの分布がどのように変化しているかを捉えることができます。また、図表を用いてデータを視覚的に表示すれば、データの異常値や変化の傾向を一目で把握することができます。
これらの指標を定期的に確認し、いつもと違う値や変化の兆候を掴むことで、予測ずれの発生を早期に察知し、適切な対応策を講じることができるのです。例えば、モデルの再学習が必要だと判断すれば、最新のデータを使ってモデルを学習し直すことで、予測精度を向上させることができます。あるいは、入力データに異常な値が含まれている場合は、データの前処理方法を見直すことで、予測ずれを防ぐことができます。
監視体制を整え、継続的に様子を見ていくことは、予測ずれによる危険性を減らし、機械学習モデルの信頼性を保つために欠かせないと言えるでしょう。常に気を配り、適切な対応を行うことで、より正確で信頼できる予測結果を得ることが可能になります。
| 監視対象 | 指標 | 目的 |
|---|---|---|
| モデルの予測精度 | 正解率 | 全体の予測のうち、当たっていた割合を測る |
| 適合率 | 当たっていると予測したものの中で、実際に当たっていた割合を測る | |
| 入力データの傾向 | 平均値、標準偏差 | データの分布の変化を捉える |
| 図表 | データの異常値や変化の傾向を視覚的に把握する |
将来の展望

機械学習の予測において、時間の経過と共に予測精度が低下する「予測ずれ」は、大きな課題となっています。この予測ずれは、学習に使ったデータと運用中のデータの性質が変化することに起因しており、その対策は機械学習分野の重要研究課題の一つです。
近年、この予測ずれを自動的に見つけ、対応する技術開発が活発に行われています。これらの技術によって、機械学習の運用を効率化し、予測精度を維持しやすくなることが期待されます。
予測ずれに対応する手法として、オンライン学習や複数の学習モデルを組み合わせるアンサンブル学習などが注目されています。オンライン学習は、新しいデータが得られる度にモデルを更新することで、データの変化に対応します。アンサンブル学習は、複数のモデルの予測結果を組み合わせることで、一つのモデルよりも変化に強い予測を実現します。これらの手法は、データの変化に柔軟に対応し、予測精度を保つ上で有効な方法です。
さらに、予測ずれの発生を事前に予測する技術の研究も進んでいます。もし、予測ずれが起きる前に予測できれば、事前に対策を準備することができ、より効果的に予測ずれの影響を抑えることが可能になります。将来は、このような予測に基づく予防的な対策が実現するかもしれません。
これらの技術発展によって、予測ずれへの対応はより高度になり、機械学習モデルの信頼性と安定性は向上していくと期待されます。それと同時に、これらの技術を使いこなせる人材育成も重要な課題です。機械学習技術の進化と共に、予測ずれへの理解と対策能力の重要性はますます高まっていくでしょう。
| 課題 | 原因 | 対策 | 将来展望 |
|---|---|---|---|
| 予測ずれ(予測精度の低下) | 学習データと運用データの性質の変化 | オンライン学習 アンサンブル学習 予測ずれの事前予測技術 |
予測ずれの事前予測に基づく予防的対策の実現 機械学習モデルの信頼性と安定性の向上 予測ずれ対応人材育成の必要性 |