 アルゴリズム
アルゴリズム コードマイグレーション×AI:フレームワーク・言語間の移行支援
AIを知りたい古いフレームワークやライブラリから新しいものに移行したいんですが、大変そうで踏み切れません…AIエンジニアコードマイグレーションはAIが最も威力を発揮する分野の一つです。ReactのクラスコンポーネントからHooksへの移行、...

記事数:(428)
アルゴリズム  WEBサービス
WEBサービス  WEBサービス
WEBサービス 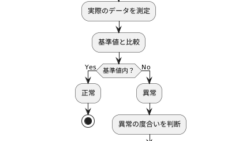 WEBサービス
WEBサービス  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  WEBサービス
WEBサービス  クラウド
クラウド  クラウド
クラウド  WEBサービス
WEBサービス  アルゴリズム
アルゴリズム 