
精度検証データ:モデルチューニングの鍵

AIを知りたい
先生、「精度検証データ」って、何ですか? モデルの性能を評価する時に使うデータらしいのですが、いまいちよく分かりません。

AIエンジニア
良い質問だね。モデルの性能評価には、大きく分けて「訓練データ」「精度検証データ」「テストデータ」の3種類を使うんだ。訓練データはモデルを作るための学習データ、テストデータは完成したモデルの最終的な性能をチェックするためのデータだよ。では、精度検証データは何のために使うか分かるかな?
AIを知りたい
えっと、訓練データとテストデータ以外…ということは、モデルの調整に使うんでしょうか?
AIエンジニア
その通り! 精度検証データは、モデルの学習中に、作ったモデルがどのくらいうまく学習できているかを確認し、調整するために使うデータなんだ。例えば、より良い結果になるように、モデルのパラメータを調整するのに使うんだよ。
精度検証データとは。
人工知能に関わる言葉である「精度検証データ」について説明します。これは、作った模型がどれくらいうまく動くかを調べたり、より良くするための調整に使うデータのことです。
精度検証データとは

機械学習の仕組みを作る際、その仕組みがどれほどきちんと予測できるのかを確かめることはとても大切です。この確認作業を正しく行うために、「精度検証データ」と呼ばれるデータの集まりを使います。精度検証データは、仕組みを作るための学習には使わず、出来上がった仕組みの性能を測るためだけの特別なデータです。例えるなら、学校の試験問題のようなものです。
仕組みは、学習用のデータで学びます。そして、その学習の成果を精度検証データを使って試すことで、本当の力を測ることができます。この検証作業を通して、仕組みの正確さや、様々なデータにも対応できる能力を客観的に評価し、より良い仕組みへと改良していくことができます。
たとえば、天気予報の仕組みを作る場面を考えてみましょう。過去の天気データを使って学習させ、明日の天気を予測する仕組みを作るとします。この時、学習に使ったデータでそのまま予測精度を測ると、高い精度が出るかもしれません。しかし、それは過去に起こった天気を覚えているだけで、未来の天気、つまり未知の天気を予測できるかどうかは分かりません。
そこで、精度検証データの出番です。学習には使っていない、別の日の天気データを使って、仕組みの予測精度を測ります。これにより、初めて見るデータに対しても、きちんと予測できるかどうかを確かめることができます。もし予測精度が低ければ、仕組みの改良が必要です。例えば、使うデータの種類を増やしたり、予測方法を調整したりするなど、様々な工夫が必要になります。
このように、精度検証データは、未知のデータに対しても正確な予測ができる仕組みを作るために、欠かせない役割を担っているのです。
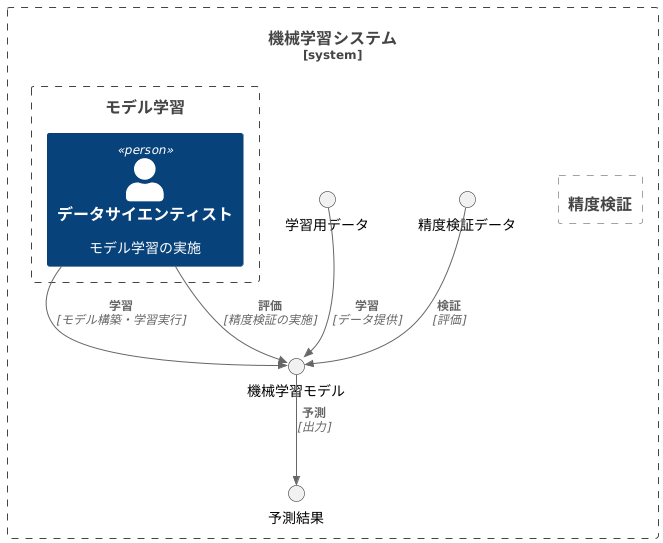
訓練データとの違い

機械学習モデルを作るには、学習用の情報とテスト用の情報の二種類が必要です。これらはどちらも大切ですが、役割が違います。
学習用の情報は、例えるなら生徒に渡す教科書のようなものです。生徒はこの教科書の内容を一生懸命覚えて、問題の解き方を学びます。機械学習モデルも、学習用の情報からパターンや規則性を学び、予測を行うための知識を身につけます。
一方、テスト用の情報は、学習した内容をどれくらい理解しているかを確認するための試験問題のようなものです。生徒が教科書の内容を丸暗記しただけでは、応用問題に対応できないことがあります。これと同じように、機械学習モデルも学習用の情報だけに最適化してしまうと、新しい情報に対して正確な予測ができなくなることがあります。このような状態を過学習といいます。
過学習は、まるで試験前に教科書を丸暗記した生徒が、試験本番で教科書に載っていない問題が出題されると全く解けなくなってしまうようなものです。試験で良い点を取るためには、教科書の内容を理解し、様々な問題に応用できる力が必要です。
機械学習モデルでも同じように、未知の情報に対しても正確な予測をするためには、テスト用の情報を使って汎化能力を高める必要があります。テスト用の情報は、モデルの調整やより良い計算方法を選ぶ際に役立ちます。具体的には、テスト用の情報での結果を見て、モデルが複雑すぎる場合は調整したり、より適切な計算方法を探したりします。
このように、学習用の情報とテスト用の情報を適切に使い分けることで、過学習を防ぎ、様々な情報に対応できる、より精度の高い機械学習モデルを作ることができるのです。
| データの種類 | 役割 | 例え | モデルにおける働き | 問題点(過学習) |
|---|---|---|---|---|
| 学習用データ | モデルにパターンや規則性を学習させる | 教科書 | 知識の習得 | 学習用データだけに最適化され、新しいデータへの対応力が低い状態 |
| テスト用データ | 学習した内容の理解度を確認し、汎化能力を高める | 試験問題 | モデルの調整、計算方法の選択 |
テストデータとの関係

機械学習モデルを作る際には、そのモデルがどれくらいうまく動くかを確かめる必要があります。このために、集めたデータを学習用データ、精度検証データ、テストデータの3つに分けます。学習用データは、いわば教科書のようなもので、モデルに知識を教え込むために使います。精度検証データとテストデータは、学習したモデルがどれくらい理解しているか、試すための試験のようなものです。
精度検証データは、模擬試験のような役割を果たします。モデルに学習させた後、精度検証データを使って、まだ十分に学習できていない部分を見つけます。この結果を基に、モデルの細かい調整を繰り返し行い、性能を高めていきます。何度も模擬試験を受けて、間違えた問題の復習をすることで、点数が上がるのと同じです。
一方、テストデータは本試験のようなものです。これは、モデルの最終的な性能を測るために一度だけ使われます。何度も模擬試験を受けて対策を練ると、本試験の内容を予測できてしまい、本当の力が測れません。同様に、テストデータを何度も使ってモデルを調整してしまうと、テストデータだけに特化したモデルになってしまい、真の性能が分からなくなります。そのため、テストデータは最後の最後に、一度だけ使うようにします。
このように、精度検証データとテストデータはどちらもモデルの性能を測るためのデータですが、その役割は大きく異なります。精度検証データを使ってモデルを鍛え上げ、最後にテストデータで本当の力を測ることで、より信頼性の高い機械学習モデルを作ることができます。
| データの種類 | 役割 | 使用方法 |
|---|---|---|
| 学習用データ | モデルに知識を教え込むための教科書 | モデルの学習に使用 |
| 精度検証データ | モデルの理解度を測るための模擬試験 | モデルの調整に使用 (複数回) |
| テストデータ | モデルの最終的な性能を測るための本試験 | モデルの最終評価に使用 (1回のみ) |
データ分割の重要性

機械学習の分野では、精度の高い予測モデルを作るために、集めたデータをいくつかのグループに分けることが欠かせません。この作業をデータ分割と言い、大きく分けて訓練データ、精度検証データ、テストデータの3つに分けます。それぞれのデータには役割があり、これを正しく理解し適切な割合で分けることで、モデルの性能を最大限に高めることができます。
まず、訓練データは、モデルに学習させるためのデータです。人間で例えるなら、教科書や問題集のようなものです。このデータを使って、モデルは予測するためのパターンや規則性を学びます。訓練データは、集めたデータの大部分、一般的には全体の7割程度を割り当てます。
次に、精度検証データは、学習中のモデルの精度を確かめるためのデータです。学習途中のテストのようなもので、訓練データでは高い精度が出ていても、新たなデータでは精度が低いということがよくあります。精度検証データを使って、モデルが未知のデータに対してもきちんと予測できるかを確認し、必要に応じてモデルの調整を行います。一般的には、全体の1割半程度を割り当てます。
最後に、テストデータは、モデルの最終的な性能を評価するためのデータです。これは、本番の試験のようなもので、モデルの開発が全て完了した後に一度だけ使用します。テストデータを使うことで、モデルが実際に使用された際にどの程度の精度で予測できるかを測ることができます。こちらも全体の1割半程度を割り当てます。
データの量や種類によっては、これらの割合を変える必要がある場合もあります。例えば、データ量が非常に多い場合は、精度検証データやテストデータの割合を減らしても問題ありません。また、データの種類によっては、特定の特徴を持つデータを各グループに均等に分配する必要がある場合もあります。適切なデータ分割は、モデルが特定のデータに偏って学習してしまうことを防ぎ、様々なデータに対しても正しく予測できる能力、汎化性能を高めるために不可欠です。データの偏りがないよう適切に分割することで、信頼性の高いモデルを作ることができます。
| データの種類 | 役割 | 割合 |
|---|---|---|
| 訓練データ | モデルの学習用データ (教科書・問題集) | 70% |
| 精度検証データ | 学習中モデルの精度確認用データ (中間テスト) | 15% |
| テストデータ | モデルの最終性能評価用データ (本番試験) | 15% |
実践的な活用例

機械学習の様々な場面で、精度を確かめるためのデータは欠かせないものとなっています。このデータを使うことで、作った模型がどれくらいうまく働くのかを調べ、より良いものへと改良していくことができます。
例えば、写真を見て何が写っているかを当てる画像認識の作業を考えてみましょう。この作業では、たくさんの写真データを使います。これらのデータは、模型を鍛えるための訓練データ、模型の精度を確かめるための精度検証データ、そして最後に模型の実力を測るためのテストデータの三つに分けて使われます。模型の訓練が終わったら、精度検証データを使って、模型の細かい部分を調整します。ちょうど、料理の味を微調整するように、この作業を繰り返すことで、より正確に写真の内容を認識できる模型を作ることができるのです。
言葉に関する作業である自然言語処理でも、精度検証データは重要な役割を担います。例えば、ある言葉を別の言葉に置き換える機械翻訳の模型作りを考えてみましょう。この場合、精度検証データを使って翻訳の正確さを評価し、模型の改良を繰り返します。翻訳の精度が低い場合は、模型の仕組みを修正し、再度精度検証データを使って評価を行います。この作業を繰り返すことで、より自然で正確な翻訳ができる模型へと改良していくことができます。
このように、精度検証データは機械学習の模型作りにおいて、なくてはならないものとなっています。写真を見て何が写っているかを認識する、言葉を別の言葉に翻訳するなど、様々な分野で活用され、より精度の高い模型を作るために役立っています。まるで、職人が自分の作品をより良いものへと磨き上げるために使う道具のように、精度検証データは機械学習の進歩を支える重要な要素と言えるでしょう。
| 分野 | タスク例 | 精度検証データの役割 |
|---|---|---|
| 画像認識 | 写真の内容認識 | 模型の微調整、より正確な認識 |
| 自然言語処理 | 機械翻訳 | 翻訳の正確さ評価、模型の改良 |