
教師なし学習:データの宝探し

AIを知りたい
『教師なし学習』って、どんなものですか?

AIエンジニア
いい質問だね。『教師なし学習』とは、人間が正解を教えずに、コンピュータが自分でデータの特徴やパターンを見つける学習方法だよ。例えば、たくさんの猫と犬の画像をコンピュータに見せて、『似ているもの同士をまとめてグループ分けしてごらん』と指示するようなものだね。
AIを知りたい
つまり、コンピュータが自分で考えてグループ分けするんですね。具体的にどんな時に使うんですか?
AIエンジニア
そうだね。例えば、顧客の購買履歴から顧客をグループ分けして、それぞれに合った広告を配信する時などに役立つよ。他にも、大量のデータの中から異常なデータを見つける時にも使われるんだ。
教師なし学習とは。
人工知能に関わる言葉である「教師なし学習」について説明します。教師なし学習とは、機械学習の学習方法の一つで、正解が示されていない状態でも学習を進める方法です。主なやり方として、主成分分析、集団分け、そして生成モデルといったものがあります。
ラベルなしデータからの学び

教師なし学習とは、正解となるラベルや指示がないデータから、独自の規則性や構造を発見する機械学習の手法です。まるで、広大な砂漠に隠された宝物を、地図なしで探し出すような作業と言えるでしょう。一見すると途方もない作業に思えますが、この手法はデータの奥深くに眠る貴重な情報を見つけ出す強力な道具となります。
従来の機械学習では、正解ラベル付きのデータを用いて学習を行う教師あり学習が主流でした。しかし、正解ラベルを用意するには、多大な費用と時間が必要となる場合が少なくありません。そこで、ラベルのない大量のデータからでも知識を抽出できる教師なし学習が注目を集めています。例えば、顧客の購買履歴といったラベルのないデータから、顧客をいくつかのグループに分け、それぞれのグループに適した販売戦略を立てることができます。
教師なし学習の代表的な手法の一つに、クラスタリングがあります。これは、データの特徴に基づいて、似たものをまとめてグループ分けする手法です。顧客の購買履歴を例に挙げると、頻繁に特定の種類の商品を購入する顧客を一つのグループとしてまとめることができます。他にも、次元削減という手法があります。これは、データの持つ情報をなるべく損なわずに、データの次元(特徴の数)を減らす手法です。データの次元が減ることで、データの可視化や分析が容易になります。高次元のデータは人間が理解するには複雑すぎるため、次元削減によってデータの本質を捉えやすくします。
このように、教師なし学習はデータの背後に隠された関係性を明らかにすることで、私たちがより良い判断をするための手助けとなります。ラベル付きデータの不足を補い、新たな知見の発見を促す教師なし学習は、今後のデータ活用の鍵となるでしょう。
| 教師なし学習 | 説明 | 例 |
|---|---|---|
| 概要 | 正解ラベルのないデータから規則性や構造を発見する機械学習の手法。 | 広大な砂漠で地図なしで宝探しをするような作業。 |
| 利点 | ラベル作成の費用と時間を削減できる。大量のデータから知識抽出が可能。 | 顧客の購買履歴から販売戦略を立てる。 |
| 手法: クラスタリング | データの特徴に基づいて似たものをグループ分けする。 | 特定の商品を購入する顧客をグループ化。 |
| 手法: 次元削減 | データの情報をなるべく損なわずに次元数を減らす。データの可視化や分析が容易になる。 | 高次元のデータを人間が理解しやすくする。 |
| 将来性 | ラベル付きデータ不足を補い、新たな知見発見を促す、データ活用の鍵となる手法。 | – |
主な手法とその役割

教師なし学習とは、正解となるデータが与えられていない状況で、データの構造や特徴を捉える機械学習の一種です。様々な手法が存在しますが、ここでは代表的な三つの手法、主成分分析、クラスタリング、そして生成モデルについて詳しく見ていきます。
まず、主成分分析は、多次元のデータをより少ない次元で表現する手法です。例えば、数百項目ものアンケート結果を分析する場合、全ての項目をそのまま扱うのは大変です。主成分分析を用いることで、これらの項目の中から重要な要素を抽出し、少数の指標でデータを表現することができます。これにより、データの全体像を把握しやすくなり、可視化も容易になります。また、不要な情報を取り除くことで、ノイズを減らす効果も期待できます。
次に、クラスタリングは、データ同士の類似度に基づいてデータをグループ分けする手法です。例えば、顧客の購買履歴データから、似たような購買傾向を持つ顧客をグループ化することができます。これを顧客の分類に利用することで、それぞれのグループに合わせた販売戦略を立てることが可能になります。また、通常とは異なる行動パターンを示すデータを見つけ出すことで、不正利用の検知などに役立てることもできます。
最後に、生成モデルは、既存のデータからそのデータが持つ特徴やパターンを学習し、新しいデータを作り出す手法です。例えば、大量の画像データを学習させることで、まるで人間が描いたかのような新しい画像を生成することができます。この技術は、画像生成だけでなく、音声合成や文章生成など、様々な分野で応用されています。
これらの手法は、いずれも正解ラベルを用いずにデータから知識や洞察を得ることを目的としており、データ分析の様々な場面で活用されています。
| 手法 | 説明 | 例 | 利点 |
|---|---|---|---|
| 主成分分析 | 多次元のデータをより少ない次元で表現する手法 | 数百項目のアンケート結果から重要な要素を抽出 | データの全体像把握、可視化、ノイズ削減 |
| クラスタリング | データ同士の類似度に基づいてデータをグループ分けする手法 | 顧客の購買履歴データから顧客をグループ化 | 顧客分類、販売戦略策定、不正利用検知 |
| 生成モデル | 既存のデータから特徴やパターンを学習し、新しいデータを作り出す手法 | 画像データから新しい画像を生成 | 画像生成、音声合成、文章生成 |
次元削減による洞察

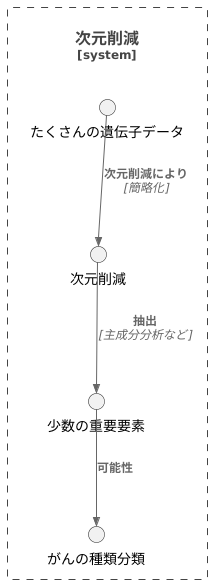
たくさんの情報を持つデータは、扱うのがとても大変です。情報の数が多すぎると、データを見たり調べたりするのが難しくなります。例えば、たくさんの遺伝子の働き具合を一度に調べようとすると、複雑すぎてよく分からなくなってしまいます。このようなたくさんの情報を扱う問題を解決するために、次元削減という方法が使われます。次元削減とは、データの持つたくさんの情報を、より少ない情報にまとめる方法です。
例として、数百種類の遺伝子の働き具合のデータがあるとします。このデータは複雑で、そのままでは理解しにくいものです。しかし、次元削減を使うことで、数百種類の遺伝子の働き具合を、少数の重要な要素にまとめることができます。この少数の要素は、元のデータの重要な特徴を表しています。これらの要素を見ることで、がんの種類を分類できる可能性があります。
次元削減の方法の一つに、主成分分析というものがあります。これは、データの中に隠れている関係性を見つけ出し、情報をよりコンパクトにまとめる方法です。主成分分析を使うことで、たくさんの遺伝子の働き具合のデータから、少数の主要な成分を取り出すことができます。これらの主要な成分は、元のデータのほとんどの情報を表しています。
このように、次元削減は、複雑なデータを分かりやすく整理し、隠れた関係性を見つけるのに役立ちます。遺伝子の働き具合のデータだけでなく、様々な分野のデータ分析に利用されています。次元削減を使うことで、データの全体像を把握しやすくなり、重要な情報を見逃すことなく、より深い理解に繋がるのです。
類似性に基づくグループ分け

似たもの同士をまとめる作業を、よく耳にする言葉で言うと、集団分けと言います。この集団分けは、様々な場面で役立ちます。例えば、お店でお客さんの買い物情報を集めて、よく似た買い物の仕方をするお客さん同士を同じ集団にまとめることができます。
この集団分けの方法の一つに、似ている度合いを見て集団を作るやり方があります。これは、データの山から似た特徴を持つものを探し出し、いくつかの集団に分ける方法です。具体例として、お客さんの買い物記録を思い浮かべてみてください。あるお客さんは、よくお菓子と飲み物を一緒に買います。別のお客さんも、同じようにお菓子と飲み物を一緒に買うことが多いとします。このように買い物の傾向が似ているお客さん同士を同じ集団にまとめるのです。
こうして集団分けすることで、それぞれに合った接し方が見えてきます。例えば、お菓子と飲み物をよく一緒に買うお客さんの集団には、セット割引の広告を出すと効果的かもしれません。また、よく野菜を買うお客さんの集団には、健康を意識した商品の広告を出す方が効果的でしょう。このように、お客さんの集団ごとに合わせた売り方をすることで、より多くの商品を買ってもらえる可能性が高まります。
この集団分けの技術は、お客さんの集団分け以外にも、様々な分野で使われています。例えば、似た症状を持つ病気の集団分けや、似た性質を持つ物質の集団分けなどです。たくさんのデータの中から、隠れた関係性を見つけることで、より深く物事を理解し、適切な判断をするための助けとなります。似ている度合いを見て集団を作る方法は、データの持つ意味を明らかにし、私たちがより良い選択をするための、とても役立つ手段と言えるでしょう。
| 集団分け(クラスタリング) | 概要 | 例 | メリット |
|---|---|---|---|
| 似ている度合いを見て集団を作る | データから似た特徴を持つものを探し、いくつかの集団に分ける | お菓子と飲み物を一緒に買う客、野菜をよく買う客 | 集団ごとに最適な接し方(例:セット割引、健康志向商品の広告)ができるため、購買意欲を高める可能性がある |
| その他の応用 | 様々な分野で利用可能 | 似た症状の病気、似た性質の物質 | 隠れた関係性の発見、深い理解、適切な判断の補助 |
データ生成の新時代

近年の技術革新により、データを作る新しい時代が到来しました。これは、まるで魔法の箱のような「生成モデル」と呼ばれる技術のおかげです。この生成モデルは、既存のデータの特徴を学び、全く新しいデータを作り出すことができます。
従来、データを集めるには多大な時間と労力が必要でした。例えば、新しい製品の性能を評価するには、何度も実験を繰り返してデータを集める必要がありました。また、芸術家は、新しい作品を生み出すために、長い時間をかけて技術を磨く必要がありました。しかし、生成モデルを使うことで、これらの作業を大幅に効率化することができます。
具体的には、絵画の分野では、特定の画家の作品を学習させることで、その画家の作風に似た新たな絵画を生成することができます。まるでその画家が描いたかのような、繊細なタッチや色使いまで再現することが可能です。また、音声の分野でも、人の声を学習させることで、その人の声質や抑揚にそっくりな音声を作り出すことができます。まるで本人が話しているかのような自然な音声が生成できるため、音声案内や読み上げサービスなど、様々な場面での活用が期待されています。
文章の作成にも生成モデルは活用できます。大量の文章データを学習させることで、まるで人が書いたかのような自然で流暢な文章を生成することが可能です。例えば、ニュース記事や小説、詩などを自動生成することも夢ではなくなりました。
このように、生成モデルは様々な分野で革新的な変化をもたらすと期待されています。今後、生成モデルの技術が進化していくことで、私たちの生活はより豊かで便利なものになっていくでしょう。創造性を刺激し、新しい価値を創造する生成モデルは、まさにデータ生成の新時代を切り開く鍵と言えるでしょう。
| 分野 | 従来の方法 | 生成モデルによる方法 | メリット | 活用例 |
|---|---|---|---|---|
| 製品開発 | 何度も実験を繰り返す | 既存データから新製品の性能データを生成 | 時間と労力の削減 | – |
| 絵画 | 画家が長い時間をかけて技術を磨く | 特定の画家の作品を学習し、似た絵画を生成 | 画家の作風の再現、効率化 | 新しい絵画の生成 |
| 音声 | – | 人の声を学習し、似た音声を生成 | 自然な音声生成 | 音声案内、読み上げサービス |
| 文章 | 人が書く | 大量の文章データを学習し、自然な文章を生成 | 自動文章生成 | ニュース記事、小説、詩の自動生成 |
教師なし学習の未来

近年、人工知能の分野において、自ら学ぶ能力を持つ機械学習が注目を集めています。その中でも、人間による指示を必要としない教師なし学習は、今後の発展に大きな期待が寄せられています。
教師なし学習とは、大量のデータの中から、共通する特徴や隠れたパターンを自動的に見つける手法です。例えば、猫の画像を大量に与えると、人間が「これは猫です」と教えることなく、猫の特徴を自ら学習し、新しい画像を見せても猫だと判断できるようになります。
現在、インターネット上には膨大な量のデータが存在していますが、そのほとんどは整理されていないラベルなしデータです。教師なし学習は、これらのデータを有効活用できるという点で、非常に強力な手法と言えるでしょう。従来の教師あり学習では、人間がデータ一つ一つに「猫」「犬」などのラベルを付ける必要がありましたが、教師なし学習ではその手間が省け、より多くのデータを効率的に活用できます。
特に、深層学習と呼ばれる技術と組み合わせることで、教師なし学習は更なる進化を遂げると期待されています。深層学習は、人間の脳の神経回路を模倣した複雑なモデルを用いることで、高度な学習能力を実現します。この深層学習と教師なし学習を組み合わせることで、これまで以上に複雑なデータの分析や、より高度な予測が可能になると考えられます。
教師なし学習の応用範囲は幅広く、医療、金融、製造業など、様々な分野で活用が期待されています。医療分野では、病気の早期発見や新薬開発に役立つ可能性があります。金融分野では、不正取引の検知や市場予測に活用できるでしょう。製造業では、製品の品質管理や生産効率の向上に貢献することが期待されます。
このように、教師なし学習は、私たちの生活をより豊かに、より便利にする可能性を秘めた技術です。今後、更なる研究開発が進み、様々な分野で革新的な技術が生まれることに期待が高まります。
| 教師なし学習 | 大量のデータから共通点や隠れたパターンを自動的に見つける手法 |
|---|---|
| メリット |
|
| 応用分野 |
|