
UCB方策:未知への挑戦

AIを知りたい
先生、『UCB方策』って、聞いたことがないのですが、どんなものですか?

AIエンジニア
UCB方策は、試行錯誤を通じて一番良い行動を見つけるための方法だよ。色々な行動の中から、まだあまり試していない行動を優先的に選んでいくんだ。宝箱がたくさんあって、どの宝箱に一番良い宝物が入っているか分からない時、まだ開けていない宝箱を優先的に開けていくイメージだね。
AIを知りたい
なるほど。でも、ずっと試していない行動ばかり選んでいたら、良い行動を見逃してしまうこともあるんじゃないですか?
AIエンジニア
その通り!UCB方策は、単に試した回数が少ない行動を選ぶだけじゃなくて、これまで得られた結果も考慮に入れて、一番良い結果が期待できる行動を選んでいるんだ。だから、良い行動も見逃しにくい仕組みになっているんだよ。
UCB方策とは。
人工知能で使われる言葉、「ユーシービーほうさく」について説明します。 ユーシービーほうさくとは、機械学習の一種である強化学習で使われる考え方です。 強化学習では、一番良い結果になる行動を選ぶために、それぞれの行動の情報が必要です。 ユーシービーほうさくは、まだ試した回数が少ない行動を優先的に選び、情報を集める方法です。
はじめに

機械学習の中でも、強化学習は独特な学習方法です。まるで迷路の中でゴールを目指すように、学習する主体は様々な行動を試みます。そして、各行動の結果として得られる報酬を手がかりに、最適な行動を見つけ出すのです。この学習方法は、まさに試行錯誤の繰り返しです。しかし、全く知らない環境に置かれたとき、どの行動が最良の結果に繋がるのか、すぐには判断できません。限られた試行回数の中で、すでに知っている情報に基づいて行動を選択するべきか、あるいはまだ知らない可能性を探るべきか、これは強化学習における大きな課題です。
例えば、新しいお菓子屋さんを訪れたとしましょう。すでに評判の良い人気商品を買うか、それともまだ誰も食べたことのない新商品に挑戦するか、迷うところです。人気商品は美味しい可能性が高いですが、新商品はもっと美味しいかもしれません。強化学習もこれとよく似ています。すでに良い結果が得られている行動を選ぶのは安全ですが、もしかしたらもっと良い行動があるかもしれません。このジレンマを解決するために、様々な方策が考案されています。その中でも、UCB方策(Upper Confidence Bound方策)は、洗練された方法の一つです。UCB方策は、各行動の期待される報酬だけでなく、その不確かさも考慮します。具体的には、各行動に対して、これまでの試行で得られた報酬の平均値と、その行動がまだ十分に試されていないことによる不確かさを表す値を計算します。そして、これらの値の和が最大となる行動を選択します。
このように、UCB方策は、既知の情報と未知の可能性のバランスをうまく取りながら、最適な行動を探索します。いわば、好奇心を持って未知の領域を探求しつつ、経験に基づいて確実な行動も選択する、賢い学習方法と言えるでしょう。
知識と探求のバランス

私たちは何かを学ぶとき、既に知っていることを使って成果を出すことと、新しいことを試してより良い方法を探すことの間で、いつも迷います。例えば、いつもの通勤路を使うと、時間通りに会社に着けるという安心感がありますが、もしかしたらもっと早く着ける近道があるかもしれません。もし毎日違う道を通るなら、新しい発見があるかもしれませんが、多くの時間を無駄にする可能性もあります。
機械学習の一つである強化学習でも同じようなことが起こります。強化学習では、機械(エージェント)が様々な行動を試して、より多くの報酬を得る方法を学習します。この学習過程で、エージェントは既に知っている良い行動を繰り返し選択する「知識の活用」と、まだ試していない行動を選択する「探求」のバランスを取る必要があります。
知識の活用は、これまでの経験に基づいて、最も高い報酬が期待できる行動を選びます。例えば、ある喫茶店でいつも美味しいコーヒーを出してくれるなら、そこに行けば美味しいコーヒーを飲める可能性が高いでしょう。これは短期的に見ると良い選択です。しかし、もし他の喫茶店がもっと美味しいコーヒーを出していたとしても、いつもの喫茶店しか行かないのであれば、その発見を見逃してしまうことになります。
一方、探求は、まだ試していない行動を選択することで、より良い行動を発見する可能性を広げます。新しい喫茶店を試してみれば、思わぬ美味しいコーヒーに出会えるかもしれません。しかし、探求にはリスクも伴います。試した喫茶店のコーヒーが美味しくないかもしれませんし、最悪の場合、ひどい目に遭う可能性もあります。つまり、探求は長期的に見ると良い結果につながる可能性がありますが、短期的には損をする可能性もあるのです。
この知識の活用と探求のバランスをうまく調整する方法の一つにUCB方策というものがあります。UCB方策は、それぞれの行動に「期待値」と「不確実性」を割り当て、両方を考慮して次の行動を選択します。期待値が高いほど良い行動である可能性が高く、不確実性が高いほどまだ試行回数が少なく、真の価値が分かっていないことを意味します。UCB方策は、期待値と不確実性のバランスを取りながら、効果的に新たな良い行動を見つけ出そうとします。
このように、UCB方策は、強化学習において知識の活用と探求のバランスをうまくとるための、洗練された仕組みを提供しています。
| 項目 | 説明 | 例 | メリット | デメリット |
|---|---|---|---|---|
| 知識の活用 (Exploitation) | 過去の経験に基づき、最も高い報酬が期待できる行動を選択する | いつもの美味しい喫茶店に行く | 短期的には良い結果を得られる | より良い選択肢を見逃す可能性がある |
| 探求 (Exploration) | まだ試していない行動を選択し、より良い行動を発見する可能性を広げる | 新しい喫茶店を試してみる | 長期的には良い結果につながる可能性がある | 短期的には損をする可能性がある、リスクを伴う |
| UCB方策 | 期待値と不確実性のバランスを考慮して行動を選択する | 期待値と不確実性のバランスが良い喫茶店を選ぶ | 知識の活用と探求のバランスを効果的に調整できる | – |
UCB方策の仕組み

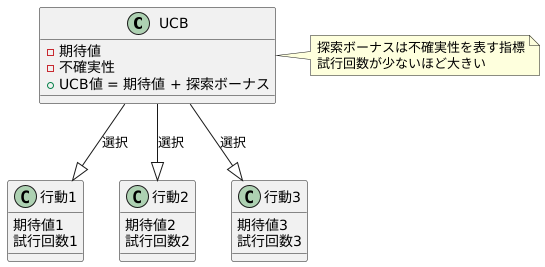
UCB方策は、様々な選択肢の中から最適な行動を選ぶための手法です。それぞれ違った行動を試すことで、どの行動が最も良い結果をもたらすかを学習していきます。この学習過程において、UCB方策は二つの重要な要素を考慮します。一つは「期待値」、もう一つは「不確実性」です。
期待値とは、ある行動をとった時に得られると予想される平均的な報酬のことです。過去の試行でその行動をとった結果に基づいて計算されます。例えば、ある自動販売機で何度も飲み物を買った場合、それぞれの飲み物の値段と美味しさから、どれが一番満足度が高いかを平均的に予想できます。これが期待値です。
しかし、試行回数が少ないと、その期待値が本当に正しいかどうかは確信できません。例えば、新しい飲み物を一度だけ試して美味しかったとしても、いつも同じように美味しいとは限りません。この確信の度合いを測るのが不確実性です。試した回数が少なければ少ないほど、不確実性は高くなります。
UCB方策は、この期待値と不確実性の両方を考慮して行動を選択します。期待値が高い行動は、良い結果が期待できるため選ばれやすいです。同時に、不確実性が高い行動も選ばれやすいです。なぜなら、まだ試行回数が少なく、真の価値が明らかになっていない可能性があるからです。もしかしたら、一見期待値が低く見えても、実は非常に良い行動であるかもしれません。
具体的には、UCB方策ではそれぞれの行動に「期待値」と「探索ボーナス」を足した値を計算し、その値が最も高い行動を選択します。この探索ボーナスは不確実性を表す指標であり、試行回数が少ないほど大きくなります。そのため、試行回数の少ない行動は、探索ボーナスによって価値が大きく補正され、選ばれやすくなります。このように、UCB方策は、過去の経験から期待値の高い行動を選ぶと同時に、未知の可能性を秘めた行動も積極的に探索することで、最適な行動を効率的に見つけ出します。
UCB方策の利点

UCB方策、つまり上限信頼区間方策には、いくつもの長所があります。中でも特筆すべきは、その理論的な裏付けの強さです。この方策は「後悔」という概念を基に設計されています。後悔とは、最良の選択をしなかったことでどれだけの損失を被ったかを表す指標です。例えば、いくつかの自動販売機の中から一つを選び、飲み物を買う場面を考えてみましょう。もし、最高の景品が当たる自動販売機を選ばなかったとしたら、その景品を得る機会を失ったことになります。これが後悔に当たります。UCB方策は、この後悔を最小限に抑えるように工夫されています。具体的には、UCB方策を用いると、この後悔の増加が対数的になることが理論的に保証されています。対数的な増加とは、時間の経過とともに後悔の増え方が緩やかになることを意味します。つまり、試行錯誤を繰り返すうちに、次第に最適な選択に近づき、無駄な選択をする機会が減っていくということです。
もう一つの利点は、UCB方策の実装が容易であることです。複雑な計算式や膨大なデータは必要ありません。限られた計算能力しかない機器でも、問題なく動作します。これは、実用面で大きなメリットと言えます。例えば、スマートフォンや組み込み機器のような計算資源が限られた環境でも、UCB方策を容易に適用できます。このように、UCB方策は理論的な根拠に基づき、効率的な学習を実現しながら、実装も容易であるという優れた特徴を兼ね備えています。そのため、様々な場面での意思決定に役立つ有効な手段と言えるでしょう。
| 長所 | 説明 |
|---|---|
| 理論的な裏付け | – 後悔(最良の選択をしなかったことによる損失)を最小限に抑えるように設計 – 後悔の増加が対数的になることが保証されており、時間の経過とともに最適な選択に近づく |
| 実装の容易さ | – 複雑な計算式や膨大なデータは不要 – 限られた計算能力しかない機器(スマートフォン、組み込み機器など)でも動作可能 |
適用事例

活用事例は多岐にわたります。
例えば、広告の表示を最適化するシステムでは、どの広告をユーザーに提示するかを決定する際に活用されています。膨大な広告の中から、クリックされる可能性が高い広告を選択することで、広告の効果を最大化することができます。従来の方法では、過去のデータに基づいてクリック率の高い広告ばかりが表示される傾向がありましたが、この手法を用いることで、まだ表示回数が少ないながらも潜在的にクリック率の高い広告を発掘できるようになります。その結果、全体のクリック率の向上が期待できます。
また、買い物をする人に商品を薦めるシステムにも活用できます。過去の購入履歴や閲覧履歴だけでなく、まだ推薦されたことのない商品も積極的に提示することで、ユーザーの新たな興味関心を発見し、購買意欲を高めることができます。これにより、商品の購入率向上だけでなく、ユーザーの満足度向上にも繋がります。
さらに、機械の制御やゲームをプレイする人工知能など、学習を繰り返しながら性能を向上させる技術が用いられる場面でも、この手法は有効な選択肢となります。未知の行動を試すことで、より良い結果が得られる可能性を秘めているからです。例えば、ロボットに新しい動作を学習させる際に、過去の経験に基づいて最適な行動を選択するだけでなく、未知の行動を試すことで、より効率的な動作を発見できる可能性があります。同様に、ゲームをプレイする人工知能では、過去の対戦データに基づいて最適な戦略を選択するだけでなく、新たな戦略を試すことで、より高い勝率を達成できる可能性があります。
このように、未知の可能性を探求し、より良い結果を求める様々な状況において、この手法は大きな力を発揮します。
| 活用事例 | 効果 | 従来の方法との違い |
|---|---|---|
| 広告の表示を最適化するシステム | クリック率の向上 | 過去のデータに基づいてクリック率の高い広告ばかりが表示される傾向があったが、潜在的にクリック率の高い広告を発掘できる。 |
| 買い物をする人に商品を薦めるシステム | 商品の購入率向上、ユーザーの満足度向上 | 過去の購入履歴や閲覧履歴だけでなく、まだ推薦されたことのない商品も積極的に提示することで、ユーザーの新たな興味関心を発見できる。 |
| 機械の制御やゲームをプレイする人工知能 | 性能の向上 | 過去の経験に基づいて最適な行動を選択するだけでなく、未知の行動を試すことで、より良い結果が得られる可能性がある。 |
まとめ

知識を活用するということと、未知のものを探求するということは、一見すると相反するように思えますが、上手に両立させることが、機械学習の分野では重要になります。そのための効果的な方法の一つとして、「ユー・シー・ビー方策」というものがあります。この方策は、これまで得られた知識を活かしつつ、まだよく分かっていない部分についても積極的に調べていくという、バランスの取れたやり方を採用しています。具体的には、「期待値」と「不確実性」という二つの指標を組み合わせて、次の行動を決めていきます。
まず「期待値」は、これまでの経験から、どの行動がどれだけの良い結果をもたらすかという予測値です。過去のデータに基づいて、それぞれの行動の良さを見積もります。次に「不確実性」は、まだ試行回数が少なく、行動の良し悪しについて確信が持てない度合いを表します。試した回数が少ない行動ほど、不確実性は高くなります。
ユー・シー・ビー方策では、この二つの指標を足し合わせた値が最も高い行動を選びます。つまり、期待値が高い行動は優先的に選ばれますが、同時に、不確実性が高い、まだよく分かっていない行動にもチャンスが与えられます。このように、過去の情報に基づいて期待値の高い行動を選ぶと同時に、不確実性の高い行動も試すことで、新たな発見の可能性を広げます。
この方策は、しっかりとした理論に基づいており、その効果が証明されています。さらに、実際にプログラムとして組み込むのも比較的簡単です。そのため、様々な分野で活用されており、限られた回数の中で、最も良い行動を見つけるための強力な方法となっています。例えば、広告の配信や商品の推薦など、様々な場面で応用され、効果を上げています。ユー・シー・ビー方策は、まさに限られた試行の中で、最適な行動を探し出すための、優れた道具と言えるでしょう。
| 項目 | 説明 |
|---|---|
| 知識活用と未知探求 | 一見相反するが、機械学習では両立が重要 |
| UCB方策 | 知識活用と未知探求のバランスを取る方法 |
| 期待値 | 過去の経験に基づいた行動の良さの予測値 |
| 不確実性 | 試行回数が少なく、行動の良し悪しが不確かな度合い |
| UCB方策の行動選択 | 期待値と不確実性を足し合わせた値が最も高い行動を選択 |
| UCB方策の効果 | 理論的根拠があり、実装も容易。限られた試行で最適な行動を発見 |
| 応用例 | 広告配信、商品推薦など |