学習データ:AIの成長を支える糧

AIを知りたい
先生、『学習データ』って、AIが賢くなるためのご飯みたいなものですか?

AIエンジニア
いいところに気がついたね!例えるなら、ご飯のようなものと言えるかもしれない。AIが賢くなるためには、たくさんの『学習データ』が必要なんだ。たとえば、猫をAIに認識させたいなら、猫の写真をたくさん見せる必要がある。この写真が『学習データ』にあたるんだよ。
AIを知りたい
なるほど。じゃあ、猫の写真をたくさん見せるほど、AIは猫を正確に認識できるようになるんですか?
AIエンジニア
基本的にはそうだよ。たくさんの猫の写真を見せることで、AIは猫の特徴をより深く学習できる。ただし、写真の種類が少ないと、特定の種類の猫だけを認識してしまう可能性もあるから、色々な種類の猫の写真を見せることが重要なんだ。
学習データとは。
人工知能に関係する言葉である「学習データ」について説明します。学習データとは、人工知能に与えられた仕事を何度も繰り返し行わせ、その予測の正確さを少しずつ上げていく過程で使うデータ全体のことを指します。
学習データとは

近年、人工知能という言葉が日常的に聞かれるようになりました。まるで魔法のように複雑な問題を解く人工知能ですが、その能力は学習によって得られるものです。この学習において、学習データはなくてはならない存在です。人間が子供に様々なことを教えるように、人工知能も学習データから知識や判断力を得ます。学習データとは、人工知能に特定の作業を学習させるために使うデータの集まりのことです。
例えば、画像認識の人工知能を育てる場合を考えてみましょう。猫の画像には「猫」という名前を、犬の画像には「犬」という名前を付けて人工知能に与えます。このように、たくさんの画像データとその正しい名前を一緒に人工知能に与えることで、人工知能は猫と犬の特徴を少しずつ理解し、画像を見てどちらかを判断する力を身につけます。他には、文章を理解し、翻訳や要約を行う人工知能の学習には、大量の文章データが必要です。翻訳であれば、日本語の文章とその正しい英語訳をセットにしたデータを用います。要約であれば、長い文章とその要約文をセットにしたデータを用いて学習させます。このように、人工知能の学習には、その目的に合わせた適切なデータが必要です。
また、学習データの質と量は、人工知能の性能に大きな影響を与えます。学習データに偏りがあったり、間違いが多かったりすると、人工知能は正しく学習することができません。人間が間違った知識を教えられたら、正しい判断ができなくなるのと同じです。質の高い学習データを十分な量用意することで、人工知能はより高い精度で作業をこなせるようになります。まさに学習データは、人工知能の成長を支える栄養源と言えるでしょう。
| 項目 | 説明 | 例 |
|---|---|---|
| 学習データ | 人工知能に特定の作業を学習させるために使うデータの集まり | – |
| 画像認識 | 画像から対象を識別するAI | 猫の画像と「猫」のラベル、犬の画像と「犬」のラベル |
| 文章理解・翻訳 | 文章を理解し翻訳を行うAI | 日本語の文章とその正しい英語訳 |
| 文章理解・要約 | 文章を理解し要約を行うAI | 長い文章とその要約文 |
| データの質と量 | AIの性能に大きな影響を与える | 質の高いデータ、十分な量のデータ |
学習データの重要性

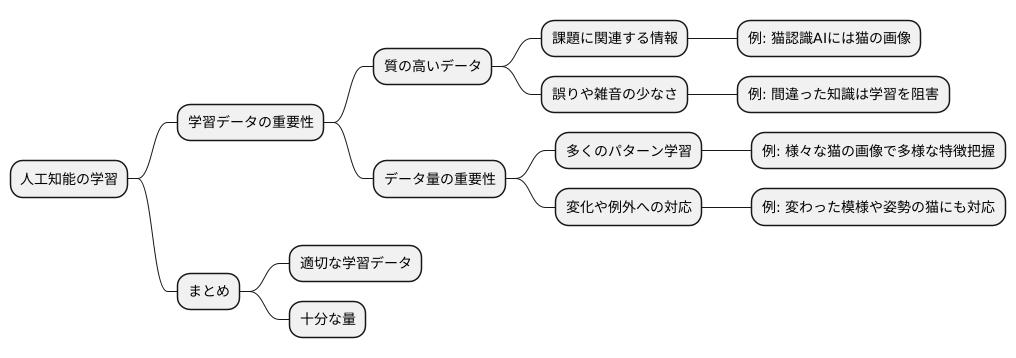
人工知能の働きは、学習に用いる情報の質と量に大きく左右されます。まるで人間の子供と同じように、良い教材を与えられれば賢く育ち、質の低い教材では期待するほどの成果を得られないのと同じです。人工知能にとっての教材こそ、学習データにあたります。
質の高い学習データとは、人工知能が学ぶべき課題に直接関わる情報が含まれているデータです。例えば、猫を見分ける人工知能を作るためには、猫の画像データが必要です。風景写真や抽象画をいくら与えても、猫の特徴を学ぶことはできません。まるで、算数を学ぶ子供に歴史の教科書を読ませるようなものです。情報の関連性が低いと、学習効果は期待できません。さらに、データに含まれる誤りや雑音も少ない方が良いでしょう。誤った情報や関係のない情報が多ければ、人工知能は混乱し、正しい判断ができなくなってしまいます。これは、子供に間違った知識を教え込むようなもので、成長を阻害する要因となります。
また、データの量は質と同様に重要です。一般的に、データの量が多いほど、人工知能はより多くのパターンを学ぶことができます。例えば、様々な種類の猫の画像を大量に学習させることで、人工知能は毛の色や模様、体型など、猫の多様な特徴を把握できるようになります。これは、多くの問題を解くことで、様々な解法パターンを学ぶ人間と同じです。データ量が多いほど、人工知能は多くの経験を積むことができ、認識の正確さや予測の精度が向上します。
大量のデータから学ぶことで、人工知能は様々な変化や例外にも対応できるようになります。例えば、少し変わった模様の猫や、変わった姿勢の猫にも対応できるようになるでしょう。これは、多くの経験を積んだ人間が、様々な状況に柔軟に対応できるようになるのと同じです。このように、人工知能を賢く育てるためには、適切な学習データを十分な量用意することが必要不可欠です。適切な情報を与え、多くの経験を積ませることで、人工知能はより高い能力を発揮できるようになります。
学習データの種類

人工知能を鍛えるための教材ともいえる学習データは、実に様々な種類があります。学習データは人工知能の学習目的によって、ふさわしいものを選ぶ必要があります。例えば、人の目で見て何が写っているか判断する人工知能を育てるには、写真や絵といった画像データを使います。人の声を聞いて内容を理解する人工知能には、音声データが必要です。文章の意味を読み取る人工知能には、文字で書かれた文章データを与えます。このように、人工知能の役割に合った形のデータを選ばなければなりません。
さらに、人工知能の学習方法によっても、必要なデータの種類や形が変わってきます。人工知能の学習方法には、大きく分けて三つの種類があります。一つ目は「教師あり学習」です。これは、問題と答えの組を人工知能に与えて学習させる方法です。例えば、犬の画像と「これは犬です」という答えをセットにして人工知能に与え、犬の特徴を学ばせます。二つ目は「教師なし学習」です。こちらは、答えを与えずに学習させる方法です。大量のデータの中から、人工知能が自ら規則性や特徴を見つけ出します。三つ目は「強化学習」です。これは、人工知能に色々な行動を試させて、うまくいった行動には報酬を、失敗した行動には罰を与えることで学習させる方法です。ゲームで高得点を取るための操作方法を学ぶときなどに用いられます。このように、それぞれの学習方法によって、必要なデータは異なってきます。教師あり学習では問題と答えの組、教師なし学習では大量のデータ、強化学習では行動の結果に対する報酬や罰といった情報が必要になります。
このように、人工知能を学習させるためには、目的と学習方法に合った適切な学習データを選び、準備することが何よりも大切です。
| 学習目的 | データの種類 |
|---|---|
| 画像認識 | 画像データ(写真、絵など) |
| 音声認識 | 音声データ |
| 自然言語処理 | テキストデータ |
| 学習方法 | 必要なデータ |
|---|---|
| 教師あり学習 | 問題と答えの組 |
| 教師なし学習 | 大量のデータ |
| 強化学習 | 行動の結果に対する報酬/罰 |
学習データの準備

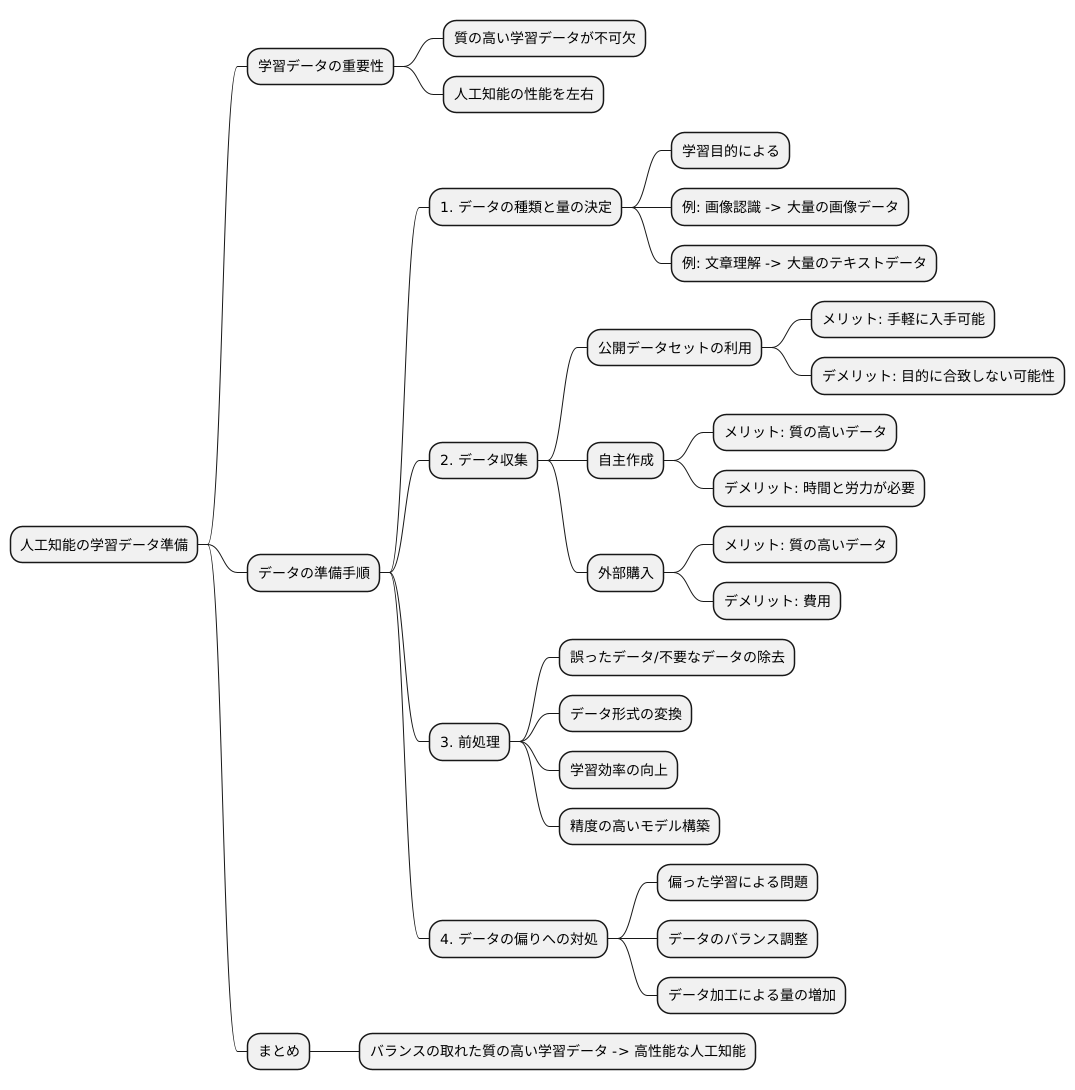
人工知能の学習には、質の高い学習データが不可欠です。学習データの準備は、いわば人工知能の教育の土台を作るようなもので、この土台の良し悪しが人工知能の性能を大きく左右します。まず、どのような種類のデータがどれくらい必要なのかを明確にする必要があります。人工知能に何を学習させたいのか、その目的によって必要なデータの種類と量は変わってきます。例えば、画像認識の人工知能を開発するのであれば、大量の画像データが必要になりますし、文章を理解する人工知能であれば、大量の文章データが必要になります。
次に、データを集める方法を検討します。すでに公開されているデータセットを利用する方法、自分たちでデータを作成する方法、外部からデータを購入する方法など、様々な方法があります。それぞれの方法にメリットとデメリットがあるので、状況に応じて適切な方法を選ぶ必要があります。公開されているデータセットは手軽に入手できますが、必ずしも目的に合致するとは限りません。自分たちでデータを作成する場合は、質の高いデータを作成するために多くの時間と労力をかける必要があります。外部からデータを購入する場合は、費用がかかりますが、質の高いデータを入手できる可能性があります。
データが集まったら、前処理という工程に移ります。これは、集めたデータを人工知能が学習しやすい形に整える作業です。具体的には、誤ったデータや不要なデータを取り除いたり、データの形式を変換したりします。この前処理を丁寧に行うことで、人工知能の学習効率が向上し、より精度の高いモデルを構築することができます。
さらに、データの偏りにも注意を払う必要があります。学習データに偏りがあると、人工知能は特定の事象に偏って学習してしまい、様々な状況に対応できない、融通の利かないものになってしまう可能性があります。例えば、特定の地域の人物の顔画像ばかりで学習させた顔認識人工知能は、他の地域の人物の顔を認識できない可能性があります。このような事態を防ぐためには、データのバランスを調整したり、データを加工して量を増やすなどの工夫が必要です。バランスの取れた質の高い学習データを用意することで、初めて高性能な人工知能を開発することが可能になります。
学習データと倫理

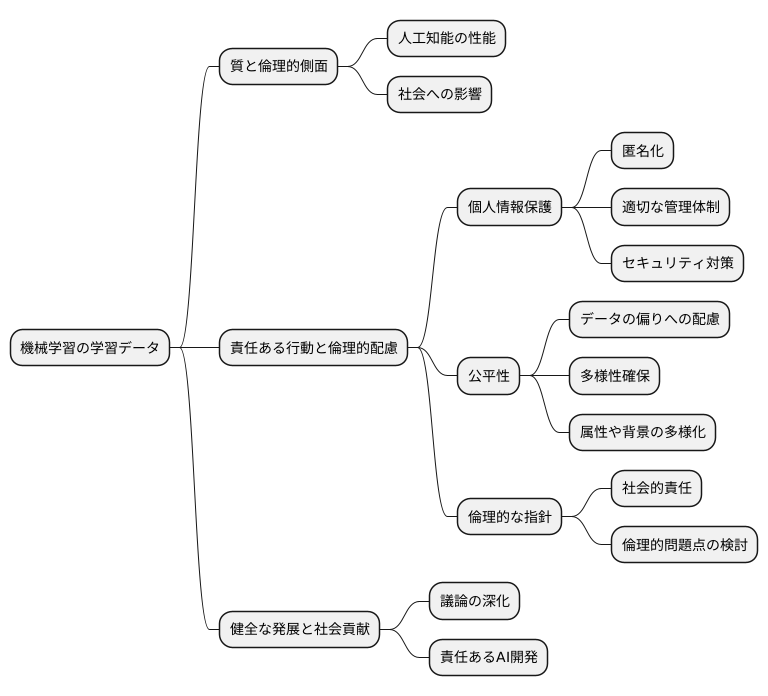
機械学習の基盤となる学習データは、その質と倫理的側面が人工知能の性能と社会への影響を大きく左右します。学習データの利用には、責任ある行動と倫理的な配慮が欠かせません。
まず、学習データとして扱う情報には、個人情報が含まれる場合が多くあります。個人のプライバシーは尊重されなければならず、個人情報保護の観点から、データの匿名化や適切な管理体制の構築は必須です。データの不正利用や漏洩は、深刻な社会問題を引き起こす可能性があるため、厳格なセキュリティ対策が必要です。
さらに、学習データに偏りがあると、人工知能が不公平な判断や差別的な行動をする可能性があります。例えば、特定の属性のデータが多く含まれている場合、人工知能はその属性に有利な結果を導き出す傾向を持つ可能性があります。これは社会的な不平等を助長する結果になりかねません。学習データの多様性を確保し、様々な属性や背景を持つデータを取り入れることで、人工知能の公平性と客観性を高めることができます。
人工知能の開発は社会全体に大きな影響を与えるため、倫理的な観点を常に意識することが重要です。人工知能が人々の生活を豊かにし、社会の発展に貢献するためには、倫理的な指針に基づいた開発と運用が必要です。開発者は、常に倫理的な問題点について検討し、社会的な責任を自覚した上で、人工知能技術の開発に取り組む必要があります。
学習データは人工知能の可能性を広げるための重要な資源ですが、その利用には慎重さと責任が求められます。人工知能技術が今後ますます発展していく中で、倫理的な側面を考慮した学習データの活用は、人工知能の健全な発展と社会への貢献に不可欠です。倫理的な問題を軽視せず、社会全体で議論を深め、責任ある人工知能開発を進めていく必要があります。