生成AIの学習データ:質と量

AIを知りたい
先生、「生成AIの学習データ」って、具体的にどんなものなのですか? たくさんのデータが必要なのはわかるのですが、種類がよくわからないです。

AIエンジニア
そうですね。たとえば、文章を作るAIなら、たくさんの文章を学習データとして与えます。絵を描くAIなら、たくさんの絵ですね。ほかには、音声データやプログラムのコードなども学習データとして使われます。AIが何を作り出すかによって、必要なデータの種類も変わってくるわけです。
AIを知りたい
なるほど。AIによって学習データの種類が違うんですね。でも、ただたくさんのデータを集めればいいわけではないんですよね?
AIエンジニア
その通りです。偏ったデータで学習すると、AIも偏った答えを出すようになります。例えば、ある国の料理のレシピだけを学習させると、世界の料理について聞かれても、その国の料理しか答えられないAIになってしまうかもしれません。だから、色々な種類のデータをバランスよく与えることが大切です。
生成AIの学習データとは。
人工知能に関する言葉である「生成人工知能の学習データ」について説明します。生成人工知能は、通常、たくさんの学習データから規則性や仕組みを学び、新しいデータを作ることが目的です。この学習データは、生成人工知能が取り組む仕事や分野に関係のある、様々な種類のデータでなければなりません。色々な例を学ぶことで、様々な入力に対して適切な答えを返すことができるようになるからです。また、学習データを作る際には、偏りがないように注意しなければなりません。特定の集団や特徴に偏ったデータが含まれていると、人工知能もその影響を受けてしまうため、偏りの影響をできるだけ少なくし、公平性を保ったデータを使う必要があります。
学習データとは

生成人工知能は、人間が何かを学ぶ姿とよく似ていて、与えられた情報から知識や規則性を学び取ります。この学習に使われる情報こそが学習情報です。人が教科書を読んだり、経験を積んだりして学ぶように、生成人工知能も学習情報を通して世の中の様々な出来事や物事の関係性を理解していきます。
例えば、絵を描く人工知能の場合を考えてみましょう。膨大な数の絵の情報から、猫がどのように見え、どのような特徴を持っているのかを学びます。もし、学習情報に猫の絵が全く含まれていなかったら、猫を描くことはできません。また、猫の絵が少ししか含まれていなかったら、猫の特徴を十分に捉えられず、上手に描くことが難しいでしょう。学習情報に含まれる猫の絵が多ければ多いほど、人工知能は猫の特徴をより深く理解し、様々な種類の猫の絵を描くことができるようになります。
文章を作る人工知能であれば、大量の文章情報から、言葉のつながりや文法、言葉が持つ意味などを学習します。例えば、「おはようございます」や「こんにちは」といったあいさつは、どんな時に使われるのか、どのような言葉と組み合わせて使われるのかを学習情報から学びます。学習情報に多くのあいさつの例が含まれていれば、人工知能は自然で適切なあいさつを生成することができます。
このように、学習情報は生成人工知能にとって、いわば教科書のようなものです。学習情報が豊富で質が高いほど、生成人工知能は多くのことを学び、より高度な能力を発揮することができます。生成人工知能がその能力を十分に発揮するための土台となる、非常に大切な要素なのです。
| 種類 | 学習情報 | 学習内容 | 結果 |
|---|---|---|---|
| 絵を描くAI | 猫の絵 | 猫の特徴 | 猫の絵を描く |
| 絵を描くAI | 猫の絵が少ない | 猫の特徴を十分に捉えられない | 猫の絵を上手に描けない |
| 絵を描くAI | 猫の絵が多い | 猫の特徴を深く理解 | 様々な種類の猫の絵を描く |
| 文章を作るAI | 大量の文章情報 | 言葉のつながり、文法、言葉の意味(例:挨拶) | 自然で適切な文章を作る |
データの量と質

人工知能の学習には、質の高いデータが欠かせません。データの量は多いほど良いと思われがちですが、質が伴わなければ、期待する成果を得ることは難しいでしょう。ちょうど、料理と同じように考えてみてください。多くの食材があれば様々な料理を作れますが、食材が腐っていたり、材料が偏っていたりすると、美味しい料理は作れません。人工知能も同じで、大量のデータを使うだけでは、正しい知識や情報を学習できるとは限らないのです。
例えば、猫の絵を人工知能に学習させたいとします。大量の猫の絵を集めたとしても、その中に犬の絵が混ざっていたり、猫の絵に「犬」という間違った名前が付けられていたとしたらどうなるでしょうか。人工知能は猫と犬の違いを正しく理解することができず、猫の絵を描かせても犬のような絵を描いてしまうかもしれません。また、特定の種類の猫の絵ばかりを集めて学習させた場合、他の種類の猫を描くことが苦手になる可能性もあります。まるで、限られた食材でしか料理を習っていない料理人が、初めて見る食材で料理を作るのに苦労するようなものです。
人工知能が様々な種類の猫を正しく描けるようにするためには、様々な種類の猫の絵をバランスよく集めることが重要です。これは、様々な食材を使って多様な料理を作れる料理人を育てるのと同じです。さらに、データの正確さも大切です。猫の絵には「猫」という正しい名前を付け、犬の絵が混ざっていないかを注意深く確認する必要があります。これは、料理に使う食材が新鮮で、異物が混入していないかを確認するのと同じくらい重要なことです。
このように、人工知能の学習には、データの量だけでなく、正確さ、網羅性、多様性といった質の面にも注意を払うことが不可欠です。データの量と質の両方が揃って初めて、人工知能は真価を発揮できるのです。
| 項目 | 説明 | 料理の例え |
|---|---|---|
| データの量 | 多いほど良いと思われがちだが、質が伴わなければ意味がない | 多くの食材があれば様々な料理を作れる |
| データの質 | 人工知能学習において重要な要素 | 食材の鮮度や異物の混入がないか |
| 正確さ | 猫の絵には「猫」という正しい名前を付ける | 食材が腐っていないか |
| 網羅性 | 様々な種類の猫の絵をバランスよく集める | 様々な食材を使う |
| 多様性 | 特定の種類の猫の絵ばかりを集めない | 多様な料理を作れる |
多様なデータが必要な理由

近年の技術革新により、文章や画像、音楽など様々なものを作り出すことができる生成人工知能が注目を集めています。この生成人工知能が様々な状況に対応し、真に役立つものとなるためには、多様なデータによる学習が不可欠です。
例えば、猫の画像を生成する人工知能を考えてみましょう。もし学習データが特定の品種の正面からの写真ばかりだとしたらどうなるでしょうか。生成される画像はどれも似たような猫ばかりになり、少し変わった角度から見た猫や、他の種類の猫を生成することはできません。毛並み、模様、瞳の色、耳の形など、猫の特徴は多岐にわたります。これらの特徴を捉え、あらゆる猫をリアルに生成するためには、様々な品種の猫の画像、様々な角度から撮影された画像、様々な背景で撮影された画像など、多様なデータが必要となります。
文章生成人工知能の場合も同様です。例えば、小説を書かせたい場合、学習データがニュース記事ばかりだと、生成される文章は事実の羅列のような、硬く機械的なものになりがちです。詩的な表現や物語の展開、登場人物の心情描写などを自然に表現するためには、小説、詩、エッセイ、脚本など、様々なジャンルの文章、様々な文体、様々なトピックの文章を学習させる必要があります。
このように、生成人工知能が持つ可能性を最大限に引き出し、柔軟性と汎用性を高めるためには、多様なデータによる学習が鍵となります。データが多様であるほど、生成人工知能はより多くの状況に対応できるようになり、より高度で複雑な処理を行うことができるようになります。そして、私たちの生活をより豊かに、より便利にしてくれる真に役立つ存在へと進化していくでしょう。
| 種類 | 例 | データの多様性の必要性 | 結果 |
|---|---|---|---|
| 画像生成AI | 猫の画像生成 | 品種、角度、背景など多様な画像データが必要 | 多様な猫の画像を生成可能 |
| 文章生成AI | 小説執筆 | 小説、詩、エッセイなど多様なジャンル、文体、トピックの文章データが必要 | 自然で多様な表現、物語展開、心情描写が可能 |
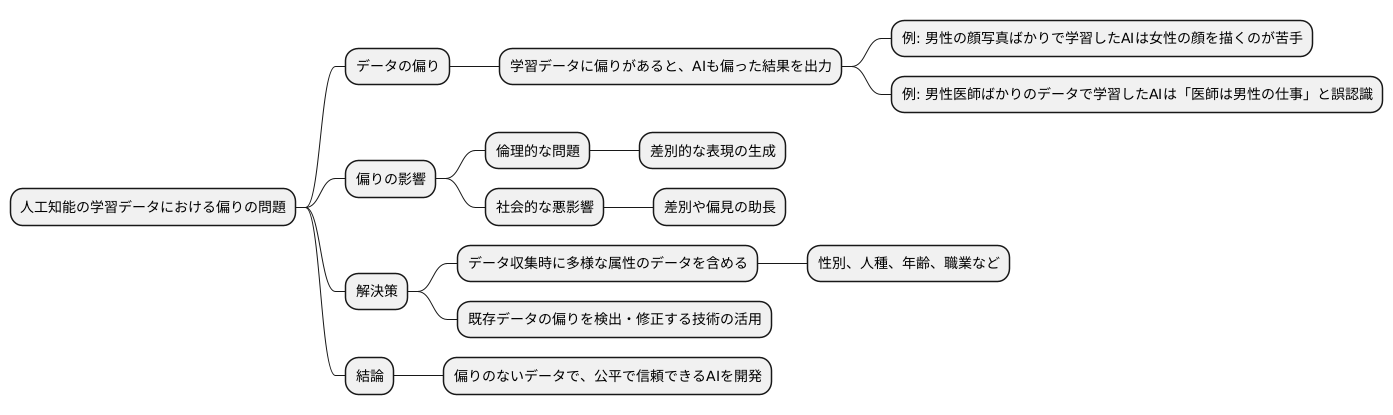
偏りのないデータの重要性

人工知能の学習には、大量のデータが必要です。しかし、そのデータに偏りがあると、人工知能はその偏りを学習し、偏った結果を出力してしまいます。これは、まるで偏った考えを持つ先生から学ぶ生徒が、同じように偏った考えを持つようになるのと似ています。
例えば、ある人工知能に絵を描かせる場合を考えてみましょう。もし、学習データとして男性の顔写真ばかり与えられたら、どうなるでしょうか。おそらく、その人工知能は女性の顔を描くのが苦手になり、男性の顔ばかり描くようになるでしょう。これは、データの偏りが人工知能の出力に直接影響を与えている例です。
同じように、文章を作成する人工知能を開発する場合にも、データの偏りは大きな問題となります。特定の性別や人種、年齢層に関する偏ったデータで学習させた場合、人工知能は差別的な表現を生成する可能性があります。例えば、医師の仕事について説明する文章を生成する際に、学習データに男性医師の例ばかりが含まれていた場合、人工知能は「医師は男性の仕事である」という誤った認識に基づいた文章を生成するかもしれません。
このような偏りは、倫理的に問題があるだけでなく、社会的な悪影響を与える可能性もあります。偏った情報が拡散されることで、差別や偏見が助長される恐れがあるからです。そのため、人工知能の学習データは、偏りを最小限に抑え、公平性を確保することが非常に重要です。
では、どのようにしてデータの偏りをなくせば良いのでしょうか。まず、データ収集の際には、多様な属性を持つデータを含めるように注意する必要があります。性別、人種、年齢、職業など、様々な属性をバランス良く含めることで、偏りのないデータセットを作成することができます。また、既に収集したデータに偏りが含まれている場合は、その偏りを検出し修正する技術を活用することも重要です。人工知能の開発には、技術的な側面だけでなく、倫理的な側面も考慮することが不可欠です。偏りのないデータを用いることで、より公平で信頼できる人工知能を開発することができるのです。
データ作成の難しさ

質の高い学習データを作ることは、大変な手間と時間のかかる作業です。生成AIを育てるためのデータは、人間の子供を育てるための食事のようなものです。栄養バランスの取れた食事を用意するように、質の高いデータを集め、整え、適切なラベルを付ける必要があります。この作業は、想像以上に多くの時間と労力を必要とします。
まず、大量のデータを集める必要があります。インターネット上には大量の情報がありますが、そのすべてが使えるわけではありません。目的とするAIの学習に適したデータを選び抜く作業は、干し草の中から針を探すようなものです。必要なデータの種類や量によっては、数週間から数ヶ月、場合によっては数年かかることもあります。
次に、集めたデータをきれいに整える必要があります。集めたデータには、誤りや不整合、欠けている部分などが含まれていることがよくあります。これらのノイズを取り除き、使える状態にするには、地道な作業が必要です。データの量が多ければ多いほど、この作業にかかる時間も長くなります。まるで、収穫した野菜を丁寧に洗って泥や虫を取り除くような作業です。
さらに、データに適切なラベルを付けることも重要です。AIはラベルを通してデータの意味を理解します。例えば、画像に「猫」というラベルを付けることで、AIは猫の特徴を学習できます。この作業は、データの内容を正しく理解し、適切なラベルを付ける必要があるため、専門的な知識が必要な場合もあります。まるで、子供に絵本の内容を丁寧に説明するような作業です。
最後に、データの質を評価し、偏りを修正する作業も必要です。データに偏りがあると、AIも偏った結果を出力してしまう可能性があります。例えば、特定の地域の情報ばかりで学習したAIは、他の地域の情報には対応できないかもしれません。データの偏りを修正するには、統計的な手法を用いてデータのバランスを整える必要があります。これは、料理の味付けを調整するような繊細な作業です。
このように、質の高い学習データを作成するには、多くの時間と労力、そして専門的な知識が必要です。このデータ作成の難しさが、現在、生成AI開発における大きな課題の一つとなっています。
| 工程 | 説明 | 例え |
|---|---|---|
| データ収集 | 大量のデータを集める。AI学習に適したデータを選び抜く必要がある。 | 干し草の中から針を探す |
| データの整理 | 集めたデータの誤りや不整合、欠損を取り除く。 | 収穫した野菜を洗って泥や虫を取り除く |
| ラベル付け | AIがデータを理解するためのラベルを付ける。専門知識が必要な場合もある。 | 子供に絵本の内容を説明する |
| データの質の評価と偏りの修正 | データの偏りを修正し、バランスを整える。 | 料理の味付けを調整する |
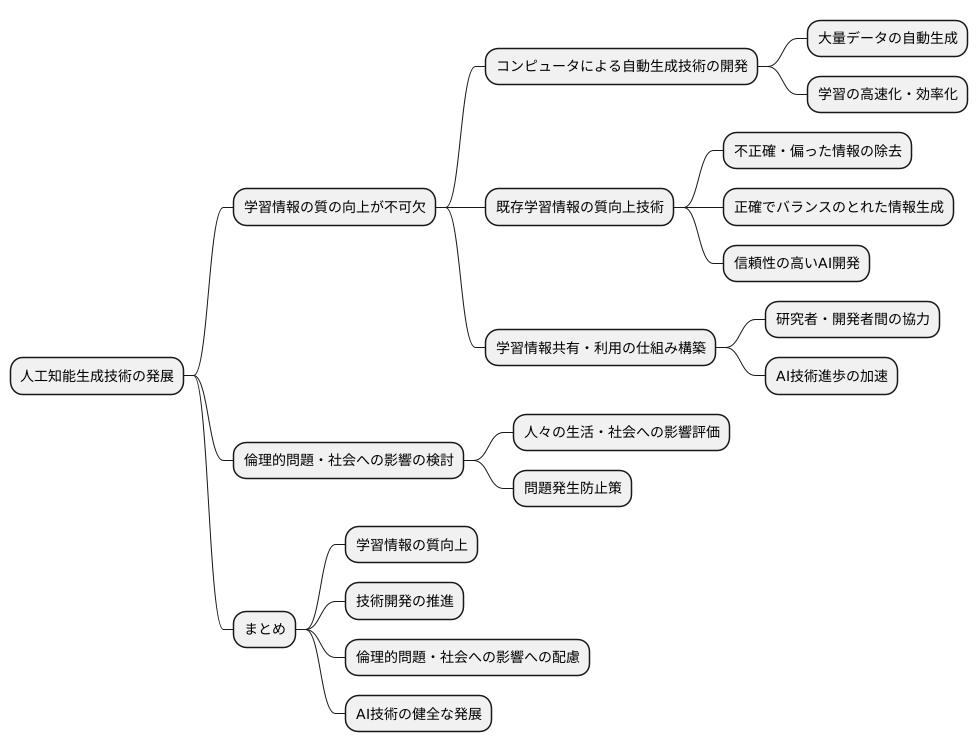
今後の展望

人工知能による文章や画像などの生成技術は、近年目覚ましい発展を遂げてきました。この技術をさらに発展させるためには、人工知能に学習させるための情報の質を高めることが欠かせません。今後は、質の高い学習情報をより効率的に作り出すための技術開発が進むと期待されます。
まず、コンピュータが自動的に学習情報を作り出す技術の開発が重要です。人が手を加えることなく、大量の学習情報が自動的に生成できるようになれば、人工知能の学習をより速く、より効率的に進めることができます。また、すでにある学習情報の質を高める技術も重要です。不正確な情報や偏った情報を取り除き、正確でバランスの取れた学習情報を作ることで、より信頼性の高い人工知能を開発することができます。
さらに、質の高い学習情報を研究者や開発者が共有し、利用できる仕組みを作ることも重要です。多くの研究者や開発者が協力し、情報を共有することで、人工知能技術の進歩を加速させることができます。優れた学習情報は、人工知能開発の基盤となる大切な資源と言えるでしょう。
しかし、技術開発を進める一方で、倫理的な問題や社会への影響についても注意深く検討していく必要があります。人工知能が作り出した情報が、人々の生活や社会にどのような影響を与えるのかを慎重に見極め、問題が生じないように対策を講じなければなりません。
人工知能の技術は、様々な分野で私たちの生活を豊かにする可能性を秘めています。学習情報の質を高め、技術開発を進めるとともに、倫理的な問題や社会への影響にも配慮することで、人工知能技術の健全な発展を目指していく必要があるでしょう。