
強化学習におけるQ値の重要性

AIを知りたい
先生、「Q値」ってなんですか?難しそうでよくわからないです。

AIエンジニア
そうだね、少し難しいかもしれないね。簡単に言うと、AIがある行動をとった時の「良さ」を数値で表したものだよ。ゲームで例えると、高い得点を得られる行動はQ値が高くなるんだ。
AIを知りたい
なるほど!ゲームの得点みたいなものなんですね。じゃあ、Q値が高いほど良い行動ってことですか?
AIエンジニア
その通り!AIは、このQ値を最大にするように学習していくことで、最適な行動を学んでいくんだよ。だから、Q値を最適化できれば、AIは適切な行動ができるようになるんだね。
Q値とは。
人工知能の分野でよく使われる「Q値」という言葉について説明します。Q値は、強化学習という学習方法で大切な役割を持つ「行動価値関数」の値を表すものです。この関数の名前の頭文字をとってQ値と呼んでいます。このQ値を最も良い状態にできれば、適切な行動ができたと言えるのです。
行動価値関数とQ値の関係

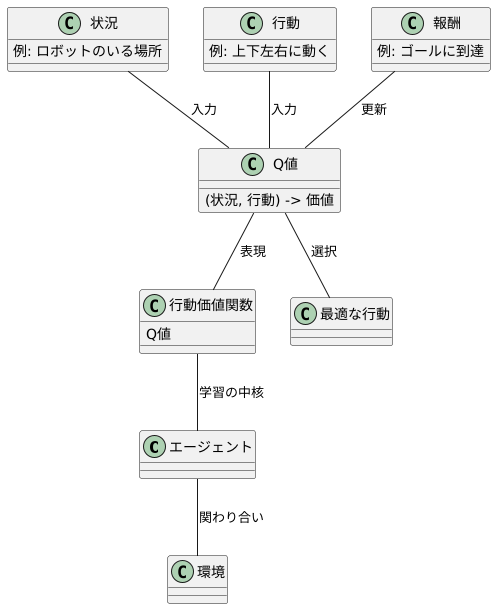
試行錯誤を通して学ぶ枠組み、それが強化学習です。学習を行う主体であるエージェントは、周囲の環境と関わり合いながら、最も良い行動を見つけることを目指します。この学習の中核を担うのが、行動価値関数です。これは、ある状況下で特定の行動をとった時に、将来にわたってどれだけの報酬が期待できるかを示すものです。
この行動価値関数の値を、Q値と呼びます。「Quality」の頭文字からきています。Q値は、状況と行動の組み合わせを入力とし、その組み合わせの価値を出力します。Q値が高いほど、その状況でその行動をとることが良いと判断されるわけです。強化学習の目的は、このQ値を最大にする行動を見つけることにあります。
例えば、迷路を解くロボットを想像してみましょう。ロボットのいる場所が「状況」であり、上下左右に動くことが「行動」です。ゴールに辿り着けば報酬が得られます。ロボットは、最初はどの行動が良いか分かりません。しかし、何度も迷路に挑戦する中で、各場所での各行動のQ値を学習していきます。ある場所で右に動くとゴールに近づき報酬が得られる場合、その場所と「右」という行動の組み合わせのQ値は高くなります。反対に、行き止まりに突き当たる行動のQ値は低くなります。
このように、エージェントは様々な行動を試み、その結果得られる報酬からQ値を更新していきます。そして、より高いQ値を持つ行動を選択するようになることで、最適な行動を学習していくのです。Q値は、エージェントが最適な行動を学ぶための重要な指標と言えるでしょう。
Q値の最適化と行動選択

「行動の価値」を示す指標であるQ値を、最大化することを目指すのがQ値の最適化です。この最適化を達成することで、様々な状況において、どの行動をとれば最も高い報酬を得られるかを学習することができます。
Q値は、特定の状態において特定の行動をとった場合の将来的な報酬の予測値です。例えば、将棋を考えると、盤面の状態が「状態」であり、駒の動かし方が「行動」に当たります。そして、勝利という最終的な目標に向かうために、どの行動が最も良いかを判断するためにQ値を用います。
最適なQ値が分かれば、それぞれの状況で最も高いQ値を持つ行動を選択することで、最も良い戦略を立てることができます。迷路を解く場面を想像してみてください。迷路のそれぞれの場所は「状態」であり、上下左右への移動が「行動」です。それぞれの場所で、どの行動をとれば最も早くゴールに辿り着けるかをQ値が示します。最適なQ値は、ゴールまでの最短経路を示す地図のような役割を果たします。
エージェント(学習を行う主体)は、試行錯誤を通じてQ値を学習していきます。最初はランダムに行動を選択し、その結果得られた報酬をもとにQ値を更新します。成功体験や失敗体験を繰り返すことで、どの行動がより良い結果に繋がるかを学習し、Q値を徐々に最適な値に近づけていきます。
このように、Q値を最適化することで、エージェントは迷路を効率的に解いたり、将棋で最良の手を打ったりするなど、様々な課題を解決するための最適な行動戦略を身につけることができます。そしてQ値の最適化は、強化学習と呼ばれる機械学習の一分野において、中心的な役割を担っています。
| 概念 | 説明 | 例(将棋) | 例(迷路) |
|---|---|---|---|
| Q値 | 特定の状態において特定の行動をとった場合の将来的な報酬の予測値 | 盤面の状態と駒の動かし方の組み合わせに対する、勝利への期待値 | 迷路の特定の位置で、上下左右のどの移動方向がゴールへ繋がりやすいかの予測値 |
| 状態 | エージェントが置かれている状況 | 盤面の配置 | 迷路内の現在位置 |
| 行動 | エージェントがとれる行動 | 駒の動かし方 | 上下左右への移動 |
| 報酬 | 行動の結果得られる価値 | 勝利 | ゴール到達 |
| Q値の最適化 | 様々な状況で、どの行動が最も高い報酬を得られるかを学習するプロセス | どの駒の動かし方が勝利に繋がりやすいかを学習する | どの移動方向がゴールへ繋がりやすいかを学習する |
| 最適なQ値 | 各状態において、最も高い報酬に繋がる行動を示すQ値 | 最良の手を打つための指針 | ゴールまでの最短経路を示す地図 |
| 学習方法 | 試行錯誤を通じて、行動の結果得られた報酬をもとにQ値を更新 | 対局を繰り返し、勝敗の結果からQ値を調整 | 迷路を何度も試行し、ゴール到達までの時間や経路からQ値を調整 |
Q学習アルゴリズム

「Q学習」とは、人工知能の分野で、試行錯誤を通じて最適な行動を学習するための手法です。 具体的には、ある状況における行動の価値を数値化した「Q値」を学習していくことで、どの行動が最も良い結果をもたらすかを判断できるようにします。この学習方法は、過去の経験を活かしながら、将来の報酬を最大化するようにQ値を調整していくというものです。
Q学習は、「時間差分学習」という枠組みに基づいています。 時間差分学習とは、過去の経験から将来の予測を修正していく学習方法です。 例えば、ある行動をとった結果、思ったよりも良い報酬が得られた場合、その行動のQ値は増加します。逆に、悪い結果になった場合はQ値は減少します。
では、具体的にQ値はどのように更新されるのでしょうか? エージェント(学習を行う主体)がある行動を実行すると、環境から報酬と次の状態が返ってきます。この報酬と次の状態の情報をもとに、Q値を更新します。 更新の際には、現在の行動で得られた報酬だけでなく、次の状態で得られるであろう最大のQ値も考慮に入れます。つまり、将来にわたって得られるであろう報酬の合計を最大化するようにQ値を調整するのです。
Q学習の大きな利点は、「モデルフリー」であるという点です。 モデルフリーとは、環境の仕組み(状態遷移確率や報酬関数など)を事前に知らなくても学習できるということです。そのため、複雑な環境や、仕組みがわからない環境でも適用することができます。 試行錯誤を通じて最適な行動を見つけ出すQ学習は、ロボット制御やゲームAIなど、様々な分野で活用されています。 過去の経験を活かし、将来の報酬を最大化するというQ学習の仕組みは、人間の学習過程にも似ていると言えるでしょう。
深層学習との融合

近年の機械学習分野において、深層学習と強化学習を組み合わせた深層強化学習が大きな注目を集めています。従来の強化学習では、状態と行動の組み合わせに対する価値(行動価値関数、Q関数と呼ばれる)を記録する表を用いていましたが、状態の種類が膨大になる複雑な問題では、この表の作成と管理が困難でした。そこで、深層学習の表現力を活かしてQ関数を近似的に表現する手法が考案され、深層強化学習と呼ばれるようになりました。その代表的な手法の一つが深層Q学習(DQN)です。
DQNは、Q関数を深層ニューラルネットワークで表現することで、複雑な状態空間を持つ問題にも対応できるようになりました。従来の強化学習では、状態の数が多くなるとQ関数の表が巨大になり、学習が困難でした。しかし、DQNではニューラルネットワークを用いることで、高次元な状態空間を効率的に表現し、学習することができます。これは、従来手法では不可能だった複雑な問題を解く可能性を広げる画期的な進歩でした。
例えば、テレビゲームの操作や機械の制御などは、状態空間が非常に複雑な問題の代表例です。ゲーム画面のピクセル情報や、機械の各部品の位置や速度など、考慮すべき要素が膨大に存在します。DQNは、このような高次元な状態空間を扱うタスクにおいても優れた性能を発揮することが示されています。具体的には、過去のゲーム画面の情報から次の行動を決定したり、機械のセンサー情報から最適な制御指令を生成したりすることで、人間のような高度な判断を実現しています。
このように、深層強化学習、特にDQNの登場は、強化学習の可能性を大きく広げました。複雑な状態空間を持つ問題にも適用可能になったことで、様々な分野への応用が期待されています。深層学習と強化学習の融合は、今後の機械学習研究における重要な方向性の一つと言えるでしょう。
| 項目 | 説明 |
|---|---|
| 深層強化学習 | 深層学習と強化学習を組み合わせた手法。状態と行動の組み合わせに対する価値(Q関数)を深層学習で近似的に表現。 |
| 従来の強化学習の課題 | 状態の種類が膨大になる複雑な問題では、Q関数を記録する表の作成と管理が困難。 |
| 深層Q学習(DQN) | 深層強化学習の代表的な手法。Q関数を深層ニューラルネットワークで表現。 |
| DQNの利点 | 高次元な状態空間を効率的に表現し、学習可能。複雑な問題を解く可能性を広げる。 |
| DQNの適用例 | テレビゲームの操作、機械の制御など、高次元な状態空間を持つタスク。 |
| DQNの成果 | 過去のゲーム画面情報や機械のセンサー情報から、人間のような高度な判断を実現。 |
| 今後の展望 | 深層学習と強化学習の融合は、今後の機械学習研究における重要な方向性。 |
Q値の応用

Q値とは、ある状態である行動をとったときの価値を数値化したものです。この値が大きいほど、その状態と行動の組み合わせが良いことを意味します。Q値は、強化学習と呼ばれる機械学習の一種で中心的な役割を担っています。強化学習とは、試行錯誤を通じて学習する手法で、エージェントと呼ばれる学習主体が環境と相互作用しながら最適な行動を学習します。Q値は、この学習過程において、エージェントがどの行動を選択すべきかを判断するための指標となります。
Q値の学習には、様々な手法がありますが、代表的なものとしてQ学習があります。Q学習では、エージェントは環境の中で行動をとり、その結果として報酬を受け取ります。そして、受け取った報酬をもとにQ値を更新していきます。具体的には、現在の状態と行動の組み合わせに対するQ値を、次の状態における最大のQ値と受け取った報酬を使って更新します。この更新を繰り返すことで、エージェントは最適な行動を学習していきます。
Q値とその学習手法は、様々な分野で応用されています。例えば、囲碁や将棋のような複雑な戦略ゲームでは、Q学習を用いたAIが人間を超える性能を達成しています。これらのゲームでは、盤面の状態が膨大であるため、従来の手法では最適な手を探索することが困難でした。しかし、Q学習を用いることで、効率的に最適な手を学習することが可能になりました。また、ロボット制御の分野でもQ値は活用されています。ロボットは、環境と相互作用しながら、様々なタスクを学習する必要があります。Q値を用いることで、ロボットは試行錯誤を通じて効率的にタスクを学習することができます。例えば、ロボットアームの制御や、移動ロボットのナビゲーションなどにQ値が応用されています。さらに、医療分野においても、Q値を用いた研究が進められています。最適な治療方針を決定するシステムの開発などにQ値が活用されることが期待されています。このように、Q値は様々な分野で重要な役割を果たしており、今後ますます応用範囲が広がっていくと考えられます。
| 項目 | 説明 |
|---|---|
| Q値 | ある状態である行動をとったときの価値を数値化したもの。値が大きいほど、その状態と行動の組み合わせが良い。 |
| 強化学習 | 試行錯誤を通じて学習する機械学習の一種。エージェントが環境と相互作用しながら最適な行動を学習する。Q値は、エージェントがどの行動を選択すべきかを判断するための指標となる。 |
| Q学習 | Q値の学習手法の一つ。エージェントは環境の中で行動をとり、報酬を受け取り、それを元にQ値を更新する。 |
| Q値の応用 |
|
Q値の将来展望

Q値は、将来ますます注目を集めるであろう、人工知能の重要な技術です。 今後も活発な研究開発が見込まれ、これまで以上に様々な分野での活用が期待されています。
現在、Q値を用いた強化学習は、囲碁や将棋といったゲーム分野で目覚ましい成果を上げています。しかし、その応用範囲はゲームにとどまりません。今後は、自動運転やロボット制御、医療診断、金融取引など、より複雑で高度な判断が求められる分野での活用が期待されています。
例えば、自動運転では、Q値を用いることで、様々な状況に応じて最適な運転操作を学習することができます。周囲の車両や歩行者の動き、道路状況、信号などを考慮しながら、安全で効率的な運転を実現することが可能になります。
また、ロボット制御の分野でも、Q値は重要な役割を果たすと考えられます。複雑な動作を学習させることで、工場での組立作業や、災害現場での救助活動など、人間にとって危険な作業をロボットが行うことが可能になります。
医療診断においては、患者の症状や検査データに基づいて、最適な治療方針を決定するためにQ値が活用できると考えられます。膨大な医療データから学習することで、経験豊富な医師にも匹敵する正確な診断が可能になるかもしれません。
さらに、金融取引においては、市場の動向を予測し、最適な投資判断を行うためにQ値が役立つ可能性があります。過去の市場データや経済指標などを分析することで、リスクを最小限に抑えながら、高い収益を上げる投資戦略を立てることが期待されます。
このように、Q値を用いた強化学習は、様々な分野で大きな可能性を秘めています。今後の研究開発によって、より高度な意思決定や複雑な問題解決が可能となり、社会に大きな変革をもたらすことが期待されます。 ただし、実社会への応用には、安全性や信頼性の確保といった課題も残されています。今後、これらの課題を解決するための研究も重要になるでしょう。
| 分野 | Q値の活用例 | 期待される効果 |
|---|---|---|
| ゲーム | 囲碁、将棋など | 高度な戦略の学習 |
| 自動運転 | 周囲の状況に応じた最適な運転操作の学習 | 安全で効率的な運転の実現 |
| ロボット制御 | 複雑な動作の学習 | 危険な作業の自動化 |
| 医療診断 | 患者の症状や検査データに基づいた最適な治療方針の決定 | 正確な診断の実現 |
| 金融取引 | 市場の動向予測と最適な投資判断 | リスクを抑えた高収益投資 |