
モデル学習の重要性

AIを知りたい
先生、「モデル学習」って一体何ですか?難しそうでよく分かりません。

AIエンジニア
そうだね。「モデル学習」とは、人間でいう学習と同じように、AIにたくさんの例題を見せて、正しい答えを覚えさせることだよ。例えば、犬と猫の写真をたくさん見せて、「これは犬」「これは猫」と教えていくことで、AI自身が見分けられるようになるんだ。
AIを知りたい
なるほど!でも、一度覚えたら終わりじゃないんですよね?
AIエンジニア
その通り!世の中の情報は常に変化しているから、AIも常に新しい情報を学び続ける必要があるんだ。人間と同じように、一度覚えたことを復習したり、新しいことを学んだりすることで、より賢くなっていくんだよ。
Model Trainingとは。
人工知能を作る言葉で「モデル訓練」というものがあります。人工知能の仕組みを作る時は、それぞれの仕組みが質の良い情報や、正しい繋がり方、結果の手本から学べるようにすることが大切です。この学習のやり方は、模様を見つけて、次に何が起こるかを予想し、頼まれた仕事をできるように人工知能に教えることです。これは、結果にちゃんと表すために絶対に必要です。人工知能を取り巻く環境や会社の求めるものが変わると、人工知能は学び続けなければなりません。その過程で、きちんと整理された情報を使う時の危険を減らすための追加の学習が必要になることもあります。定期的に学習させたり、正しく動いているか確かめたりせずに人工知能を放っておくと、偏りができたり、質の悪いものを作ってしまったりする危険が大きくなります。
モデル学習とは

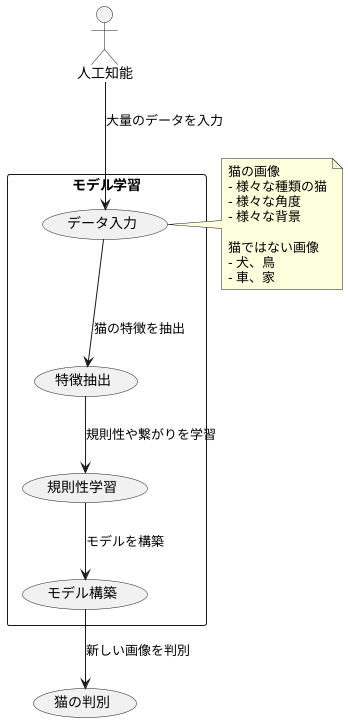
人が物事を学ぶように、人工知能も学ぶ必要があります。この学習のことを、モデル学習と呼びます。人工知能の中核を担うこのモデル学習は、大量の情報を与え、そこから規則性や繋がりを見つけることで行われます。まるで、たくさんの絵を見て、それが猫なのか犬なのかを学ぶ子どものようなものです。
例えば、猫を判別できる人工知能を作りたいとします。この場合、大量の猫の画像と、猫ではない画像を人工知能に学習させます。猫の画像には、様々な種類の猫、様々な角度から撮られた猫、様々な背景の猫が含まれているでしょう。これらの画像を人工知能は一つ一つ分析し、猫の特徴を捉えようとします。耳の形、目の形、ひげ、体の模様、毛並み、姿勢など、猫には猫特有の特徴があります。人工知能は、これらの特徴を大量のデータから抽出し、猫とは何かを学習していくのです。
同時に、猫ではない画像、例えば犬や鳥、車や家などの画像も学習させることで、猫の特徴をより明確に捉えることができます。猫ではないものを見ることで、猫とは何が違うのかを理解し、猫であることの条件を絞り込んでいくのです。
この学習プロセスは、まるで子どもが繰り返し練習することで自転車に乗れるようになる過程に似ています。最初は転んだり、うまくバランスが取れなかったりするかもしれませんが、練習を重ねるにつれて、無意識のうちに自転車の乗り方を体得していくように、人工知能も大量のデータからパターンを学び、最終的には新しい画像を見せても、それが猫かそうでないかを判断できるようになるのです。このようにして、人工知能は特定の作業をこなすための知識を身につけていきます。そして、このモデル学習こそが、人工知能の性能を大きく左右する重要な工程と言えるでしょう。
質の高いデータの必要性

人工知能の学習において、質の高いデータは欠かせません。これは、料理人がおいしい料理を作るために新鮮な食材が必要なのと同じです。どんなに優れた調理技術を持っていても、腐った食材を使えばおいしい料理はできません。同様に、どんなに高度な学習アルゴリズムを用いても、質の低いデータを使って学習させた人工知能は、期待通りの成果を生み出すことができません。
質の高いデータとは、具体的にどのようなものでしょうか?まず、データが正確であることが重要です。例えば、医療診断支援のモデルを学習させる場合、誤った診断結果を含むデータを使えば、人工知能も誤った診断を学習してしまいます。料理で言えば、材料の分量を間違えると味が変わってしまうのと同じです。次に、データに偏りがないことも重要です。特定の地域や年代のデータばかりを使って学習させると、それ以外の地域や年代には対応できない人工知能になってしまいます。これは、特定の食材だけを使った偏った料理しか作れない料理人に似ています。最後に、目的とする作業に関連するデータであることも重要です。天気予報のモデルを学習させるのに、株価のデータを使っても意味がありません。料理で言えば、肉料理を作りたいのに、魚介類ばかり集めても仕方がないのと同じです。
質の高いデータを集めるためには、データの収集、選別、加工に細心の注意を払う必要があります。新鮮な食材を選ぶように、必要なデータを注意深く選び、不要なデータや誤ったデータを取り除く必要があります。また、集めたデータを適切に加工することも重要です。これは、食材を洗ったり、切ったり、下ごしらえをする作業に似ています。これらの作業を丁寧に行うことで、質の高いデータが確保され、信頼性が高く、性能の良い人工知能を開発することができます。これは、おいしい料理を作るための土台となる新鮮な食材を準備するのと同じく、人工知能開発の基盤となります。
| 要素 | AI開発 | 料理 |
|---|---|---|
| 重要性 | 質の高いデータが必要 | 新鮮な食材が必要 |
| データの正確性 | 誤った診断結果を含むデータ→誤った診断 | 材料の分量間違い→味が変わる |
| データの偏り | 特定のデータ→偏ったAI | 特定の食材→偏った料理 |
| データの関連性 | 目的と無関係なデータは意味がない | 肉料理に魚介類は不要 |
| データ収集 | データの収集、選別、加工に注意 | 新鮮な食材を選び、不要なものを取り除く |
| データ加工 | 適切な加工が必要 | 食材の洗浄、カット、下ごしらえ |
| 結果 | 信頼性が高く、性能の良いAI | おいしい料理 |
継続的な学習の重要性

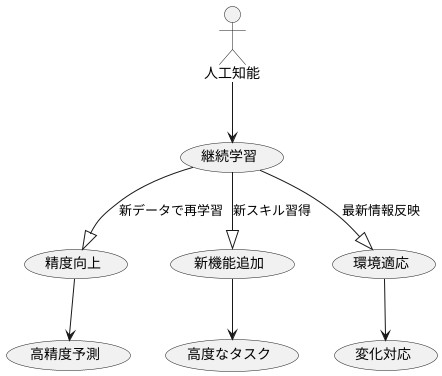
人工知能の世界は、まるで生き物のように常に変化を続けています。次々と新しい情報や技術が生まれてくるため、一度学習を終えた人工知能のモデルであっても、すぐに時代遅れになってしまう可能性があります。まるで、勉強を怠ると試験で良い点が取れなくなってしまう人間のようです。だからこそ、人間が常に新しい知識や技術を学ぶように、人工知能のモデルも継続的に学習することが重要なのです。
この継続的な学習は、一度作ったきり人工知能のモデルを放置しておくのではなく、定期的に新しいデータを取り込んで再学習させることを意味します。人間が教科書を何度も読み返したり、新しい参考書で学ぶことで知識を深めるのと同じように、人工知能も継続的に新しいデータを学習することで、常に最新の情報を反映し、変化する環境に適応できるようになります。
継続的な学習には、他にも様々な利点があります。例えば、モデルの精度を向上させることができます。新しいデータを学習することで、人工知能はより正確な予測や判断を行うことができるようになります。また、新しい機能を追加することも可能です。人間が新しいスキルを身につけるように、人工知能も新しいデータを通じて新たな機能を習得し、より高度なタスクをこなせるようになります。
このように、継続的な学習は、人工知能モデルを常に最新の状態に保ち、その価値を最大限に引き出すための重要な鍵となります。人間が学び続けることで成長していくように、人工知能も継続的な学習によって進化し、私たちの生活をより豊かにしてくれるのです。
学習におけるリスク軽減

学習には、様々な落とし穴があります。例えば、顔の特徴を捉えて個人を識別するシステムを考えてみましょう。もし、学習に使ったデータに特定の肌の色や性別の人の画像ばかりが含まれていたとしたらどうでしょうか。そのシステムは、学習データに含まれていなかった肌の色や性別の人の顔をうまく認識できないかもしれません。これは、学習データに偏りがあったことが原因です。
このような偏りは、思わぬ結果を招くことがあります。例えば、採用選考で使うシステムが、過去の採用データに基づいて学習していたとします。もし過去の採用において特定の属性の人が優遇されていたら、システムも同じように特定の属性の人を優遇するようになってしまいます。これは公平性に欠けるだけでなく、優秀な人材を見逃すことにも繋がります。
学習データの偏りをなくすには、様々な工夫が必要です。まず、学習データを集める段階で、多様な属性のデータが含まれるように注意深く集める必要があります。色々な人種、性別、年齢、地域など、あらゆる属性の人を網羅したデータを集めることが大切です。もし偏りがある場合は、不足している属性のデータを補うか、偏りを補正する技術を使うことも考えられます。
学習データの正確さも重要です。データに誤りやノイズが含まれていると、システムが間違ったことを学習してしまいます。例えば、犬の画像に猫というラベルが誤って付いていた場合、システムは犬を猫と認識するようになってしまいます。このような誤りを防ぐためには、学習データの質を注意深く確認し、誤りがあれば修正する必要があります。人間が目で見て確認する方法や、コンピュータを使って自動的に誤りを検出する方法など、様々な方法があります。
偏りや誤りのない、質の高い学習データを用いることで、信頼できるシステムを作ることができます。これは、システムを安心して使えるだけでなく、社会全体にとって有益な技術を作る上でも大切なことです。信頼できるシステムを作ることは、私たちの社会をより良くするための第一歩と言えるでしょう。
| 学習における落とし穴 | 問題点 | 対策 |
|---|---|---|
| 学習データの偏り | 特定の属性のデータが多い場合、システムが偏った認識をする。例:顔認識システムが特定の肌の色や性別を認識できない、採用選考システムが特定の属性を優遇する。 | 多様な属性のデータ収集、不足データの補填、偏りを補正する技術の利用 |
| 学習データの誤り | 誤ったラベルやノイズを含むデータで学習すると、システムが間違った認識をする。例:犬の画像に「猫」のラベルが付いていると、犬を猫と認識する。 | 学習データの質の確認、誤りの修正(人間による確認、コンピュータによる自動検出) |
検証の必要性

人工知能の学習は、まるで人が新しいことを学ぶようなものです。教科書を読んで知識を詰め込んだだけでは、本当に理解しているとは言えません。試験を受けて、習ったことがきちんと身についているか、試す必要があります。人工知能も同じで、大量のデータで学習させた後、その成果を確かめるための検証が欠かせません。
検証には、学習に使っていない新しいデータを使います。これは、試験で教科書に載っていない問題が出るのと同じです。学習データだけでの評価では、まるで教科書の内容をそのまま暗記して試験に臨むようなもので、真の理解度を測ることができません。新しいデータを使ってこそ、人工知能が未知の状況にどう対応するか、その真の実力を知ることができるのです。
検証の結果が思わしくなければ、学習方法を見直す必要があります。人が試験で悪い点を取ったら、勉強方法を変えたり、苦手な部分を重点的に復習したりするでしょう。人工知能も同様に、学習データの内容や量、あるいは学習に使った手順その自体に問題があるかもしれません。
例えば、偏ったデータで学習させれば、偏った判断をする人工知能になってしまいます。これは、特定の教科ばかり勉強して、他の教科を全く勉強しないようなものです。バランスの良いデータで学習させることが、偏りのない公正な判断ができる人工知能を作る上で重要です。
このように、学習と検証を繰り返すことで、人工知能の能力を高めていくことができます。人が何度も試験を受けて、その度に学習方法を改善していくように、人工知能も検証と再学習を繰り返すことで、より正確で信頼性の高いものへと成長していくのです。そして最終的には、実社会で役立つ、頼もしい人工知能システムを完成させることができるでしょう。
放置の危険性

機械学習モデルは、人間が道具を使うのと同じように、適切な手入れと管理が必要です。一度作り上げたモデルをそのまま放置しておくと、さまざまな問題が生じ、その精度は時間の経過とともに落ちていきます。これは、使っていない道具が錆びついてしまう状況とよく似ています。
モデル構築時に学習させたデータは、当時の社会状況や情報に基づいています。しかし、社会は常に変化し、新しい情報も次々と出てきます。そのため、放置されたモデルが学習した古い情報は、次第に現実とのずれが生じ、社会の変化や新しい情報を反映できなくなります。まるで古い地図を使って新しい道を進むようなもので、正しい道案内ができなくなるのです。
このような状況下でモデルを使い続けると、予測の正確さが失われ、誤った判断につながる危険性が高まります。例えば、商品の需要予測モデルが最新の情報を取り込めていないと、過剰な在庫を抱えたり、逆に品不足を起こしたりする可能性があります。また、顧客の信用度を評価するモデルが古いデータに基づいていれば、誤った評価を下し、適切なサービスを提供できない可能性も出てきます。
さらに、データに含まれる偏りが増幅されることで、公平性や倫理的な問題を引き起こす可能性も懸念されます。特定の集団に不利な結果をもたらすような偏ったデータで学習されたモデルは、その偏りをさらに強化してしまう可能性があります。これは、社会全体の公平性を損なうだけでなく、企業の信頼性にも悪影響を及ぼします。
このような事態を避けるためには、定期的な見直しと再学習が不可欠です。モデルが常に最新の情報で学習し、変化する状況に適応できるようにすることが重要です。これは、人間が常に新しい知識や技術を学ぶのと同じです。定期的にモデルの性能を検証し、必要に応じて再学習を行うことで、モデルの精度を維持し、信頼できる結果を得ることができます。これは、人工知能システムを長く安全に使い続けるために、欠かすことのできない取り組みと言えるでしょう。
| 問題点 | 具体例 | 対応策 |
|---|---|---|
| 精度の低下 (現実とのずれ) | 古い地図で新しい道を進む | 定期的な見直しと再学習 |
| 予測の正確さ失われ、誤った判断 | 需要予測の失敗(過剰在庫/品不足)、顧客信用度の誤評価 | モデルの性能検証、必要に応じた再学習 |
| データの偏りの増幅、公平性・倫理的問題 | 特定集団に不利な結果 | 最新の情報で学習、変化への適応 |