網羅されたデータの重要性

AIを知りたい
『データの網羅性』って、どういう意味ですか?たくさんデータを集めることと同じですか?

AIエンジニア
いい質問ですね。たくさんデータを集めることも大切ですが、データの網羅性とは、AIが学習するために必要な、あらゆる可能性を網羅したデータを集めることを指します。 例えば、猫を認識するAIを作るなら、色々な種類の猫、色々な角度から見た猫、色々な背景の猫など、様々なデータが必要です。
AIを知りたい
色々な種類の猫、色々な角度…なるほど。つまり、色んな種類のデータをたくさん集めるってことですね!
AIエンジニア
その通りです。データの種類が少ないと、AIは特定の条件でしか正しく判断できなくなってしまいます。色々な条件に対応できるよう、偏りなく、あらゆるパターンを網羅したデータを集めることが『データの網羅性』なのです。
データの網羅性とは。
人工知能を鍛えるための言葉に「データの網羅性」というものがあります。これは、人工知能の学習材料となるデータを、できるだけ広く集めることが大切だということを意味します。人工知能は与えられたデータから学ぶものなので、データが少ないと、他の学習済みのモデルを応用する「転移学習」といった技術を使っても、十分な精度は得られません。本当に良い結果を得るためには、あらゆる状況を網羅したデータが必要なのです。だからこそ、集めるデータの網羅性が重要になるのです。
質の高い学習データ

人工知能の模型を鍛えるには、質の高い学習資料が欠かせません。模型は、与えられた資料から模様や決まり事を学び、それを基に予測や判断を行います。そのため、学習資料の質が模型の出来栄えを大きく左右します。良い資料とは、一体どのようなものでしょうか?
まず大切なのは、資料の網羅性です。網羅性が高い資料とは、調べたい事柄や出来事を広く、漏れなく捉えた資料のことです。例えば、犬の種類を見分ける模型を鍛える場合を考えてみましょう。このためには、様々な犬種、年齢、毛色、大きさの犬の絵姿資料が必要です。特定の犬種や条件に偏った資料で鍛えると、模型はそれ以外の犬種や条件に対して正しく見分けられない場合があります。例えば、チワワの絵姿ばかりで模型を鍛えた場合、大きな犬種であるセントバーナードを犬として認識できないかもしれません。また、子犬の絵姿ばかりで鍛えた場合、成犬を認識できないかもしれません。このように、網羅性を欠いた資料で鍛えられた模型は、特定の状況でしか能力を発揮できません。
網羅性の高い資料を用意することで、模型はより多くの状況に対応できるようになります。様々な犬種、年齢、毛色、大きさの犬の絵姿資料を網羅的に集めることで、模型は初めて見る犬でも「犬」であると認識し、さらには犬種まで正確に判断できるようになります。つまり、網羅性の高い資料は、模型がより広く使える、正確な予測を行うために欠かせないのです。
さらに、資料の正確さも重要です。例えば、犬の絵姿に「猫」というラベルが誤って付けられていると、模型は犬を猫と認識するように学習してしまいます。このような誤った情報は、模型の性能を低下させる大きな原因となります。他にも、資料の内容が最新であるか、偏りがないかなども重要な要素です。時代遅れの情報や特定の立場に偏った情報で模型を鍛えると、現実世界とは乖離した、役に立たない結果を生み出す可能性があります。
質の高い学習資料を集めるには、多くの時間と手間がかかります。しかし、模型の性能を最大限に引き出すためには、質の高い学習資料が不可欠です。地道な努力を惜しまず、質の高い資料を集め、整備していくことが、人工知能技術の発展に大きく貢献すると言えるでしょう。
| 要素 | 説明 | 例(犬種識別AIの場合) |
|---|---|---|
| 網羅性 | 調べたい事柄や出来事を広く、漏れなく捉えている。 | 様々な犬種、年齢、毛色、大きさの犬の画像データ |
| 正確性 | 誤った情報やラベル付けがない。 | 犬の画像に「犬」というラベルが正しく付けられている |
| 最新性 | 時代遅れの情報ではない。 | 最新の犬種に関する情報を含む |
| 公平性 | 特定の立場に偏った情報ではない。 | 特定の犬種のみを優遇するような情報を含まない |
データ不足への対応

情報を網羅することは理想ではありますが、現実にはすべての情報を集めることは難しい場合があります。特に、珍しい出来事や現象に関する情報は集めるのに時間やお金がかかるだけでなく、そもそも存在しない可能性もあります。このような情報不足の状態に対応するために、いくつかの方法が考えられます。
まず、他の分野で学習済みの成果物を別の分野に役立てる方法があります。これは、例えば、たくさんの絵で学習済みの絵を認識する仕組みを、医療用の絵の診断に役立てるようなものです。この方法を使うことで、情報が足りない問題をある程度軽くすることができます。しかし、この方法では、すべての情報を網羅した成果物と比べると、精度が劣る可能性があります。
また、似たような情報で補完する方法もあります。もし、目的の情報の代わりに似たような情報があれば、それを利用することで情報不足を補うことができます。例えば、ある地域の天気の情報が足りない場合、近隣の地域の天気の情報を利用することで、ある程度の予測が可能になります。この方法の精度は、似た情報の質に大きく左右されます。そのため、似た情報の選定は慎重に行う必要があります。
さらに、情報を作る方法も有効です。現実の情報を集めることが難しい場合、コンピュータなどで人工的に情報を作ることで、情報不足を解消できます。この方法は、特に実験や検証の段階で役立ちます。ただし、人工的に作った情報は現実とは異なる場合があるので、その点に注意が必要です。
このように、情報不足に対応するためには様々な方法があります。それぞれの方法には利点と欠点があるので、状況に応じて適切な方法を選ぶことが重要です。そして、どのような方法を用いる場合でも、可能な限り多くの情報を集める努力は怠らないようにしましょう。
| 方法 | 説明 | 利点 | 欠点 |
|---|---|---|---|
| 転移学習 | 他の分野で学習済みの成果物を別の分野に役立てる。例えば、絵の認識モデルを医療画像診断に利用する。 | 情報不足をある程度解消できる。 | 精度が劣る可能性がある。 |
| 類似データによる補完 | 似たような情報で補完する。例えば、近隣の地域の天気情報から目的地域の天気を予測する。 | 情報不足を補える。 | 精度は類似データの質に依存する。類似データの選定が重要。 |
| データ生成 | コンピュータなどで人工的に情報を作る。 | 実験や検証段階で役立つ。 | 生成データは現実と異なる場合があるため注意が必要。 |
理想的なモデル精度

人工知能の模型を作る上で、一番大切なのは、正確に物事を予測したり判断したりできる模型を作ることです。この目標を達成するには、模型に様々なことを学ばせるための情報の集まりである学習データが重要になります。そして、学習データは、あらゆる例を網羅している必要があります。
なぜなら、網羅的な学習データは、模型が学ぶべきパターンや規則性をより正確に捉えることを可能にするからです。例えば、犬の種類を学ぶ模型を作る場合、様々な種類の犬の画像データが必要です。チワワからセントバーナードまで、色々な大きさや毛色、顔立ちの犬の画像を学習させることで、模型は「犬らしさ」の本質を理解し、未知の犬種でも「これは犬だ」と正しく判断できるようになります。
反対に、もし学習データがチワワの画像ばかりだとどうなるでしょうか。模型は「小さい」「毛が短い」といった特徴を「犬らしさ」と誤って学習してしまうかもしれません。その結果、セントバーナードのような大型犬を見せても、犬だと認識できない可能性があります。このように、学習データの種類が少ないと、模型は重要な情報を見逃したり、間違ったパターンを覚えてしまったりするのです。
これは、模型の精度を低下させ、実際に使えるものにならない原因となります。想像してみてください。犬の種類を判別する模型が、大型犬を認識できないとしたら、実用化は難しいでしょう。
ですから、質の高い人工知能の模型を作るためには、あらゆる例を網羅した学習データを集めることが不可欠です。これは、高精度な人工知能模型開発の土台となる、最も重要な要素と言えるでしょう。
データ収集の重要性

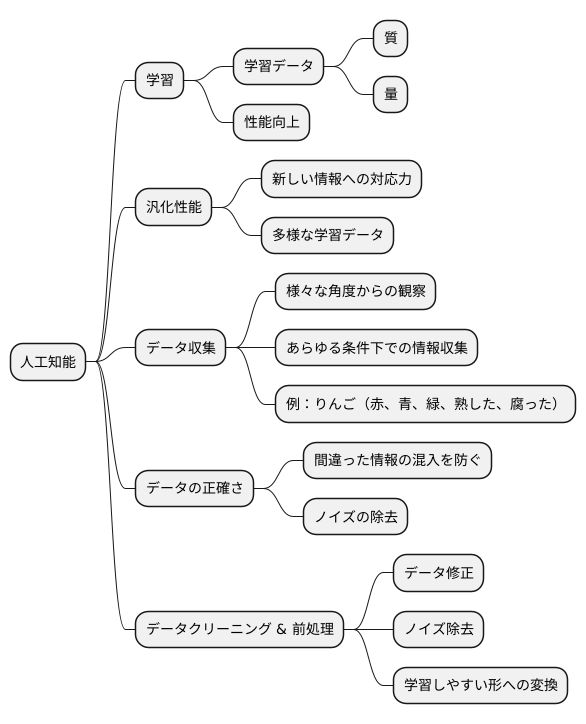
人工知能は、まるで人間の脳のように自ら学び賢くなる技術です。そして、その学習には大量の情報が必要です。この情報は「学習データ」と呼ばれ、人工知能の性能を左右する重要な役割を担っています。まさに、学習データの質と量が人工知能の賢さを決めるといっても過言ではありません。
特に、学習データに含まれる情報の幅広さは、人工知能の汎化性能に直結します。汎化性能とは、初めて出会う情報に対しても適切に判断できる能力のことです。人工知能が様々な状況に対応できるようになるためには、学習データが多様な状況を網羅していることが重要です。
そのため、データ収集は人工知能開発において非常に重要な工程となります。データ収集の際には、対象とする出来事や現象を様々な角度から観察し、あらゆる条件下での情報を集める必要があります。例えば、りんごを認識する人工知能を開発する場合、赤いりんごだけでなく、青いりんごや緑色のりんご、熟したりんごや腐ったりんごなど、様々な状態のりんごのデータを集める必要があります。
また、データの正確さも重要な要素です。間違った情報やノイズと呼ばれる不要な情報が含まれるデータで学習させると、人工知能は間違ったことを覚えてしまい、性能が低下する可能性があります。人間の子供に間違ったことを教えれば、間違った知識を身につけてしまうのと同じです。
そのため、データの収集だけでなく、集めたデータをきれいにする作業や、人工知能が学習しやすい形に整える作業も重要です。これらの作業は、データのクリーニングや前処理と呼ばれます。例えば、集めたデータの中に明らかに間違っている情報があれば修正したり、ノイズを取り除いたりする作業が必要になります。
高品質な人工知能を開発するためには、質の高い学習データが不可欠です。そして、質の高い学習データを得るためには、データ収集、クリーニング、前処理といった一連の工程を適切に行う必要があるのです。
今後の展望

人工知能の技術は、まるで生き物のように日々進化を続けています。そして、人工知能をより賢く、より役に立つものにするためには、学習のための情報の質と量が鍵となります。この情報の網羅性を高めるための、様々な新しい取り組みが始まっています。
例えば、限られた情報から、人工知能自身で新しい情報を作り出す技術が注目を集めています。これは、写真から似たような写真を作ったり、文章から続きを創作したりする技術を応用したものです。この技術を使うことで、集めるのが難しい情報を人工的に作り出し、学習に役立てることができるのです。
また、既存の情報を加工して、様々なバリエーションを生み出す技術も研究されています。例えば、一枚の写真を少しだけ変化させて、明るさや角度を変えた複数の写真を作り出すことで、人工知能はより多くの状況に対応できるようになります。これは、限られた情報からより多くの学びを得るための、効率的な学習方法と言えるでしょう。
しかし、情報の網羅性を追求する上で、忘れてはならないのが情報の適切な管理です。個人の秘密や大切な情報を含むデータは、慎重に取り扱わなければなりません。情報の価値を高めることと同時に、安全に守るための技術も、今後ますます重要になってきます。
人工知能の未来は、情報の質と量、そしてその適切な管理にかかっています。より良い社会を実現するために、これらの技術をバランス良く発展させていく必要があるでしょう。