質の高い学習データを集める重要性

AIを知りたい
『学習可能なデータの収集』って、たくさんのデータを集めればいいっていうわけじゃないんですよね?

AIエンジニア
その通りです。データは量だけでなく質も大切です。例えば、鳥の種類を判別するAIを作るのに、色んな種類の鳥が写っている写真を使うと、うまく判別できないことがあります。
AIを知りたい
なるほど。じゃあ、そういう写真は使わないほうがいいんですか?
AIエンジニア
そうですね。そういう写真は使わないか、必要な鳥だけを切り抜くなど、工夫が必要です。霧や雨で撮った写真は、AIを強くするのに役立つこともありますが、何が写っているか分からない写真は避けた方が良いでしょう。
学習可能なデータの収集とは。
人工知能に関する言葉で「学習に使えるデータを集める」ということについて説明します。機械学習では、データはたくさんあれば良いというわけではなく、学習に適した質の高いデータを集めることが大切です。たとえば、鳥の種類を見分ける人工知能を作りたい場合、たくさんの種類の鳥が写っている写真を使って学習させると、正しく見分けられない可能性があります。そのような写真は使わないようにするか、必要な部分だけを切り抜くなどの工夫が必要です。また、霧や雨、雪などの天候で撮られた写真は、様々な状況に対応できる人工知能を作るのに役立つこともありますが、何が写っているか分からないほどぼやけている写真は、学習には使わない方が良いでしょう。
はじめに

近頃、機械を賢くする技術が大きく進歩し、様々な分野で情報の活用が進んでいます。買い物をする時のおすすめ表示や、車の自動運転、病気の診断など、私たちの生活は既にこの技術の恩恵を受けています。この技術を支えているのが、学習に使う情報の集まりです。しかし、情報の量は多ければ良いというわけではなく、質の高い情報を集めることが何よりも大切です。
大量の情報をかき集めても、その中に誤りや不要な情報が多く含まれていたり、特定の種類の情報ばかりであったりすると、機械の学習はうまくいきません。例えるなら、料理人が腐った食材や偏った材料だけで美味しい料理を作れないのと同じです。質の悪い情報で機械を学習させると、期待通りの結果が得られないばかりか、間違った判断を下すようになってしまうかもしれません。自動運転の例で考えると、学習に使った情報に偏りがあると、特定の状況では正しく動作しなくなる可能性があります。これは大変危険なことです。
質の高い情報を集めるには、まず何のためにその情報を使うのかを明確にする必要があります。目的が定まれば、必要な情報の種類や量が見えてきます。また、集めた情報の正確性を確認することも欠かせません。誤った情報が混ざっていないか、偏りがないかなどを注意深く調べ、必要に応じて修正や追加を行う必要があります。さらに、情報の鮮度も重要です。古い情報では、現状にそぐわない判断をしてしまう可能性があります。常に最新の情報を集め、機械学習の精度を高める努力が求められます。このように、質の高い情報を集めることは、機械学習を成功させる上で最も基本的な条件であり、私たちの生活の安全や利便性を向上させるためにも不可欠です。
| 項目 | 説明 |
|---|---|
| 情報の重要性 | 機械学習の進歩により様々な分野で情報活用が進む中で、質の高い情報が重要。 |
| 質の低い情報の例 | 誤りや不要な情報、特定の種類の情報ばかりである。 |
| 質の低い情報の悪影響 | 期待通りの結果が得られない、間違った判断をする(例:自動運転の誤作動)。 |
| 質の高い情報を集める方法 | 1. 情報を使う目的を明確にする 2. 必要な情報の種類と量を見極める 3. 集めた情報の正確性を確認する(誤り、偏りがないか) 4. 情報の鮮度を確認する(最新の情報か) |
| まとめ | 質の高い情報を集めることは、機械学習を成功させる上で最も基本的な条件であり、私たちの生活の安全や利便性を向上させるためにも不可欠。 |
適切なデータの選定

機械学習モデルを作る上で、適切な学習データを選ぶことはとても大切です。学習データの質がモデルの性能を大きく左右するからです。たとえば、鳥の種類を見分けるモデルを作りたいとしましょう。この時、どんなデータを集めるべきでしょうか。
まず、1枚の写真には1種類の鳥しか写っていないようにすることが重要です。もし、1枚の写真に複数の種類の鳥が写っていると、モデルは鳥の種類を正しく見分けられなくなるかもしれません。複数の鳥が写っている写真は、学習データから外すか、目的の鳥だけを切り抜く必要があります。
次に、色々な種類の鳥の写真を同じくらいの数だけ集めることも重要です。特定の種類の鳥の写真ばかり集めてしまうと、モデルはその種類の鳥を見分けることばかりに集中してしまい、他の種類の鳥を見分けるのが苦手になってしまうかもしれません。たとえば、スズメの写真ばかりで学習したモデルは、スズメを見分けるのは得意でも、ツバメやカラスを見分けるのは苦手になってしまうでしょう。
さらに、写真の質にも気を配る必要があります。ぼやけていたり、暗すぎたりする写真は、モデルの学習を邪魔する可能性があります。鮮明で明るい写真を使うことで、モデルは鳥の特徴をより正確に捉えることができます。また、鳥が木の枝に隠れていたり、後ろ向きだったりする写真も避けるべきです。鳥全体がはっきり写っている写真を選ぶことで、モデルは鳥の種類をより正確に見分けられるようになります。
このように、適切な学習データを選ぶことは、高性能な機械学習モデルを作るための第一歩です。データの質、量、そして種類のバランスに注意を払い、モデルにとって最適な学習環境を用意しましょう。
| ポイント | 説明 |
|---|---|
| 写真の被写体 | 1枚の写真には1種類の鳥のみ写っている。複数の鳥が写っている写真は除外またはトリミングする。 |
| データの量 | 様々な種類の鳥の写真を同じくらいの数だけ集める。特定の種類に偏らないようにする。 |
| 写真の質 | 鮮明で明るい写真を使用する。ぼやけていたり、暗すぎたりする写真は避ける。鳥全体がはっきり写っている写真を優先する。 |
データの質の確認

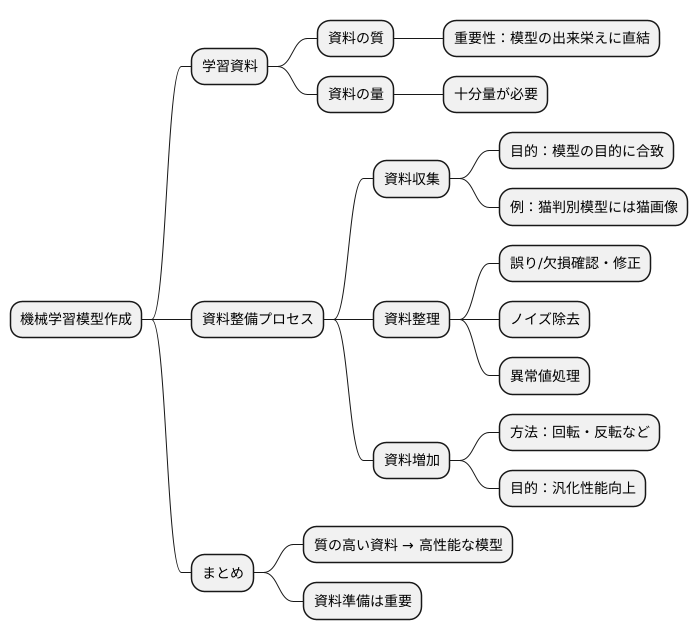
機械学習の精度は、学習に使うデータの質に大きく左右されます。そのため、データの質の確認は極めて重要です。今回のテーマである画像データの場合、霧や雨、雪といった悪天候で撮影された画像も、ある程度は学習に役立ちます。これらの画像は、現実世界で起こりうる様々な状況をモデルに学習させるための良い例となります。つまり、多少の視界不良や画像のぼやけがあっても、対象物がはっきりと認識できる画像であれば、学習データとして有効です。これらの画像を学習に用いることで、モデルは多少のノイズや変化にも対応できるようになり、頑健性が向上します。例えば、霧がかった風景写真でも、山の輪郭や木々の形が認識できる程度であれば、問題なく学習データとして利用できます。
しかし、悪天候の影響で何が写っているか全く分からない画像は、学習データから除外するべきです。あまりにも画像が劣化している場合、モデルは画像から意味のある情報を抽出できません。このような画像はノイズとして扱われ、モデルの学習を妨げ、精度の低下につながる可能性があります。例えば、雪で真っ白になった写真や、豪雨で景色が全く見えない写真は、学習データとして不適切です。このような画像を学習に用いると、モデルは誤った特徴を学習してしまう可能性があります。
まとめると、学習データに用いる画像は、対象物がはっきりと認識できるものである必要があります。多少のノイズや変化を含む画像は、モデルの頑健性を向上させるために有効ですが、ノイズとして扱われるほど劣化している画像は除外するべきです。データの質を適切に管理することで、高精度な機械学習モデルを構築することができます。
データの前処理

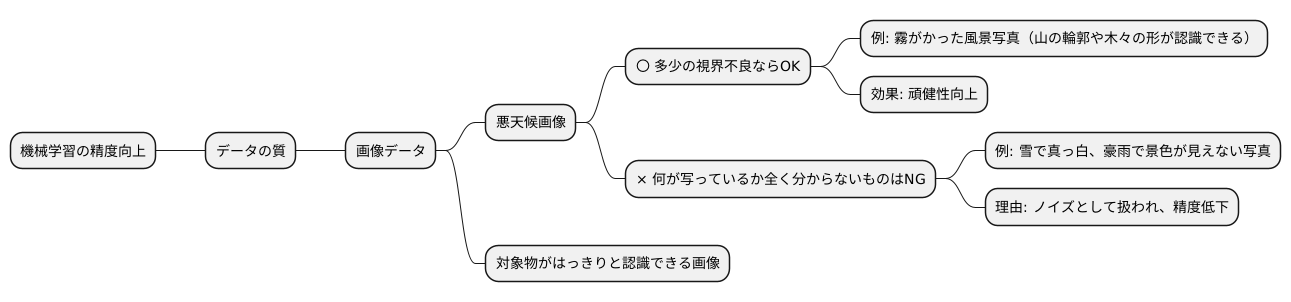
機械学習モデルの性能を高める上で、質の高い学習データの準備は欠かせません。そのためには、データの前処理が非常に重要となります。前処理とは、集めた生のデータをモデルが学習しやすい形に整える作業です。様々な手法がありますが、目的はデータのノイズを取り除き、質を高めることです。
まず、データの中に含まれるノイズを取り除く作業があります。ノイズとは、誤った値や異常値、不要な情報など、モデルの学習を妨げるデータのことです。例えば、画像データであれば、画像に写り込んだゴミやノイズ、明るさやコントラストの不適切な設定などがノイズに当たります。これらのノイズは、画像編集ソフトなどを用いて除去したり、明るさやコントラストを調整することで改善できます。数値データであれば、入力ミスや測定誤差による異常値などがノイズとなります。このようなノイズは、統計的な手法を用いて検出し、除去する必要があります。
次に、データの正規化があります。これは、異なる尺度や範囲のデータを同じ尺度に変換する作業です。例えば、身長と体重のように単位が異なるデータや、年齢と年収のように範囲が異なるデータを扱う場合、それぞれのデータの尺度を揃える必要があります。正規化することで、モデルがデータの特徴を正しく捉え、学習効率を向上させることができます。具体的な手法としては、最小値0、最大値1の範囲に値を変換する方法や、平均0、標準偏差1に値を変換する方法などがあります。
さらに、欠損値の補完も重要な前処理です。欠損値とは、データの一部が欠けている状態のことです。欠損値があると、モデルが正しく学習できない場合があります。そのため、欠損値を適切な値で補完する必要があります。例えば、平均値や中央値で補完する方法や、他のデータから予測して補完する方法などがあります。適切な前処理を行うことで、学習データの質が向上し、モデルの性能を最大限に引き出すことができます。前処理の手法はデータの種類や特性、モデルの種類によって適切な方法が異なります。そのため、様々な手法を試し、最適な方法を選択することが重要です。
データの増強

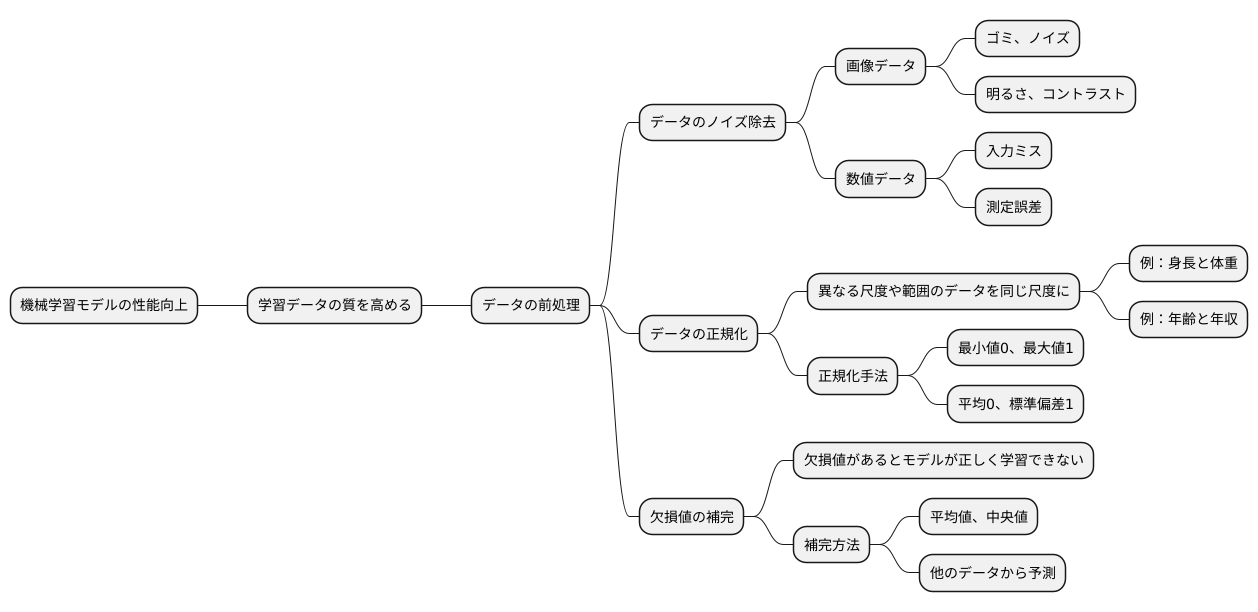
機械学習において、質の高い学習データはモデルの性能向上に不可欠です。しかし、十分な量の学習データを集めることは容易ではありません。そこで、限られたデータから人工的にデータ量を増やす手法として「データの増強」が用いられます。
データの増強は、既存のデータに様々な変換を加えることで、新たなデータを生成する技術です。例えば、画像データを扱う場合、回転、反転、拡大縮小、色の変更、明るさの調整など、多様な変換を適用できます。
画像認識のタスクを例に考えてみましょう。学習データとして猫の画像が一枚しかないとします。この一枚の画像だけを用いて学習すると、モデルは特定の角度や大きさの猫しか認識できない可能性があります。しかし、データの増強により、元の猫の画像を回転させたり、拡大縮小したりすることで、様々なバリエーションの猫の画像を生成できます。これにより、モデルは多様な角度や大きさの猫を学習できるようになり、未知の猫の画像に対しても正しく認識できる可能性が高まります。つまり、モデルの汎化性能が向上するのです。
ただし、データの増強を行う際には注意も必要です。変換の方法によっては、元のデータの重要な特徴が失われたり、誤った特徴が追加されたりする可能性があります。例えば、手書き数字認識のタスクで「6」の画像を180度回転させると「9」のように見えてしまいます。このような変換は、モデルの学習を妨げる可能性があるため避けるべきです。データの増強を行う際は、タスクの性質を考慮し、元のデータの特性を損なわない変換を選ぶことが重要です。適切なデータの増強は、限られたデータからでも高性能なモデルを構築する上で非常に有効な手段となります。
まとめ

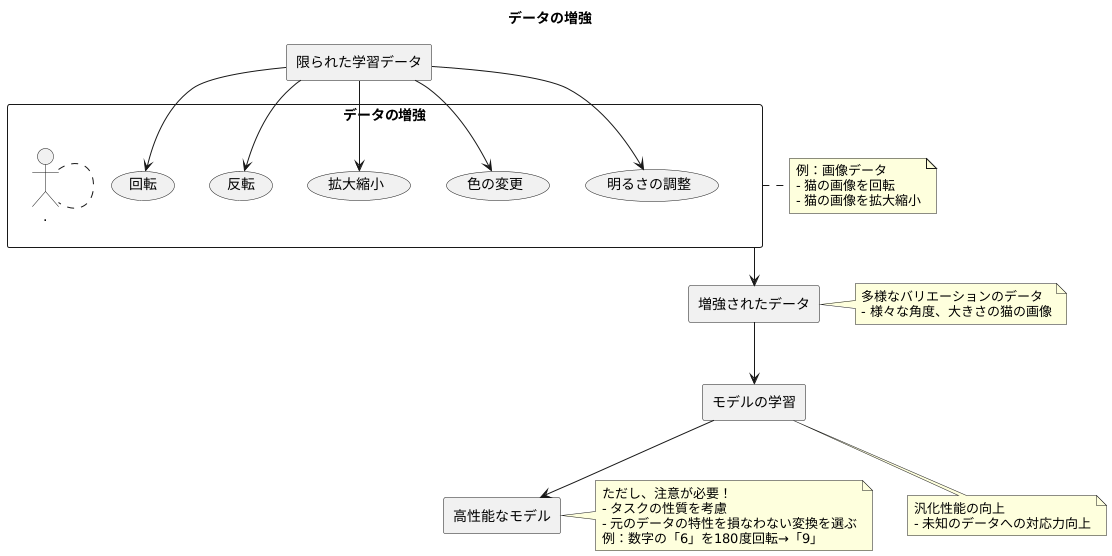
機械学習の模型を作る上で、学習に使う資料の良し悪しは模型の出来栄えに大きく関わってきます。資料はたくさんあるだけでは不十分で、質の高さも重要です。良い資料を選んで、質をきちんと保つことで、模型の正しさを上げることができます。そのため、資料を集め、整え、増やすといった一連の作業に丁寧に取り組むことが欠かせません。
まず、資料を集める段階では、模型の目的に合った資料を選ぶことが大切です。例えば、猫の種類を判別する模型を作るなら、猫の画像を集める必要がありますが、犬や鳥の画像は必要ありません。目的を明確にして、それに合った資料を集めることで、模型の学習効率を高めることができます。
次に、集めた資料を整える作業も重要です。資料に誤りや抜けがないかを確認し、必要に応じて修正や削除を行います。例えば、画像にノイズが含まれている場合は、それを除去する必要があります。また、数値データの場合は、異常値を適切に処理する必要があります。これらの処理を行うことで、模型の学習がスムーズに進み、より正確な結果を得ることができます。
さらに、資料の量が少ない場合は、資料を増やす工夫も必要です。例えば、画像を回転させたり、反転させたりすることで、元の画像とは異なる新たな画像を生成することができます。このようにして資料を増やすことで、模型の汎化性能を高め、未知の資料に対しても正確な予測ができるようになります。
このように、質の高い学習資料を集め、整え、増やすことは、高性能な機械学習模型を作るための最初の大切な一歩です。時間をかけて丁寧に資料の準備を行うことで、最終的に得られる模型の性能が大きく向上します。地道な作業ではありますが、質の高い資料こそが、機械学習の成功の鍵と言えるでしょう。