
機械翻訳の進化:統計的アプローチ

AIを知りたい
先生、『統計学的機械翻訳』ってどういう意味ですか?最近、インターネットが普及したことが関係しているみたいですが、よくわかりません。

AIエンジニア
いい質問だね。統計学的機械翻訳とは、たくさんの翻訳の例文をコンピュータに学習させて、一番確率の高い訳を統計的に選び出す翻訳方法のことだよ。インターネット上にたくさんの文章があるおかげで、学習に使える例文が爆発的に増えたんだ。
AIを知りたい
なるほど。つまり、たくさんの例文を統計的に処理することで翻訳するってことですね。でも、例文を統計的に処理するって具体的にどういうことですか?
AIエンジニア
そうだね。例えば、「こんにちは」を英語に翻訳したいとする。コンピュータは、過去の膨大なデータから「こんにちは」に対応する英語の表現とその出現頻度を調べ、「Hello」や「Good morning」など候補を見つけ出す。そして、どの英語表現が最もよく使われているかを統計的に計算し、一番確率の高い「Hello」を翻訳結果として出力するんだよ。
統計学的機械翻訳とは。
『統計学的機械翻訳』という、人工知能に関係する言葉について説明します。ここ二十年ほどで、インターネットのホームページが爆発的に増えました。このおかげで、ホームページ上の文字を扱う、自然言語処理という技術の研究が大きく進みました。
言葉の処理技術の進歩

近ごろ、情報網の広がりとともに、目に余るほどの量の情報を網羅した資料が使えるようになりました。この情報の奔流は、人の言葉を扱う技術の探求にとって、まさに宝の山のようなものです。これまで、人が手仕事で行っていた言葉の分析や処理を、計算機が自動でできるようにするための技術、すなわち人の言葉を扱う技術の探求が、大きく進みました。情報網上の文字情報は、言葉の多様さや複雑さを知るための大切な資料であり、この資料を使うことで、より高度な人の言葉を扱う技術を作ることが可能になりました。
特に、莫大な量の資料から言葉の型や法則を自動で学ぶ機械学習という方法が、この分野の進展を大きく支えました。例えば、大量の文章を読み込ませることで、計算機は言葉の意味や繋がりを学習し、文章の要約や翻訳、質問応答といった複雑な作業をこなせるようになります。また、人の話し言葉を文字に変換する技術や、逆に文字を音声に変換する技術も、機械学習によって精度が飛躍的に向上しました。これにより、音声認識を使った機器の操作や、読み上げ機能を使った情報伝達などが、より身近なものになりました。
さらに、情報網上の会話や意見交換など、生の言葉のやり取りの資料も増え、人の言葉の微妙なニュアンスや感情を理解する研究も進んでいます。例えば、書き込みの言葉遣いから書き手の感情を推測したり、会話の流れから話し手の意図を汲み取ったりする技術が開発されています。このような技術は、より自然で円滑な人と計算機の対話を実現するために欠かせないものです。まさに、情報の増加と技術の進歩が互いに影響し合い、人の言葉を扱う技術は大きな発展を遂げているのです。今後、ますます高度化していくであろうこの技術は、私たちの暮らしをより豊かで便利なものにしていくと期待されます。
統計的機械翻訳の登場

かつての機械翻訳は、言語の専門家たちが作り上げた規則を基に、文章を分解し、翻訳していました。しかし、この規則に基づいた方法では、複雑な言語の仕組みを全て捉えることができず、翻訳の正確さには限界がありました。そこで、新しい方法として現れたのが統計的機械翻訳です。
この統計的機械翻訳は、大量の対訳データ、つまり原文とそれに対応する翻訳文の組み合わせをコンピュータに学習させることで、翻訳の確率の型を作ります。具体的には、ある単語が別の単語へと翻訳される確率や、ある単語の並びが別の単語の並びへと翻訳される確率を、データに基づいて統計的に計算します。
例えば、「こんにちは」という日本語が「Hello」という英語に翻訳される確率や、「今日は良い天気です」という日本語が「It is a fine day today」という英語に翻訳される確率を、たくさんの対訳データから計算するのです。このようにして作られた確率の型を基に、最も自然な翻訳文を作り出すことが可能になります。
統計的機械翻訳は、従来の方法に比べて、より柔軟で正確な翻訳を実現できる可能性を秘めており、機械翻訳の世界に大きな変化をもたらしました。大量のデータを使うことで、言語の微妙なニュアンスや、文脈に合わせた適切な表現を学習できるようになったのです。これは、従来の規則に基づいた方法では難しかった点です。
さらに、統計的機械翻訳は、新しい言語への対応も比較的容易です。十分な量の対訳データさえあれば、どんな言語の組み合わせでも翻訳の型を作ることができます。そのため、様々な言語に対応できる機械翻訳システムの開発が促進されました。このように、統計的機械翻訳は、機械翻訳の技術を大きく進化させ、グローバルなコミュニケーションを促進する上で重要な役割を果たしています。
| 機械翻訳の手法 | 仕組み | メリット | デメリット |
|---|---|---|---|
| 規則ベース | 言語専門家が作成した規則に基づき翻訳 | – | 複雑な言語に対応できない。翻訳の精度に限界がある。 |
| 統計的機械翻訳 | 大量の対訳データから翻訳確率を学習し、確率に基づき翻訳 | 柔軟で正確な翻訳が可能。文脈に合わせた表現が可能。新しい言語への対応が容易。 | 大量の対訳データが必要。 |
対訳データの重要性

言葉の壁を取り払い、異なる言葉を話す人々が円滑に意思疎通するためには、翻訳技術が欠かせません。中でも、統計的機械翻訳は、大量の対訳データを用いて学習を行うことで、高精度な翻訳を実現する技術として注目を集めています。この統計的機械翻訳の精度を左右する最も重要な要素の一つが、学習に用いる対訳データの質と量です。
対訳データとは、原文とその翻訳文が対になったデータのことを指します。例えば、日本語の文章とその英語訳がセットになったデータが対訳データの一例です。統計的機械翻訳では、この対訳データを大量に学習することで、原文と翻訳文の対応関係を統計的にモデル化します。対訳データが多ければ多いほど、より多くの表現や文法のパターンを学習できるため、翻訳の精度向上に繋がります。まるで、多くの経験を積むことで、より的確な判断ができるようになる人間の学習過程と似ています。
しかしながら、高品質な対訳データを集めることは容易ではありません。特に、専門用語や稀な表現を含むデータは不足しがちです。医学や法律、工学など、各分野には専門用語が多数存在し、これらの用語を正確に翻訳するためには、専門知識に基づいた対訳データが不可欠です。また、日常会話ではあまり使われない稀な表現も、文学作品やニュース記事などには頻繁に登場します。これらの表現に対応するためにも、幅広いジャンルのテキストから対訳データを収集する必要があります。
近年、インターネットの普及に伴い、様々な言語で書かれたウェブサイトや文書が容易に入手できるようになりました。これにより、対訳データの量は増加傾向にあります。しかし、自動的に収集されたデータには誤訳や不適切な表現が含まれている場合もあり、データの質にはばらつきがあります。そのため、高品質な対訳データを選別する技術や、ノイズとなるデータを排除する技術の開発が重要になっています。質の高い対訳データをより効率的に収集・作成する手法の確立は、今後の機械翻訳技術の発展に大きく貢献すると考えられます。
| 要素 | 説明 | 課題 |
|---|---|---|
| 統計的機械翻訳 | 大量の対訳データを用いて学習し、高精度な翻訳を実現する技術 | 高品質な対訳データの収集が課題 |
| 対訳データ | 原文とその翻訳文が対になったデータ。データの質と量が翻訳精度を左右する。 | 専門用語や稀な表現を含むデータの不足、自動収集データの質のばらつき |
| 高品質な対訳データの必要性 | 専門用語や稀な表現の正確な翻訳、幅広いジャンルのテキストへの対応 | データ収集の難しさ、ノイズとなるデータの混入 |
| 今後の展望 | 高品質な対訳データを選別・作成する技術の開発が重要。効率的な収集・作成手法の確立が機械翻訳技術の発展に貢献。 | – |
機械学習との関連

統計的機械翻訳は、機械学習の応用分野の一つであり、機械学習なくしては成立しません。機械学習とは、計算機が与えられた情報から自動的に学び、将来の予測や判断を行う技術全般を指します。まるで人間が経験から学習するように、計算機も情報から規則性やパターンを見つけ出すことができます。この機械学習の技術が、統計的機械翻訳の根幹を支えているのです。
統計的機械翻訳では、翻訳の正確さを高めるために、大量の対訳データ、つまり原文とその翻訳文の組み合わせから翻訳の確率モデルを学習します。この学習過程で、様々な機械学習の手法が活躍します。例えば、ある単語が原文に出現した時に、訳文でどの単語が対応する可能性が高いかを計算するために、ナイーブベイズ分類器のような分類アルゴリズムが用いられます。また、文全体の繋がりを考慮した翻訳を行うためには、隠れマルコフモデルのような、単語の並び、つまり系列データの解析手法が不可欠です。これ以外にも、サポートベクターマシンなど、様々な機械学習の手法が翻訳モデルの学習に利用されています。
このように、機械学習の手法を用いることで、膨大な対訳データから、人間が手作業で規則を作るよりもはるかに効率的に、翻訳の規則性やパターンを学習することが可能になります。そして、機械学習の技術の進歩は、統計的機械翻訳の性能向上に直結しています。より精度の高い翻訳、より自然な翻訳の実現に向けて、機械学習の研究開発は今後も重要な役割を果たしていくでしょう。さらに、深層学習といった新たな機械学習技術の登場は、統計的機械翻訳の更なる発展を加速させています。深層学習は、人間の脳の神経回路網を模倣した複雑なモデルを用いることで、従来の手法では捉えきれなかった複雑な言語のパターンを学習することを可能にし、翻訳の精度を飛躍的に向上させています。
今後の展望と課題

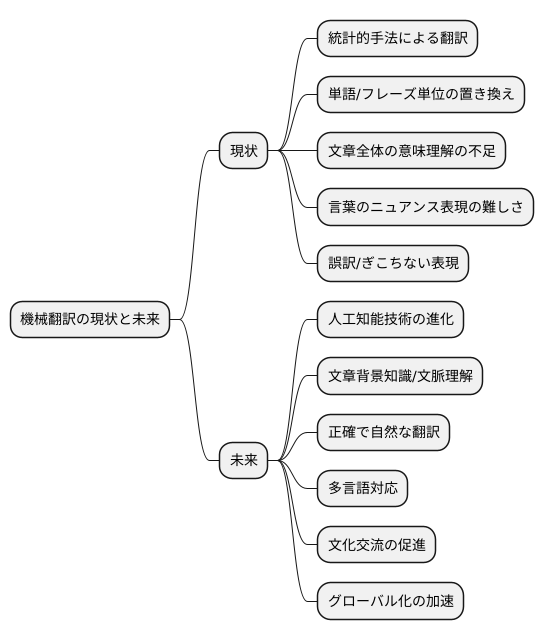
機械翻訳は統計的手法の発展とともに大きく進歩し、様々な場面で活用されるようになってきました。とはいえ、人間が書いた文章のように自然で滑らかな翻訳を作るには、まだまだ改良が必要です。これからは、文章全体の意味や背景まで理解できる翻訳機を作るために、研究開発を進めていく必要があります。
現在の機械翻訳は、単語や短いフレーズを置き換えることで翻訳しています。そのため、文章全体の流れや言葉の真意を捉えるのが苦手です。例えば、同じ言葉でも、使われている場面によって意味が変わる場合があります。こうした言葉の微妙なニュアンスを理解できないため、誤訳やぎこちない表現が出てきてしまうのです。
これからの機械翻訳の鍵は、人工知能技術の進化にあります。人工知能が文章の背景にある知識や文脈を理解できるようになれば、より正確で自然な翻訳が可能になるでしょう。まるで人間が翻訳したかのような、滑らかで分かりやすい文章が作れるようになるはずです。
また、世界には様々な言語が存在するため、より多くの言語に対応できる翻訳技術の開発も重要です。異なる言語を話す人々がスムーズに意思疎通できるようになれば、文化交流が活発になり、世界の繋がりはより一層強まるでしょう。異なる文化や考え方を理解し合うことで、世界はもっと豊かになるはずです。機械翻訳の更なる発展は、グローバル化を加速させ、世界中の人々を繋ぐ架け橋となるでしょう。
翻訳の未来像

言葉の壁がなくなる未来、そんな夢のような話が、現実になろうとしています。それを可能にするのが、統計的機械翻訳です。この技術は、膨大な量の文章データを使って、言葉と言葉の繋がりを学習し、まるで人が訳したかのような自然な翻訳を生み出します。近い将来、この技術はさらに進化し、より正確で自然な翻訳が可能になるでしょう。
これまで翻訳作業には、多くの時間と労力が必要でした。しかし、機械翻訳の精度が向上すれば、人の負担を大幅に軽くすることができます。翻訳家は、より高度な表現やニュアンスの調整といった、機械翻訳がまだ苦手とする分野に集中できるようになるでしょう。また、通訳の世界にも大きな変化が訪れるでしょう。リアルタイム翻訳技術の進歩により、言葉の壁を感じさせない、スムーズなコミュニケーションが実現するかもしれません。国際会議や商談、海外旅行など、さまざまな場面で、言葉の壁に悩むことなく、自由に交流できるようになるでしょう。
さらに、機械翻訳は情報へのアクセス方法も大きく変えるでしょう。世界には、さまざまな言語で書かれた文献や情報があふれています。これらの情報に、誰でも簡単にアクセスできるようになれば、教育や研究の進歩、ビジネスの活性化につながるでしょう。例えば、海外の最新の研究論文をすぐに読めるようになったり、世界中の市場動向をリアルタイムで把握できるようになったりするでしょう。
このように、機械翻訳は世界中の人々をつなぎ、文化交流や経済発展を促進する力を持っています。まさに、世界を一つにする、架け橋となる技術と言えるでしょう。今後の更なる発展に、大きな期待が寄せられています。
| 項目 | 内容 |
|---|---|
| 技術 | 統計的機械翻訳 |
| 仕組み | 膨大な量の文章データを使って、言葉と言葉の繋がりを学習し、まるで人が訳したかのような自然な翻訳を生み出す。 |
| 将来 | より正確で自然な翻訳が可能になる。 |
| 翻訳作業への影響 | 人の負担を軽減、翻訳家は高度な表現やニュアンスの調整といった分野に集中できる。 |
| 通訳への影響 | リアルタイム翻訳技術の進歩により、スムーズなコミュニケーションが実現。 |
| 情報アクセスへの影響 | さまざまな言語で書かれた情報に簡単にアクセスできるようになり、教育や研究の進歩、ビジネスの活性化につながる。 |
| 機械翻訳の役割 | 世界中の人々をつなぎ、文化交流や経済発展を促進する。 |