
教師あり学習:機械学習の基礎

AIを知りたい
先生、「教師あり学習」って、どんなものか教えてください。

AIエンジニア
分かりました。教師あり学習とは、まるで先生が生徒に教えるように、正解が分かっているデータを使ってコンピュータに学習させる方法です。例えば、たくさんの犬と猫の写真を見せて、「これは犬」、「これは猫」と教えていくことで、コンピュータが犬と猫を見分けられるようにする、といった感じです。
AIを知りたい
なるほど。つまり、正解の答えを一緒に見せることで、コンピュータに学習させるのですね。他に例はありますか?
AIエンジニア
そうですね。例えば、過去の気象データ(気温、湿度、風速など)と、雨が降ったか降らなかったかのデータを使って学習させることで、未来の天気を予測するモデルを作ることも教師あり学習の一つです。過去のデータから未来を予測するのも教師あり学習の得意とするところです。
教師あり学習とは。
人工知能にまつわる言葉である「教師あり学習」について説明します。教師あり学習とは、正解がすでに分かっているデータを使って、人工知能のモデルを訓練する方法です。機械学習は大きく分けて、教師あり学習、教師なし学習、強化学習の三種類に分類されます。教師あり学習では、前もって正解を用意し、それらと対応するデータとを組み合わせて使います。これらの組み合わせを使って、データと正解の関連性を示すモデルを学習させます。教師あり学習は、画像認識、機械翻訳、異常検知など、様々な分野で使われています。
機械学習の種類

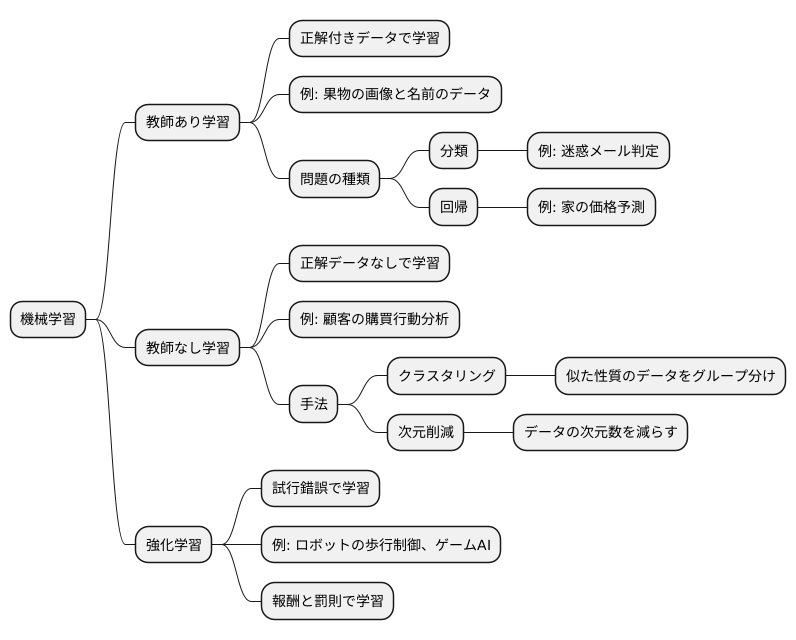
機械学習は、データから自動的に規則やパターンを見つける技術で、大きく三つの種類に分けられます。一つ目は、教師あり学習です。これは、まるで先生から生徒へ教え導くように、正解付きのデータを使って学習を行います。例えば、果物の画像と果物の名前がセットになったデータを使って学習することで、新しい果物の画像を見せられた時に、その果物の名前を正しく予測できるようになります。教師あり学習は、主に分類と回帰の二つの問題に適用されます。分類問題は、データがどのグループに属するかを予測する問題で、例えば、メールが迷惑メールかそうでないかを判断するような場合です。回帰問題は、数値を予測する問題で、例えば、家の価格を予測するような場合です。
二つ目は、教師なし学習です。こちらは、正解データがない状態で、データの中から隠れた構造や特徴を見つけ出す学習方法です。教師なし学習の代表的な例としては、クラスタリングがあります。クラスタリングは、似た性質を持つデータをまとめてグループ分けする手法で、顧客を購買行動に基づいてグループ分けするなど、様々な分野で活用されています。他にも、次元削減という手法も教師なし学習の一つです。次元削減は、データの特徴を損なわずに、データの次元数を減らす手法で、データの可視化や処理の高速化に役立ちます。
三つ目は、強化学習です。これは、試行錯誤を通じて、目的とする行動を学習する方法です。まるで、ゲームをプレイするように、様々な行動を試してみて、その結果に応じて報酬や罰則を受け取り、より多くの報酬を得られる行動を学習していきます。例えば、ロボットの歩行制御やゲームのAIなどに利用されています。ロボットは、転倒すると罰則を受け、うまく歩けると報酬を受けながら、最終的には安定して歩けるように学習していきます。このように、強化学習は、最適な行動を自ら学習していくという特徴を持っています。これらの三つの学習方法は、それぞれ異なる目的やデータの特性に合わせて使い分けられています。
教師あり学習とは

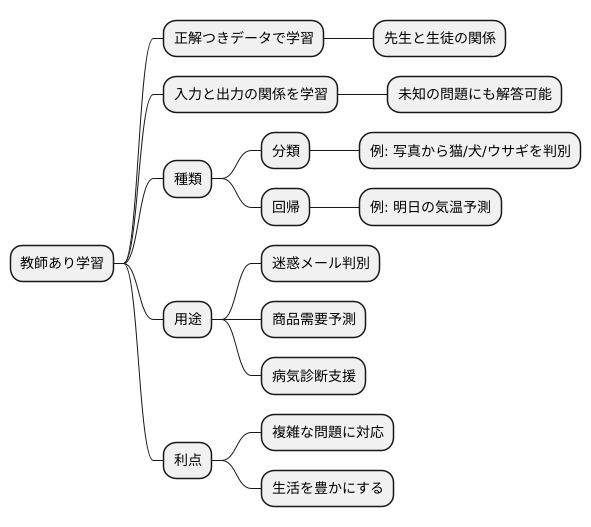
教師あり学習とは、正解のついたデータを使って、機械学習の模型を鍛える方法です。 例えるなら、先生が生徒に答えを教えながら勉強させるように、入力データとその答えとなるデータの組を模型に与えます。
模型は、与えられたデータから、入力と出力の関係を学びます。 たくさんの問題と解答を学ぶことで、問題の特徴と解答の関連性を理解していくのです。この学習を通して、模型は未知の問題が出されたときでも、正しい答えを予想できるようになります。まるで、生徒が先生から教わったことをもとに、新しい問題を解くようにです。
この学習方法は、大きく分けて二つの種類があります。一つは、答えがいくつかの種類に分類されている場合に使われる「分類」です。例えば、写真に写っているものが猫か犬かウサギかを判断するような場合です。もう一つは、答えが数値で表される場合に使われる「回帰」です。例えば、過去の気温データから明日の気温を予想するような場合です。
教師あり学習は、過去のデータから未来を予想するだけでなく、様々な用途で使われています。例えば、迷惑メールの自動判別、商品の需要予測、病気の診断支援など、幅広い分野で活用されています。このように、教師あり学習は、大量のデータから規則性やパターンを見つけ出すことで、様々な課題を解決する強力な道具となっています。教師あり学習を使うことで、複雑な問題にも対応できるようになり、私たちの生活をより豊かにすることが期待されています。
学習の仕組み

学ぶとは何か、その仕組みを紐解いてみましょう。人間が学ぶように、機械も学ぶことができます。その中でも、教師あり学習と呼ばれる方法に着目します。教師あり学習とは、まるで先生に教わる生徒のように、機械にたくさんの例題と解答をセットで与え、そこから規則性や関係性を発見させる学習方法です。
具体的な手順を見てみましょう。まず、機械に学習させたい問題と、その正解となる答えの組み合わせをたくさん用意します。例えば、果物の写真とその果物の名前を組み合わせたデータです。りんごの写真には「りんご」という名前、みかんの写真には「みかん」という名前といった具合です。これらの組み合わせを、機械学習のモデルに与えます。モデルとは、いわば生徒の頭脳にあたる部分です。
モデルは、与えられたデータから、写真の特徴と果物の名前の関係性を理解しようとします。この過程で、モデルは内部のパラメータと呼ばれる数値を調整していきます。パラメータは、モデルが持つ知識や判断基準のようなものです。最初は適当な値に設定されていますが、学習を進めるにつれて、より正確な予測ができるように調整されていきます。
モデルが予測を行う際には、写真の特徴を捉え、学習した関係性に基づいて果物の名前を推測します。この予測と、実際の正解を比較し、その差が小さくなるようにパラメータを調整していきます。この差のことを誤差と呼びます。誤差が小さければ小さいほど、モデルの予測精度が高いことを意味します。
まるで生徒がテストで良い点を取るために繰り返し勉強するように、モデルも誤差を減らすために学習を繰り返します。たくさんの例題と解答を学習することで、モデルは写真の特徴と果物の名前の関係性をより深く理解し、新しい写真を見せても、それが何の果物かを高い精度で予測できるようになります。このようにして、機械は人間のように学習し、賢くなっていくのです。
活用事例

活用事例は多岐に渡り、様々な分野で応用されています。具体例をいくつかご紹介しましょう。まず、画像認識の分野では、教師あり学習を用いることで、画像に写っているものを自動で判別することができます。例えば、たくさんの猫の画像と犬の画像を用意し、それぞれに「猫」「犬」といったラベルを付けます。これらのラベル付き画像を学習データとして用いることで、コンピュータは猫と犬の特徴を学習します。学習が完了すると、未知の画像に対しても、それが猫なのか犬なのかを高い精度で判断できるようになります。これは、自動運転技術や顔認証システムなど、様々な技術に応用されています。
次に、機械翻訳の分野。異なる言語を相互に変換する際にも、教師あり学習が活躍します。例えば、日本語の文章と対応する英語の文章を大量に用意し、これらを学習データとして用います。コンピュータは、日本語と英語の対応関係を学習し、新しい日本語の文章を入力すると、それに対応する英語の文章を生成できるようになります。この技術は、自動翻訳サービスや多言語対応のウェブサイトなど、国際的なコミュニケーションを円滑にするために欠かせないものとなっています。
さらに、異常検知。これは、普段とは異なるデータ、つまり異常なデータを検出する技術です。例えば、工場の機械の稼働データを学習データとして用いることで、機械の故障などの異常を早期に発見することができます。具体的には、正常な状態のデータと異常な状態のデータを用意し、それぞれに「正常」「異常」といったラベルを付けて学習させます。学習が完了すると、新しいデータが「正常」か「異常」かを判断できるようになります。これは、工場の生産性向上や安全性の確保に役立ちます。このように、教師あり学習は、様々な分野で活用され、私たちの生活をより豊かに、便利にしています。
| 分野 | 活用事例 | 説明 | 応用例 |
|---|---|---|---|
| 画像認識 | 画像分類 | 猫や犬の画像にラベルを付けて学習させることで、未知の画像が猫か犬かを判別。 | 自動運転技術、顔認証システム |
| 機械翻訳 | 言語変換 | 日本語と英語の文章のペアを学習データとして、日本語から英語への翻訳を生成。 | 自動翻訳サービス、多言語対応ウェブサイト |
| 異常検知 | 異常データ検出 | 正常なデータと異常なデータにラベルを付けて学習させることで、新しいデータが正常か異常かを判断。 | 工場の生産性向上、安全性の確保 |
教師あり学習の課題

教師あり学習は、人工知能の分野で広く使われている強力な手法です。まるで先生に教わるように、たくさんの例題と解答を使って機械に学習させることで、新しいデータに対しても予測や判断ができるようにします。しかし、この便利な教師あり学習にもいくつかの課題が存在します。
まず、大量の正解データが必要となることが挙げられます。教師あり学習では、入力データとそれに対応する正しい出力データの組をたくさん用意する必要があります。生徒にたくさんの問題と解答を練習させるのと同様に、機械にも多くのデータを与えることで正確な予測ができるようになります。しかし、この正解データの作成には、多くの時間と費用がかかる場合が多く、特に専門的な知識が必要な分野では、データを集めること自体が難しいこともあります。十分な量のデータを集められないと、機械は学習不足に陥り、期待通りの性能を発揮できません。
次に、過学習という問題も起こりやすいです。これは、機械が与えられた学習データに過剰に適応しすぎてしまい、新しいデータに対してうまく対応できなくなる現象です。生徒が教科書の例題だけを完璧に覚えて、応用問題が解けなくなるのと似ています。過学習を防ぐためには、学習データの一部を検証用として取っておき、学習中にモデルの汎化性能を評価する必要があります。また、モデルの複雑さを調整する手法や、学習データにノイズを加えて汎化性能を向上させる手法なども有効です。
さらに、データの質も重要な要素です。学習データに偏りや間違いが含まれていると、機械は誤ったことを学習してしまいます。生徒に間違った解答を教えてしまうと、生徒は間違ったことを覚えてしまうのと同じです。学習データの質を高めるためには、データのクリーニングや前処理といった作業が不可欠です。具体的には、外れ値の除去や欠損値の補完、データの正規化などを行います。これらの作業によって、より正確で信頼性の高い学習データを作成することができます。これらの課題を適切に addressed することで、教師あり学習の効果を最大限に引き出すことができます。
| 課題 | 説明 | 対策 |
|---|---|---|
| 大量の正解データが必要 | 入力データと出力データの組を大量に用意する必要がある。データ作成に時間と費用がかかり、専門知識が必要な場合はデータ収集自体が難しい。データ不足は学習不足に陥り、期待通りの性能を発揮できない原因となる。 | – |
| 過学習 | 学習データに過剰に適応し、新しいデータにうまく対応できない。 | 検証用データを用いた汎化性能評価、モデル複雑度調整、ノイズ付加 |
| データの質 | 偏りや間違いを含むデータで学習すると、誤った学習につながる。 | データクリーニング、前処理(外れ値除去、欠損値補完、データ正規化) |
今後の展望

教師あり学習は、様々な分野での活用が期待される技術であり、今後ますます発展していくと考えられます。特に、近年目覚ましい進歩を遂げている深層学習と組み合わせることで、画像の認識や自然な言葉の処理といった分野で、これまで以上に大きな成果を期待できます。例えば、深層学習を用いた画像認識は、自動運転技術や医療診断などに役立てることができ、自然言語処理は、自動翻訳や文章要約といった分野での応用が期待されます。
今後、より複雑な問題を解決するため、新しい計算方法や模型の開発が重要となります。複雑な事象をより正確に捉え、より高度な予測や判断を行うためには、従来の手法を改良したり、全く新しいアプローチを考案したりする必要があるでしょう。また、学習に用いる情報の不足を解消するための研究も重要です。十分な情報がない状況でも、精度の高い学習を実現する技術が確立されれば、データ収集が困難な分野での活用も期待できます。限られた情報からでも効率的に学習できるような、新しい手法の開発が求められています。
さらに、人工知能がなぜそのような判断を下したのかを理解できるようにする研究も重要です。これは、説明可能な人工知能と呼ばれる研究分野であり、人工知能の判断根拠を明らかにすることで、その信頼性を高めることができます。人工知能がどのように結論に至ったかを理解できれば、その判断の妥当性を評価し、必要に応じて修正することも可能になります。これらの研究が進展することで、教師あり学習はより強力な道具となり、社会の様々な問題解決に貢献していくことが期待されます。例えば、医療分野では病気の早期発見や治療法の開発、製造業では生産効率の向上や品質管理の高度化、金融分野ではリスク管理や投資判断の精緻化など、様々な分野で活用が期待されています。
| 分野 | 活用例 |
|---|---|
| 画像認識 | 自動運転技術、医療診断 |
| 自然言語処理 | 自動翻訳、文章要約 |
| 医療 | 病気の早期発見、治療法の開発 |
| 製造業 | 生産効率の向上、品質管理の高度化 |
| 金融 | リスク管理、投資判断の精緻化 |
| 今後の課題 | 内容 |
|---|---|
| 新しい計算方法やモデルの開発 | 複雑な事象をより正確に捉え、高度な予測や判断を行うため |
| 学習データ不足の解消 | データ収集が困難な分野での活用拡大 |
| 説明可能なAIの開発 | AIの判断根拠を明らかにし、信頼性を高める |