
状態価値関数:未来への道標

AIを知りたい
先生、状態価値関数ってなんですか?難しくてよくわからないです。

AIエンジニア
そうですね、少し難しいですよね。簡単に言うと、状態価値関数とは、ある状況における将来の報酬の予測値のことです。たとえば、迷路でいうと、ゴールに近い場所にいるほど、最終的にゴールにたどり着いて報酬を得られる可能性が高いので、状態価値関数の値は大きくなります。
AIを知りたい
なるほど。ゴールに近いほど値が大きいんですね。ということは、状態価値関数がわかれば、どの行動をとるべきか判断できるってことですか?
AIエンジニア
その通りです。エージェント(AI)は、それぞれの行動をとった後の状態価値関数を予測し、最も高い価値を持つ行動を選択することで、最終的な報酬を最大化しようとします。つまり、状態価値関数はAIが行動を計画するための重要な指標となるのです。
状態価値関数とは。
人工知能の分野で使われる「状態価値関数」という言葉について説明します。強化学習という技術では、最終的に得られる報酬の合計を最大にすることを目指します。そのため、状態価値関数と行動価値関数という考え方が重要になります。状態価値関数は、目標に近いほど値が大きくなるように設計されています。人工知能のエージェントは、この値を参考に次の行動を決めます。
はじめに

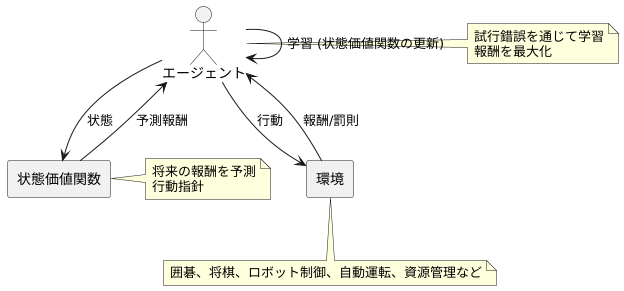
強化学習とは、機械学習の一種であり、試行錯誤を通じて学習を行う枠組みのことです。あたかも人間が様々な経験を通して学習していくように、機械も経験を通して学習していきます。具体的には、学習を行う主体であるエージェントが、ある環境の中で行動し、その結果として得られる報酬を最大化するように学習を進めます。囲碁や将棋などのゲームを例に挙げると、エージェントは盤面の状態を観察し、次の一手を決定します。そして、その一手の結果として勝利に近づけば報酬が与えられ、逆に敗北に近づけば罰則が与えられます。このように、エージェントは報酬と罰則を通して学習し、最適な行動を選択できるようになっていきます。強化学習は、ゲーム以外にも、ロボットの制御や自動運転、資源管理など、様々な分野で応用されています。
この強化学習において、エージェントが最適な行動を選択するために重要な役割を果たすのが、状態価値関数です。状態価値関数は、ある状態において、将来どれだけの報酬が得られるかを予測する指標です。例えば、囲碁で言えば、現在の盤面の状態から、最終的に勝利した場合に得られる報酬を予測します。状態価値関数の値が高い状態は、将来多くの報酬が得られる可能性が高い状態であり、逆に低い状態は、報酬が得られる可能性が低い、あるいは罰則を受ける可能性が高い状態です。エージェントはこの状態価値関数を基に、将来の報酬を最大化するように行動を選択します。つまり、状態価値関数はエージェントの行動指針となる重要な要素です。状態価値関数を正確に推定することが、強化学習の成功にとって不可欠です。そのため、様々な手法が開発され、研究が進められています。
報酬と価値

強化学習とは、機械学習の一種で、試行錯誤を通じて学習を行う方法です。まるで人間が経験から学ぶように、機械も様々な行動を試してみて、その結果得られる報酬を元に、より良い行動を学習していきます。この学習の目的は、エージェントと呼ばれる学習主体が、環境とのやり取りの中で、長期的に得られる報酬を最大にすることです。
エージェントは、ある時点で何らかの行動を取ります。すると、その行動に対して環境から報酬が与えられます。この報酬は、取った行動が良いか悪いかを示す指標となるものです。例えば、迷路を進むロボットを考えると、ゴールに辿り着けば高い報酬が、壁にぶつかったり遠回りすれば低い報酬が与えられるとします。ロボットは、試行錯誤を繰り返す中で、どの行動が高報酬に繋がりやすいかを学習していくのです。
状態価値関数は、強化学習において重要な概念です。これは、ある状態からスタートして、将来にわたって得られる報酬の合計の期待値を表します。言い換えると、ある状態に置かれた時に、将来どれだけの報酬を得られるかを見積もった値です。迷路の例で言えば、ゴールに近い場所の状態は、ゴールから遠い場所の状態よりも、状態価値が高くなります。なぜなら、ゴールに近い場所からは、より少ない手順でゴールに辿り着き、高い報酬を得られる可能性が高いからです。
エージェントは、この状態価値関数を基に行動を選択します。つまり、状態価値の高い状態に遷移できる行動を優先的に選択するようになります。このようにして、エージェントは環境との相互作用を通して学習し、より多くの報酬を得られる最適な行動を習得していくのです。
状態価値関数の計算

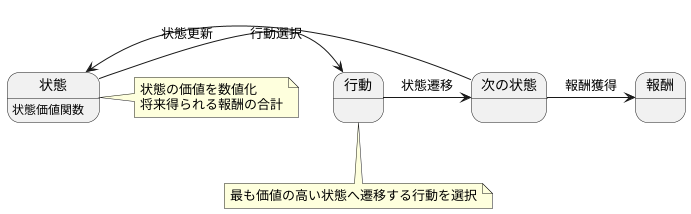
状態価値関数は、ある状態にいることがどれほど良いかを数値で表したものです。この値を計算するためには、ベルマン方程式と呼ばれる特別な式を使います。この式は、現在の状態の価値と、次に起こりうる状態の価値、そしてその時に得られる報酬の関係を示す漸化式です。簡単に言うと、今の状態の価値は、次の状態の価値と、今の状態で得られる報酬を組み合わせて計算するということです。
具体的には、まず次の状態の価値に割引率という値を掛けます。この割引率は、0から1の間の値で、将来得られる報酬をどれくらい重視するかを決める重要な要素です。割引率が小さい場合は、将来の報酬よりも目の前の報酬を重視することになり、逆に割引率が大きい場合は、将来の報酬を重視することになります。例えば、割引率が0に近い場合は、「今すぐ飴玉を1つもらう」ことを、「1年後にもらえる飴玉を10個」よりも高く評価します。逆に割引率が1に近い場合は、「1年後にもらえる飴玉を10個」を、「今すぐ飴玉を1つもらう」よりも高く評価します。
次に、この割引率を掛けた値と、現在の状態で得られる報酬を足し合わせます。これが現在の状態の価値になります。つまり、ベルマン方程式は、「現在の状態の価値 = 次の状態の価値 × 割引率 + 現在の報酬」という形で表すことができます。この計算を繰り返し行うことで、最終的に全ての状態の価値を正確に求めることができます。このように、ベルマン方程式と割引率は、状態価値関数を計算する上で重要な役割を果たしています。
状態価値関数の活用

状態価値関数は、強化学習においてある状態の価値を数値で表す重要な役割を担います。この数値は、その状態から開始して以降、将来にわたって得られると期待される報酬の合計を表します。言ってみれば、その状態がどれほど良い状態かを数値化したものです。
例えば、迷路を解くロボットを想像してみてください。このロボットにとって、迷路の出口に近い状態は、出口から遠い状態よりも価値が高いはずです。なぜなら、出口に近い状態からは、より少ない手順で出口に到達し、報酬を得られる可能性が高いからです。状態価値関数は、まさにこの「状態の良さ」を数値で表現します。
この状態価値関数を用いて、ロボットは行動を選択します。各行動によって次の状態が決まり、それぞれの次の状態には対応する価値が割り当てられています。ロボットは、可能な行動の中から、最も価値の高い状態へ遷移する行動を選択します。つまり、将来得られる報酬の合計が最大となるように行動するのです。
状態価値関数が正確であれば、ロボットは常に最適な行動を選択し、迷路を最短経路で解くことができます。しかし、実際には状態価値関数は未知であることが多く、試行錯誤を通して学習する必要があります。強化学習の様々な手法は、この状態価値関数を効率的に学習するための方法を提供します。学習が進むにつれて、ロボットはより良い行動を選択できるようになり、最終的には最適な行動戦略を獲得します。このように、状態価値関数は強化学習の中核を担う重要な概念と言えるでしょう。
行動価値関数との関係

{行動価値関数とは、ある状況で特定の行動をとった時に、将来にわたってどれだけの報酬が得られるかを予測した値}です。これは、状態価値関数と並んで強化学習における重要な概念です。
状態価値関数は、ある状況に置かれた時の価値を測るものです。例えば、迷路で特定のマスに到達した時の価値を考えます。このマスからゴールまでたどり着くまでに、どれだけの報酬を得られるか、あるいはどれだけの罰則を受けるかを予測したものが状態価値関数です。
一方、行動価値関数は、そのマスで特定の行動、例えば「上へ移動する」「下へ移動する」「右へ移動する」「左へ移動する」といった行動をとった時の価値を測ります。それぞれの行動によって、次に到達するマスが変わり、最終的に得られる報酬や罰則も変わってきます。行動価値関数は、それぞれの行動について、将来にわたって得られる報酬の期待値を計算したものです。
状態価値関数と行動価値関数は密接に関係しています。ある状況での状態価値関数は、その状況で可能な全ての行動の行動価値関数の平均値として計算できます。例えば、迷路のあるマスでの状態価値関数は、そのマスで「上へ移動する」「下へ移動する」「右へ移動する」「左へ移動する」といった全ての行動の行動価値関数の平均値として計算できます。
強化学習では、状態価値関数と行動価値関数を用いて、最適な行動戦略を学習します。それぞれの状況で、最も高い行動価値関数を持つ行動を選択することで、最終的に最も多くの報酬を得られるように学習を進めます。これらの関数は、試行錯誤を通じて徐々に正確な値に近づいていくことで、より良い行動選択を可能にします。
| 項目 | 説明 | 例 |
|---|---|---|
| 行動価値関数 | ある状況で特定の行動をとった時に、将来にわたってどれだけの報酬が得られるかを予測した値 | 迷路のあるマスで「上へ移動する」行動をとった時の、ゴール到達までの報酬の期待値 |
| 状態価値関数 | ある状況に置かれた時の価値を測るもの。 | 迷路の特定のマスに到達した時の、ゴール到達までの報酬の期待値 |
| 両者の関係 | 状態価値関数は、その状況で可能な全ての行動の行動価値関数の平均値として計算できる。 | 迷路のあるマスでの状態価値関数は、そのマスで可能な4方向への移動の行動価値関数の平均値 |
| 強化学習での利用 | 状態価値関数と行動価値関数を用いて、最適な行動戦略を学習する。最も高い行動価値関数を持つ行動を選択することで、最終的に最も多くの報酬を得られるように学習を進める。 | 迷路の各マスで、最も高い行動価値関数を持つ方向へ移動することで、ゴールを目指す。 |
まとめ

状態価値関数は、強化学習において学習主体が取るべき行動の良し悪しを評価する重要な指標です。これは、ある状態に置かれた学習主体が、その後どのような行動を取るかによって、最終的に得られるであろう報酬の合計値の期待値を表しています。つまり、状態価値関数は、現在の状態が将来どれだけの報酬をもたらすかを予測する役割を担っているのです。
例えば、迷路を解くロボットを想像してみましょう。このロボットにとって、迷路の各地点が「状態」にあたり、各地点における状態価値関数の値は、その地点からゴールまで到達するまでに得られる報酬の期待値を表します。ゴールに近い地点の状態価値関数は高く、壁に囲まれた袋小路のような地点の状態価値関数は低くなります。
学習主体は、この状態価値関数を基に行動を選択します。より高い報酬を得るためには、より高い状態価値関数を持つ状態へと移動しようとします。迷路のロボットであれば、状態価値関数の高い地点、つまりゴールに近い地点へと移動することで、最終的にゴールに到達し、報酬を得ることができます。
状態価値関数の算出方法は様々ですが、一般的には、学習主体と環境との相互作用を通じて繰り返し計算・更新されます。学習主体は、環境の中で行動し、その結果得られた報酬と次の状態の情報を使って、状態価値関数を修正していきます。この過程を繰り返すことで、状態価値関数はより正確な値へと収束していきます。
状態価値関数を理解することは、強化学習の仕組みを理解する上で非常に重要です。多くの強化学習アルゴリズムは、この状態価値関数を最大化するように学習主体の行動戦略を最適化していきます。今後の強化学習の発展においても、状態価値関数は中心的な役割を果たしていくと考えられます。
| 項目 | 説明 |
|---|---|
| 状態価値関数 | 強化学習において、ある状態の価値を評価する関数。将来得られる報酬の合計値の期待値を表す。 |
| 役割 | 現在の状態が将来どれだけの報酬をもたらすかを予測する。 |
| 例:迷路ロボット | 迷路の各地点が「状態」。ゴールに近い地点の状態価値関数は高く、袋小路のような地点は低い。 |
| 学習主体の行動選択 | より高い状態価値関数を持つ状態へと移動しようと試みる。 |
| 算出方法 | 学習主体と環境との相互作用を通じて繰り返し計算・更新される。 |
| 強化学習との関係 | 多くの強化学習アルゴリズムは、状態価値関数を最大化するように学習主体の行動戦略を最適化していく。 |