
音声認識:声から文字へ

AIを知りたい
先生、音声認識って人の声を文字にする技術ですよね?でも、どうやって機械が人の声を理解できるのか不思議です。

AIエンジニア
いい質問だね。機械は音声を波の形で捉え、それを様々な周波数の音の組み合わせとして分析するんだ。そして、たくさんの音声データと文字の組み合わせを学習することで、どの音の組み合わせがどの文字や単語に対応するのかを覚えていくんだよ。
AIを知りたい
たくさんの音声データで学習するんですね!でも、方言とか、話すスピードが違うと認識できないこともあるんじゃないですか?
AIエンジニア
その通り!方言や話すスピード、周りの騒音などは音声認識の精度に影響する。だから、より多くの様々な音声データを学習させることで、精度を向上させる研究が日々続けられているんだよ。
音声認識とは。
人工知能に関係する言葉である「音声認識」について説明します。「音声認識」とは、人の声を理解して、文字に変換する技術のことです。例えば、SiriやGoogle音声アシスタントに話しかけると、それを文字に変換する機能が「音声認識」です。
音声認識とは

音声認識とは、人が話す言葉を機械が理解し、文字情報に変換する技術のことです。まるで人が耳で音を聞き、脳で言葉として認識する過程と似ています。機械は、集音装置を通して集めた音声情報を分析し、文字列に変えます。この技術は、私たちの日常生活で使われている様々な機器や作業で活躍しています。
例えば、携帯電話に話しかけるだけで、文字のやり取りを送信したり、調べ物をしたり、家電を操作したりできます。これらはすべて音声認識技術のおかげです。また、音声認識は、会議の内容を文字に起こす議事録作成や、お話を読み上げる読み上げ機など、様々な場面で使われています。さらに、視覚に障害がある方の支援機器としても活用され、日常生活を支えています。
音声認識の仕組みは、大きく分けて「音声入力」「特徴抽出」「音響モデル」「言語モデル」「音声出力」の五つの段階に分けられます。まず「音声入力」では、集音装置を通して音声を取り込みます。次に「特徴抽出」では、取り込んだ音声データから、周波数や音の強弱といった特徴を抽出します。そして「音響モデル」で、抽出された特徴と、あらかじめ学習させた音声データとを照合し、音声を認識します。「言語モデル」では、単語同士の関係性や出現頻度などを考慮し、より自然で正確な文章になるよう認識結果を補正します。最後に「音声出力」では、認識した結果を文字列として出力します。
音声認識技術は、機械学習や深層学習の発展により、近年急速に進歩しています。より多くの音声データを学習させることで、認識精度が向上し、雑音の中でも音声を正確に認識できるようになってきています。人間と機械の言葉によるやり取りをより自然なものにするために、音声認識技術はこれからも進化し続け、私たちの生活をより便利で豊かにしていくでしょう。
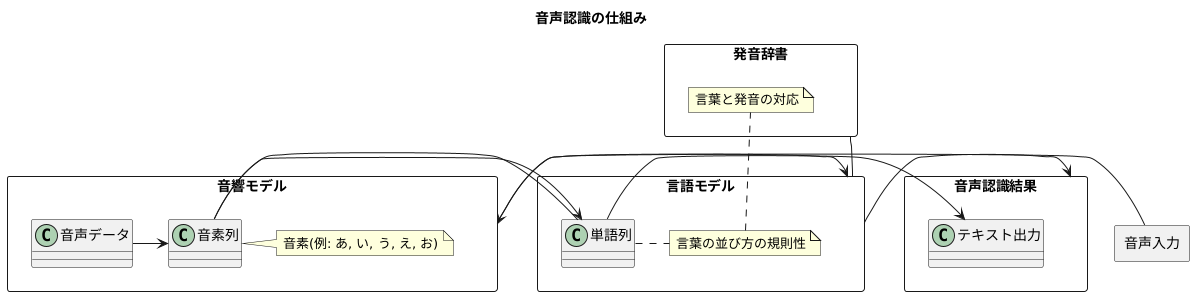
音声認識の仕組み

人間が言葉を聞き取って理解するように、機械も音声を認識して文字に変換する技術があります。これを音声認識と呼びますが、一体どのような仕組みで音声を認識しているのでしょうか。音声認識は、主に三つの重要な要素を巧みに組み合わせて実現されています。
まず一つ目は音響モデルです。これは、マイクから入力された音声データを分析し、言葉の最小単位である音素へと変換する役割を担います。「あいうえお」や子音などが音素にあたり、音響モデルは波形や周波数といった音声の特徴を捉え、どの音素に該当するかを判断します。まるで人間の耳が音の違いを聞き分けるように、音響モデルは音声データから音素を識別します。
二つ目は言語モデルです。これは、ある言葉の次にどの言葉が続くのかといった、言葉の並び方の規則性を確率で表したものです。例えば「おはようございます」という言葉の次に「こんにちは」という言葉が続くことは稀であり、「ございます」という言葉が続く可能性が高いといった、自然な言葉の流れを学習しています。言語モデルは、音響モデルで得られた音素列を、より自然で意味の通る言葉の並びへと修正する役割を担います。
三つ目は発音辞書です。これは、言葉とその発音を対応させた辞書です。例えば「こんにちは」という言葉を「konnichiwa」という発音記号に対応させて記録しています。発音辞書は、音響モデルで得られた音素列と、言語モデルで予測された言葉の候補を結びつける役割を担います。
音声認識は、これら三つの要素を組み合わせ、入力された音声データがどの言葉の列に最も近いかを確率的に計算することで実現されます。まず、音響モデルが音声データを音素列に変換します。次に、言語モデルと発音辞書を用いて、その音素列から最も確率の高い言葉の列を選び出します。この複雑な処理が、驚くほど速く行われることで、私たちが話した言葉をほぼ同時に文字として見ることができるのです。
音声認識の活用例

音声認識は、私たちの暮らしの様々な場面で役立っています。身近な例では、携帯電話の音声案内があります。音声認識によって私たちの言葉を理解し、電話をかけたり、予定を登録したり、様々な作業を代行してくれます。また、文字を打ち込むのが苦手な人や、手が離せない状況でも、音声入力を使って簡単に文章を作成できます。キーボードを使うよりも素早く、簡単に文章を作成できるので、多くの人が利用しています。
ビジネスの場でも、音声認識は広く活用されています。例えば、お客様相談センターでは、音声認識による自動対応システムが導入されています。このシステムはお客様の声を認識し、適切な回答を自動的に返してくれるため、対応時間の短縮や人員削減に繋がります。また、会議の内容を文字に起こす議事録作成も、音声認識によって自動化が進んでいます。これまでは、人が時間をかけて行っていた作業が、音声認識によって自動化され、時間と手間を大幅に削減できます。さらに、異なる言葉を話す人同士のコミュニケーションを支援するリアルタイム翻訳も、音声認識技術の進歩によって実現しました。リアルタイムで音声を認識し、異なる言葉に翻訳することで、言葉の壁を越えた円滑なコミュニケーションが可能になります。
このように音声認識は、私たちの暮らしを便利にするだけでなく、仕事の効率も大幅に上げてくれます。今後も技術開発が進むことで、さらに多くの分野での活用が期待され、私たちの生活はより豊かになっていくでしょう。
| 場面 | 活用例 | メリット |
|---|---|---|
| 日常生活 | 携帯電話の音声案内、音声入力 | 電話操作、予定登録、文章作成の効率化 |
| ビジネス | お客様相談センターの自動対応、議事録作成、リアルタイム翻訳 | 対応時間短縮、人員削減、作業の自動化、円滑なコミュニケーション |
音声認識の課題と展望

音声認識は、人間の声をコンピュータが理解するための技術であり、近年目覚ましい発展を遂げています。私たちの暮らしの中でも、スマートフォンやスマートスピーカーなど、音声認識を利用した機器が急速に普及しています。しかし、完璧な音声認識の実現には、まだいくつかの壁があります。
まず、騒がしい環境での認識精度の向上が課題です。街中や駅など、周囲の音が多い場所では、人の声が雑音に埋もれてしまい、正確に認識することが難しい場合があります。周りの音を消し、聞きたい声だけをクリアに取り出す技術の向上が求められています。
次に、方言や訛りへの対応も重要な課題です。日本語には様々な方言があり、同じ言葉でも発音が大きく異なる場合があります。標準語以外の発音に対応することで、より多くの人が音声認識技術の恩恵を受けることができるようになります。音声認識システムが、多様な話し方を学習し、理解できるようになる必要があります。
さらに、複数の人が同時に話している状況での認識も難しい問題です。会議やパーティーなど、複数の人が同時に話す場面では、それぞれの声を分離し、個別に認識する必要があります。誰が何を話しているのかを正確に判別する技術の開発が求められます。
これらの課題を解決するために、深層学習といった技術革新が期待されています。大量の音声データを学習させることで、コンピュータは人間の声の特徴をより深く理解し、複雑な状況にも対応できるようになると考えられています。
将来的には、まるで人間と話しているかのような自然な音声対話が可能になるでしょう。コンピュータが私たちの言葉を理解するだけでなく、私たちの意図や感情まで汲み取ってくれるかもしれません。このような高度な音声認識技術は、私たちの生活をより豊かで便利なものへと変えていくでしょう。例えば、家事や仕事の効率化、高齢者や障害者の支援、より自然なコミュニケーションの実現など、様々な分野での活用が期待されています。音声認識技術は、人とコンピュータの垣根を取り払い、より円滑なコミュニケーションを実現するための鍵となる技術と言えるでしょう。
| 課題 | 詳細 | 解決策 |
|---|---|---|
| 騒音環境での認識精度 | 街中や駅など騒音が多い場所では、人の声が雑音に埋もれてしまい正確に認識することが難しい。 | 周りの音を消し、聞きたい声だけをクリアに取り出す技術の向上 |
| 方言・訛りへの対応 | 日本語には様々な方言があり、同じ言葉でも発音が大きく異なるため、標準語以外の発音に対応が必要。 | 音声認識システムが多様な話し方を学習し、理解できるようになる必要がある。 |
| 複数人同時発話時の認識 | 会議やパーティーなど、複数の人が同時に話す場面では、それぞれの声を分離し、個別に認識する必要がある。 | 誰が何を話しているのかを正確に判別する技術の開発 |
| 全般 | 上記課題の解決 | 深層学習による大量の音声データ学習により、複雑な状況にも対応できるようになる。 |
音声認識の未来

話し言葉を機械が理解する技術、音声認識は、目覚ましい発展を遂げており、私たちの未来を大きく変える可能性を秘めています。まるで魔法のように、声で機械を操る世界が、すぐそこまで来ていると言えるでしょう。
家電製品の操作も、音声で行えるようになるでしょう。例えば、照明の明るさを声で調節したり、テレビのチャンネルを切り替えたり、エアコンの温度を設定したりすることが、当たり前になるかもしれません。家の中のあらゆる機器が、私たちの言葉に耳を傾け、反応してくれるようになるのです。また、自動車の運転中も、音声でナビゲーションや音楽の操作を行うことで、安全性を高めることができるでしょう。ハンドルから手を離すことなく、様々な操作ができるようになるため、運転に集中することができます。
言葉の壁を越えたコミュニケーションも、音声認識技術によって実現するでしょう。高度なリアルタイム翻訳技術と組み合わせることで、異なる言葉を話す人同士が、まるで同じ言葉を話しているかのようにスムーズに会話できるようになるでしょう。これにより、国際的な交流が促進され、様々な文化への理解が深まることが期待されます。
さらに、音声認識技術は、私たちの健康管理にも役立つ可能性があります。個人の音声データから、感情や健康状態を分析する技術が開発されれば、病気の早期発見や予防に繋がるかもしれません。例えば、声の変化から風邪の兆候を察知したり、精神的なストレスレベルを把握したりすることができるようになるかもしれません。また、高齢者の見守りにも役立ち、体調の急変をいち早く家族や医療機関に知らせることで、迅速な対応が可能になります。
音声認識技術は、私たちの生活をより便利で豊かにするだけでなく、様々な分野での新たな仕事やサービスを生み出す可能性を秘めています。音声認識技術を活用した革新的な製品やサービスが次々と登場し、私たちの社会を大きく変えていくことでしょう。
| 分野 | 音声認識技術の活用例 | メリット |
|---|---|---|
| 家電操作 | 照明の明るさ調節、テレビのチャンネル切り替え、エアコンの温度設定など | 声で操作できるため便利 |
| 自動車運転 | ナビゲーション、音楽操作など | 安全性の向上、運転への集中 |
| 国際交流 | リアルタイム翻訳 | 言葉の壁を越えたコミュニケーション、文化理解の促進 |
| 健康管理 | 感情・健康状態分析、病気の早期発見・予防、高齢者の見守り | 健康管理の向上、迅速な対応 |