
半教師あり学習:ラベル不足解消の鍵

AIを知りたい
先生、『半教師あり学習』ってどういう意味ですか?

AIエンジニア
簡単に言うと、少しのお手本とたくさんのお手本がないデータを使って学習する方法だよ。 例えば、犬の画像が少しだけあって、それには『犬』という名前がつけてある。そして、名前のない犬の画像がたくさんあるとする。半教師あり学習では、この少ない名前付き画像とたくさんの名前なし画像を使って、コンピュータに犬の画像を認識させるんだ。
AIを知りたい
名前のない画像も使うんですか?どうしてですか?
AIエンジニア
名前をつけるのは大変だからね。名前のない画像も使うことで、少ないお手本でもコンピュータは多くのことを学べるんだ。名前付きの画像で特徴を学び、それを名前なしの画像にも当てはめていくことで、より多くのデータから学習できるんだよ。
半教師あり学習とは。
人工知能の分野で使われる『半教師あり学習』という言葉について説明します。半教師あり学習とは、少しだけ答えのついたデータを使って、たくさんの答えのないデータをうまく学習させる方法のことです。
半教師あり学習とは

機械学習という技術は、大量の情報を元に学習し、その能力を高めていく仕組みです。この技術を使うことで、例えば大量の画像データから猫を認識する、大量の音声データから人の言葉を理解するといったことが可能になります。しかし、多くの機械学習では、教師あり学習という方法が使われています。これは、それぞれの情報に「正解」を付与する必要がある学習方法です。例えば、猫の画像には「猫」という正解、人の声には「こんにちは」といった正解を一つ一つ対応させる必要があります。この正解のことをラベルと呼びます。
しかし、このラベル付け作業は非常に手間がかかります。大量の画像や音声に一つ一つラベルを付けていくのは、大変な時間と労力が必要となる作業です。そこで注目されているのが、半教師あり学習です。これは、ラベル付きの情報とラベルなしの情報を組み合わせて学習する方法です。ラベル付きの情報は少量だけ用意し、ラベルのない大量の情報を追加で学習に利用します。
半教師あり学習の利点は、ラベル付けのコストを削減できることです。ラベル付きの情報は少量で済むため、ラベル付けにかかる時間と労力を大幅に減らすことができます。そして、ラベルなしの大量の情報を利用することで、学習の精度を高めることが期待できます。例えば、少量の猫の画像とラベル、そして大量のラベルなしの猫の画像を学習に使うことで、猫の特徴をより深く理解し、猫をより正確に認識できるようになる可能性があります。このように、半教師あり学習は、限られた資源でより効果的な学習を実現する、有望な技術と言えるでしょう。
| 学習方法 | 説明 | 利点 | 欠点 |
|---|---|---|---|
| 教師あり学習 | 全てのデータにラベル(正解)を付与して学習する。 | 学習精度が高い。 | ラベル付けに膨大なコストがかかる。 |
| 半教師あり学習 | ラベル付きデータとラベルなしデータを組み合わせて学習する。 | ラベル付けのコストを削減できる。ラベルなしデータも活用して学習精度を高めることができる。 | 教師あり学習に比べて精度が劣る場合がある。 |
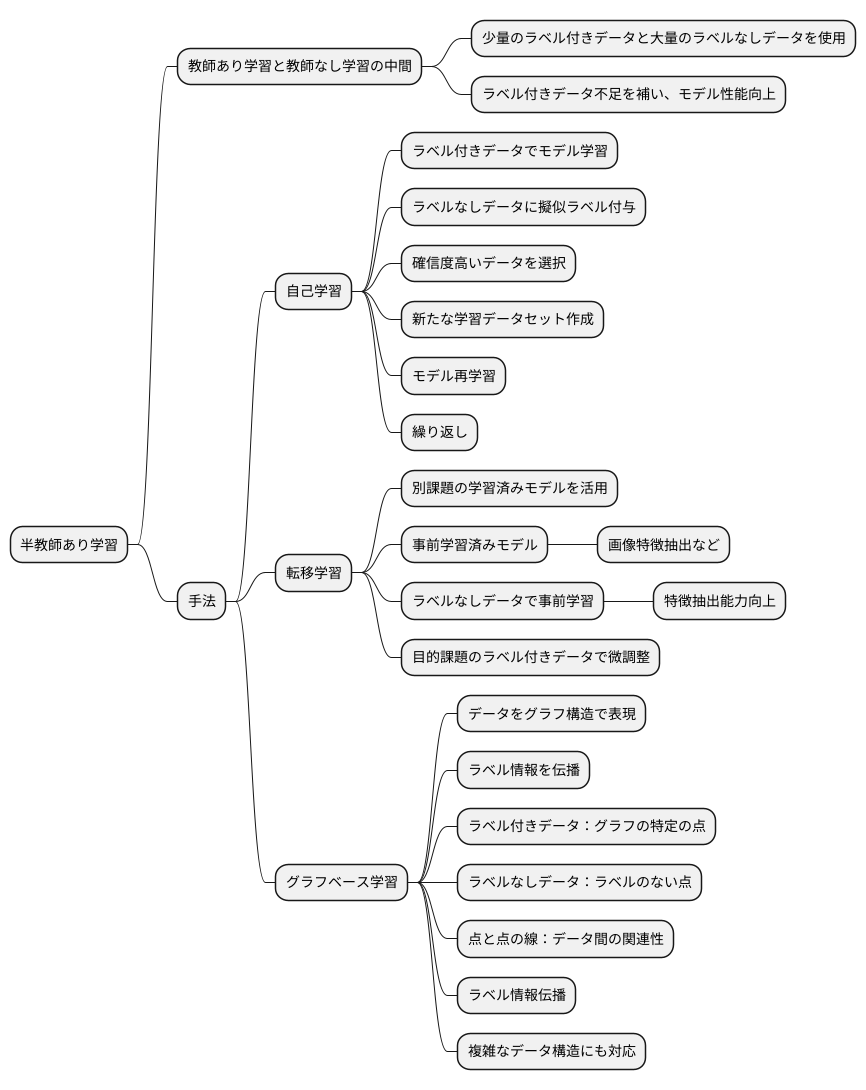
半教師あり学習の種類

教師あり学習と教師なし学習の中間に位置する半教師あり学習は、少量のラベル付きデータと大量のラベルなしデータを用いて学習を行う手法です。限られたラベル付きデータしか入手できない場合に、学習データの不足を補い、モデルの性能向上を期待できます。半教師あり学習には様々な手法が存在しますが、大きく自己学習、転移学習、グラフベース学習の3種類に分類できます。
自己学習は、ラベル付きデータを用いてモデルを学習し、そのモデルを使ってラベルなしデータに擬似的なラベルを付与する手法です。まず、ラベル付きデータで訓練したモデルを用いて、ラベルなしデータのそれぞれにラベルを予測します。次に、予測結果の確信度が高いデータ、つまりモデルが「このラベルで間違いない」と判断したデータを選び出します。そして、これらのデータと予測されたラベルを、元のラベル付きデータに加えて新たな学習データセットを作成します。この新たなデータセットを用いてモデルを再学習することで、より多くのデータで学習した、精度の高いモデルを得ることができます。この一連の流れを繰り返し行うことで、ラベルなしデータを有効活用し、モデルの性能を向上させることが期待できます。
転移学習は、既に別の課題で学習済みのモデルを、現在の課題に活用する手法です。例えば、大量の画像データで学習済みの画像認識モデルを、手元の少量のラベル付き医療画像データで再学習することで、医療画像の診断支援モデルを構築できます。事前に学習済みのモデルは、画像の特徴抽出など、多くの課題に共通する基礎的な部分を既に学習しているため、少量のラベル付きデータでも高い性能を発揮できる場合があります。ラベルなしデータを大量に用意できれば、それを用いた事前学習も可能です。まず、ラベルなしデータでモデルを事前学習し、特徴抽出能力を高めます。その後、目的の課題のラベル付きデータでモデルを微調整することで、少ないラベル付きデータでも高い性能が期待できます。
グラフベース学習は、データを点と線で結んだグラフ構造で表現し、ラベル情報を伝播させることでラベルなしデータにもラベルを付与する手法です。ラベル付きデータはグラフの特定の点に相当し、ラベルなしデータはラベルの付いていない点に相当します。点と点を結ぶ線はデータ間の関連性を表します。学習の過程で、ラベル付きデータのラベル情報は、線で繋がった点を伝って、徐々にラベルなしデータへと広がっていきます。このように、データ間の関係性を考慮した学習が可能であるため、複雑なデータ構造にも対応できます。ラベル付きデータのラベルが、繋がりの強いデータへ的確に伝播していくことで、高精度な予測が可能となります。
半教師あり学習の利点

半教師あり学習は、教師あり学習と教師なし学習の長所を組み合わせた手法で、近年注目を集めています。その最大の利点は、学習データへのラベル付けにかかる費用と時間を大幅に削減できることです。機械学習モデルの訓練には、大量のデータが必要となりますが、すべてのデータにラベルを付けるのは大変な手間と費用がかかります。例えば、画像認識のタスクでは、一枚一枚の画像に写っている物体を人間が識別してラベルを付ける必要があり、膨大な作業量となるでしょう。半教師あり学習では、ラベル付きデータに加えて、ラベルのないデータも活用することで、このラベル付け作業の負担を軽減することができます。
また、半教師あり学習は、限られた量のラベル付きデータしか入手できない場合でも、モデルの性能向上に貢献します。ラベル付きデータが少ないと、モデルはデータの特徴を十分に学習できず、未知のデータに対する予測精度が低くなる可能性があります。しかし、ラベルのないデータを追加で利用することで、データ全体の分布や隠れた構造をより深く理解し、より高い汎化性能を持つモデルを構築できます。これは、ラベル付きデータだけでは学習が不十分な場合でも、ラベルのないデータが補助的な役割を果たし、モデルの学習を助けるためです。
さらに、データの収集が難しい分野、例えば医療診断や希少種の生態調査などにおいても、半教師あり学習は有効な手法となります。これらの分野では、必要なデータを十分な量集めることが困難な場合が多く、高価な機材や専門家の知識が必要となることも少なくありません。このような状況下で、少量のラベル付きデータと大量のラベルのないデータを組み合わせる半教師あり学習は、限られた資源を有効活用し、一定の成果を上げるための強力な道具となるでしょう。
| 半教師あり学習の利点 | 詳細 |
|---|---|
| ラベル付け費用と時間の削減 | ラベル付きデータとラベルなしデータを併用することで、ラベル付け作業の負担を軽減。大量のデータへのラベル付けが不要になるため、費用と時間を大幅に削減。 |
| 限られたラベル付きデータでの性能向上 | ラベル付きデータが少ない場合でも、ラベルなしデータを利用することでデータ全体の分布や隠れた構造を学習。モデルの汎化性能を向上させ、未知データへの予測精度を高める。 |
| データ収集が難しい分野での有効性 | 医療診断や希少種の生態調査など、データ収集が困難な分野でも少量のラベル付きデータと大量のラベルなしデータを活用することで、有効な成果を期待できる。 |
半教師あり学習の応用例

半教師あり学習は、限られたラベル付きデータと大量のラベルなしデータの両方を使って学習を行う機械学習の手法で、様々な分野で応用されています。ラベル付きデータは教師あり学習、ラベルなしデータは教師なし学習として同時に学習を進めることで、ラベル付きデータが少ない場合でも、高精度なモデルを構築できます。
画像認識の分野では、特に効果を発揮します。例えば、膨大な数の画像の中から猫を認識するモデルを作りたいとします。全ての画像に「猫」か「猫ではない」というラベルを付けるのは大変な作業です。しかし、半教師あり学習を使えば、少量の猫の画像とラベル、そしてラベルのない大量の画像を使って学習できます。ラベルのない画像は、猫の様々な角度や種類、背景などを学習するのに役立ち、少ないラベル付きデータでも高精度な猫認識モデルを構築できます。
自然言語処理の分野でも、半教師あり学習は力を発揮します。例えば、文章の感情分析をしたい場合、大量の文章データを集めることは容易ですが、全ての文章に「肯定的」「否定的」などのラベルを付けるのは困難です。そこで、少量のラベル付き文章データと大量のラベルなし文章データを使って学習することで、ラベル付けの手間を大幅に削減しつつ、高精度な感情分析モデルを構築できます。これは、ラベルなしデータから言葉遣いや文脈などの情報を学習し、ラベル付きデータの情報を補完できるためです。
音声認識においても、半教師あり学習は有効です。音声データは、雑音や話者の違いなど、非常に多様な要素を含むため、ラベル付けは困難な作業となります。しかし、半教師あり学習を用いることで、少量の音声データとラベル、そしてラベルなしの大量の音声データから、雑音に強く、話者の違いにも対応できる高精度な音声認識システムを構築できます。ラベルなしデータから、様々な音声パターンを学習することで、認識精度が向上します。
| 分野 | 課題例 | 半教師あり学習のメリット |
|---|---|---|
| 画像認識 | 猫の認識 |
|
| 自然言語処理 | 文章の感情分析 |
|
| 音声認識 | 音声認識システム構築 |
|
半教師あり学習の課題

半教師あり学習は、ラベル付きデータとラベルなしデータを組み合わせて学習を行う手法で、ラベル付きデータの不足を補いながら、モデルの性能向上を目指します。多くの利点がある一方で、いくつかの課題も存在します。
まず、ラベルなしデータの質が学習結果に大きな影響を与えます。ラベルなしデータにノイズが多く含まれていたり、ラベル付きデータとの分布が大きく異なっていたりする場合は、モデルが誤った学習をしてしまい、性能低下につながることがあります。例えば、手書き数字認識のモデルを学習させる際に、ラベル付きデータは綺麗に書かれた数字のみで構成されている一方、ラベルなしデータに乱雑に書かれた数字や記号が多く含まれていると、モデルは数字の特徴をうまく捉えられず、認識精度が低くなってしまう可能性があります。
次に、モデルの仮定とデータの真の分布とのずれも課題となります。半教師あり学習では、モデルの仮定に基づいてラベルなしデータの情報を取り込みますが、この仮定が実際のデータの分布と合致していない場合、誤った方向に学習が進んでしまいます。例えば、データが複数のグループに分かれているにもかかわらず、モデルが単一のグループとしてデータを扱うと、グループごとの特徴を捉えきれず、予測精度が低下する可能性があります。
さらに、モデルの評価も難しい点です。教師あり学習のように、ラベル付きデータを用いて直接予測精度を測ることができません。ラベルなしデータに対する予測は確実ではないため、間接的な指標を用いてモデルの性能を推定する必要があります。そのため、どのような指標を用いて評価を行うかが重要となり、目的に合わせた適切な指標を選択する必要があります。
これらの課題を克服するためには、データの前処理を丁寧に行い、ノイズの除去やラベル付きデータとの分布の調整を行うことが重要です。また、適切なモデルと学習手法を選択し、パラメータを調整することも必要です。そして、複数の評価指標を組み合わせてモデルの性能を多角的に評価することで、より信頼性の高いモデルを構築することが可能になります。
| 課題 | 説明 | 例 |
|---|---|---|
| ラベルなしデータの質 | ラベルなしデータにノイズが多い、またはラベル付きデータとの分布が大きく異なる場合、モデルが誤った学習をして性能低下につながる。 | 手書き数字認識で、ラベル付きデータは綺麗に書かれた数字だが、ラベルなしデータに乱雑な数字や記号が多いと認識精度が低下する。 |
| モデルの仮定とデータの真の分布とのずれ | モデルの仮定がデータの真の分布と合致しないと、誤った方向に学習が進む。 | データが複数のグループに分かれているのに、モデルが単一グループとして扱うと、グループごとの特徴を捉えきれず予測精度が低下する。 |
| モデルの評価の難しさ | ラベル付きデータを用いた直接的な評価ができないため、間接的な指標を用いてモデルの性能を推定する必要がある。適切な指標の選択が重要。 | – |
今後の展望

近年、学習データの一部にのみ正解ラベルが付与された、半教師あり学習という手法が注目を集めています。この手法は、限られたラベル付きデータと大量のラベルなしデータを活用することで、学習の精度を高めることを目指しています。今後の展望としては、まず深層学習との組み合わせが挙げられます。深層学習は複雑なデータのパターンを捉える能力に長けており、半教師あり学習と組み合わせることで、更に高精度な学習モデルを構築することが期待されます。例えば、画像認識の分野では、ラベル付きデータが少ない状況でも、大量のラベルなし画像データから特徴を学習し、高精度な画像分類を実現できる可能性があります。次に、ラベルなしデータの質を評価する手法の開発が重要になります。ラベルなしデータの質は学習精度に大きく影響するため、データの質を適切に評価し、学習に効果的に利用するための技術開発が不可欠です。例えば、データのノイズや偏りを検出する手法や、学習に有効なデータを選択する手法などが考えられます。さらに、より複雑なデータ構造に対応できる学習手法の開発も期待されます。例えば、グラフ構造や時系列データといった複雑なデータ構造を持つデータに対しても、半教師あり学習を適用することで、データの潜在的な情報をより効果的に活用できる可能性があります。医療診断や金融取引といった分野では、複雑なデータ構造を持つデータが多く存在するため、これらの分野への応用展開も期待されています。そして、様々な分野への応用展開も重要な展望です。例えば、製造業では、製品の品質検査に半教師あり学習を適用することで、検査コストを削減しながら検査精度を向上させることが期待されます。また、農業分野では、作物の生育状況を予測するモデルを構築することで、収穫量の向上に繋がる可能性があります。このように、半教師あり学習は、ラベル付きデータの不足という課題を克服し、機械学習の可能性を最大限に引き出すための鍵となる技術と言えるでしょう。今後、更なる研究開発が進み、様々な分野で活用されることで、私たちの生活をより豊かにする可能性を秘めています。
| 展望 | 詳細 | 例 |
|---|---|---|
| 深層学習との組み合わせ | 複雑なデータのパターンを捉える深層学習と組み合わせることで、高精度な学習モデルを構築。 | 画像認識:ラベル付きデータが少ない状況でも、高精度な画像分類を実現。 |
| ラベルなしデータの質を評価する手法の開発 | ラベルなしデータの質は学習精度に影響するため、質を評価し、効果的に利用する技術開発が不可欠。 | ノイズや偏りを検出する手法、学習に有効なデータを選択する手法。 |
| 複雑なデータ構造に対応できる学習手法の開発 | グラフ構造や時系列データといった複雑なデータ構造を持つデータにも適用可能。 | 医療診断、金融取引など。 |
| 様々な分野への応用展開 | ラベル付きデータの不足という課題を克服し、機械学習の可能性を最大限に引き出す。 | 製造業:製品の品質検査、農業:作物の生育状況予測。 |