
半教師あり学習:データの力を最大限に引き出す

AIを知りたい
先生、「半教師あり学習」って、どういう意味ですか?ラベル付きデータとラベルなしデータって、何ですか?

AIエンジニア
良い質問だね。ラベル付きデータとは、例えば犬の画像に「犬」という説明(ラベル)が付いているようなデータのことだよ。ラベルなしデータは、犬の画像はあるけれど「犬」という説明が付いていないデータのことだ。半教師あり学習は、少量のラベル付きデータと大量のラベルなしデータを組み合わせて学習する手法なんだ。
AIを知りたい
なるほど。つまり、少しの説明付きのデータと、たくさんの説明なしのデータを混ぜて学習させるんですね。でも、どうして説明なしのデータを使うと学習できるんですか?
AIエンジニア
説明なしのデータを使うことで、データ全体の構造や特徴をより深く理解できるからだよ。例えば、説明付きのデータで「犬」の特徴を少し学んだ後に、説明なしの犬の画像を見ることで、AIは「犬」の様々なバリエーションや見え方を学習し、より正確に「犬」を識別できるようになるんだ。
半教師あり学習とは。
人工知能で使われる言葉、『半教師あり学習』について説明します。半教師あり学習とは、少しのラベル付きデータとたくさんのラベルなしデータを使って、効率的に学習する方法です。
はじめに

機械学習の世界では、学習に使うデータの質と量がモデルの性能を大きく左右します。良い結果を得るには、大量のデータが必要です。さらに、そのデータ一つ一つに、写真に写っているものが何か、文章がどんな感情を表しているかといった「ラベル」と呼ばれる正解を付ける必要があります。しかし、このラベル付け作業は非常に手間と時間がかかり、大きなコストとなります。
そこで近年、注目を集めているのが半教師あり学習です。この学習方法は、ラベル付きデータとラベルなしデータを組み合わせてモデルを学習させるという画期的な手法です。ラベル付きデータは少量でも、大量のラベルなしデータと組み合わせることで、モデルはデータ全体の持つ情報をより深く理解し、高精度な予測が可能になります。ラベル付け作業の負担を減らしながら、モデルの性能向上を目指す、まさに一石二鳥の手法と言えるでしょう。
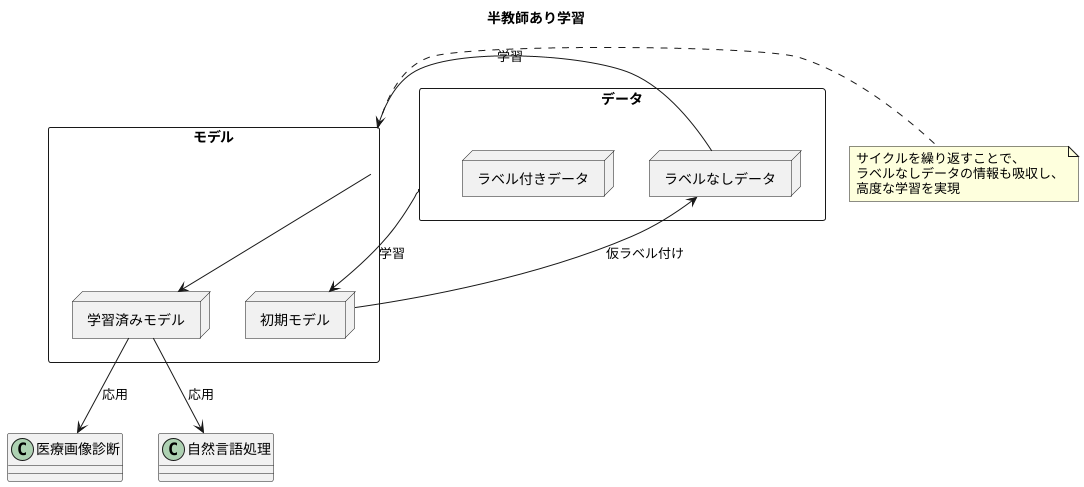
半教師あり学習の仕組みは、ラベル付きデータから学習した初期モデルを使って、ラベルなしデータに仮のラベルを付けるという点にあります。この仮ラベルを付けたデータと、元々あるラベル付きデータを合わせて、さらに学習を進めます。このサイクルを繰り返すことで、モデルはラベルなしデータの情報も吸収し、より高度な学習を実現します。
半教師あり学習は、様々な分野で活用されています。例えば、医療画像診断では、限られた専門医による診断データと大量の診断ラベルのない画像データを組み合わせることで、病気の早期発見に役立つ高精度なモデルを構築できます。また、自然言語処理の分野では、大量の文章データから文脈や意味を理解し、高精度な翻訳や文章要約を実現できます。このように、半教師あり学習は、限られた資源を有効活用し、高性能なモデルを構築するための強力な手法として、今後ますます発展していくことが期待されています。
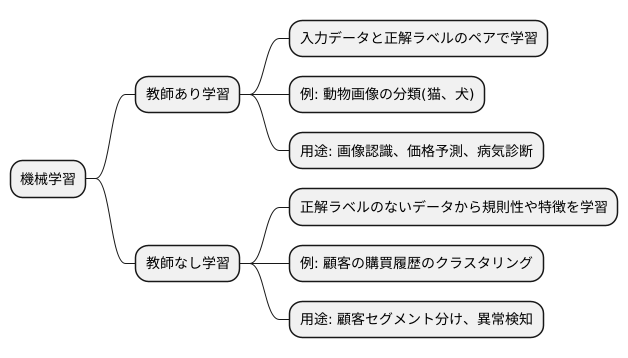
教師あり学習と教師なし学習

機械学習には大きく分けて、教師あり学習と教師なし学習という二つの学び方があります。この二つの学習方法を理解することは、より高度な学習方法を学ぶための大切な一歩です。
まず、教師あり学習について考えてみましょう。教師あり学習は、まるで先生が生徒に勉強を教えるように、正解がすでに分かっているデータを使って学習を行います。例えば、たくさんの動物の画像を用意し、それぞれに「これは猫です」「これは犬です」といったラベルを付けます。このラベル付きデータを使って機械学習モデルを訓練することで、新しい動物の画像を見せても、それが猫か犬かを判別できるようになります。このように、入力データに対応する正しい出力を教えながら学習させるのが教師あり学習です。画像認識以外にも、商品の価格予測や、病気の診断など、様々な分野で活用されています。
一方、教師なし学習は、正解ラベルのないデータから、データの中に隠れている規則性や特徴を見つけ出す学習方法です。教師がいない中で、生徒が自分でデータを分析し、グループ分けや関連性を見つけるようなイメージです。例えば、顧客の購買履歴データから、似たような購買傾向を持つ顧客をグループ分けすることができます。これをクラスタリングと呼びます。他にも、高次元データをより低い次元に変換してデータの構造を把握する次元削減といった手法も教師なし学習の一つです。教師なし学習は、顧客のセグメント分けや異常検知など、様々な分野で応用されています。
このように、教師あり学習と教師なし学習はそれぞれ異なる特徴を持つ学習方法です。これらの学習方法を理解することで、より複雑な学習方法である半教師あり学習への理解も深まります。
半教師あり学習の仕組み

半教師あり学習とは、少量のラベル付きデータと大量のラベルなしデータを組み合わせて学習を行う機械学習の手法です。教師あり学習のように全てのデータにラベルを付ける必要がないため、ラベル付けのコストを削減しつつ、ラベルなしデータに含まれる情報を活用してモデルの精度を向上させることができます。
まず、用意した少量のラベル付きデータを使って初期のモデルを学習させます。この初期モデルは、いわば教師あり学習によって作られたベースとなるモデルです。次に、この学習済みモデルを用いて、大量にあるラベルなしデータに対して予測を行い、擬似的なラベルを付与します。この擬似ラベルは、モデルがラベルなしデータに対して推定したラベルであり、真のラベルではありませんが、モデルの学習には役立ちます。
ラベル付きデータと擬似ラベルを付与したラベルなしデータを統合した新たなデータセットを作成し、このデータセットを用いてモデルを再学習させます。再学習によって、モデルはラベルなしデータの情報も取り込み、より複雑なパターンを学習し、より高い精度で予測を行うことができるようになります。
この、擬似ラベルの付与とモデルの再学習のプロセスは、設定した条件を満たすまで、あるいは一定回数繰り返されます。例えば、モデルの性能が向上しなくなったり、あらかじめ設定した回数に達したら、学習を終了します。
このように、半教師あり学習は、ラベル付きデータが少ない場合でも、ラベルなしデータを活用することで、ラベル付きデータのみを用いる教師あり学習よりも高い性能を実現できる可能性を秘めています。限られた資源でより良いモデルを構築したい場合に有効な手法と言えるでしょう。
半教師あり学習の利点

機械学習を行う上で、学習データにラベルを付ける作業は欠かせません。しかし、このラベル付け作業は多大な時間と費用を必要とします。例えば、画像認識のタスクでは、画像一枚一枚に写っている物体を人間が確認し、ラベルを付けていく必要があります。膨大な量の画像を扱う場合、この作業は非常に大変なものとなります。半教師あり学習は、このようなラベル付け作業の負担を軽減する有効な手法です。
半教師あり学習は、少量のラベル付きデータと大量のラベルなしデータの両方を使って学習を行います。ラベル付きデータから学習した知識を基に、ラベルなしデータに仮想的なラベルを付け、それを新たな学習データとして利用します。このように、ラベルなしデータの情報も活用することで、少量のラベル付きデータだけでは得られない学習効果が期待できます。ラベル付きデータが少ない状況でも、ラベルなしデータの情報を取り込むことで、モデルの精度を高めることができるのです。
さらに、半教師あり学習は、モデルの汎化性能向上にも貢献します。汎化性能とは、未知のデータに対しても正確な予測を行う能力のことです。ラベル付きデータのみで学習したモデルは、学習データに過剰に適応してしまい、未知データへの対応力が低くなることがあります。これを過学習と言います。半教師あり学習では、ラベルなしデータの情報も学習に利用することで、過学習を抑制し、汎化性能を高める効果が期待できます。つまり、より多くのデータで学習を行うことで、未知のデータに対しても正確な予測ができるようになるのです。
このように、半教師あり学習は、限られたラベル付きデータと大量のラベルなしデータから高性能なモデルを構築するための強力なツールと言えるでしょう。ラベル付け作業のコスト削減、モデル精度の向上、汎化性能の向上といった多くの利点を持つ半教師あり学習は、今後ますます重要な学習手法となるでしょう。
| 半教師あり学習のメリット | 詳細 |
|---|---|
| ラベル付け作業の負担軽減 | 少量のラベル付きデータと大量のラベルなしデータを利用することで、ラベル付け作業にかかる時間と費用を削減できる。 |
| モデル精度の向上 | ラベルなしデータの情報も活用することで、少量のラベル付きデータだけでは得られない学習効果が期待できる。 |
| 汎化性能の向上 | ラベルなしデータの情報も学習に利用することで、過学習を抑制し、未知のデータに対しても正確な予測を行う能力を高める。 |
半教師あり学習の応用例

少量の教師データと大量の教師なしデータを使う学習方法である半教師あり学習は、様々な分野で応用され、成果を上げています。特に、大量のデータが必要となるものの、データ全てにラベルをつけるのが難しい分野で効果を発揮します。
例えば、画像認識の分野を考えてみましょう。画像認識では、莫大な数の画像データが必要となります。しかし、全ての画像にラベル(例えば、「猫」「犬」「車」など)を付けるのは、多大な時間と費用がかかります。そこで、半教師あり学習を用いることで、ラベル付きの画像データが少量であっても、ラベルのない大量の画像データも活用して、高精度な画像認識モデルを構築できます。
医療画像診断も半教師あり学習の応用例の一つです。熟練した医師による診断には時間がかかり、診断結果付きの画像は限られています。しかし、診断結果のない画像は大量に存在します。半教師あり学習を使うことで、少量の診断済み画像と大量の診断されていない画像を組み合わせて学習し、病変の検出精度を向上させることが可能です。これにより、医師の負担軽減や診断精度の向上に貢献します。
また、金融業界における不正検知システムにも応用できます。不正行為は稀にしか起こらないため、不正と断定できるデータは限られています。しかし、通常の取引データは大量に蓄積されています。半教師あり学習を用いることで、限られた不正データと大量の正常データから不正検知モデルを学習し、効率的に不正行為を発見することができます。
このように、半教師あり学習は、ラベル付きデータの不足という課題を解決する有効な手段であり、様々な分野で革新的な進歩をもたらしています。今後、データ量がますます増大していく中で、半教師あり学習の重要性はさらに高まっていくと考えられます。
| 分野 | 課題 | 半教師あり学習の利点 |
|---|---|---|
| 画像認識 | 大量の画像データが必要だが、全てにラベルを付けるのは困難 | 少量のラベル付き画像と大量のラベルなし画像を活用して、高精度なモデルを構築 |
| 医療画像診断 | 熟練医師による診断には時間がかかり、診断結果付き画像は限られている | 少量の診断済み画像と大量の診断されていない画像を学習し、病変の検出精度を向上 |
| 金融業界における不正検知 | 不正行為のデータは限られているが、通常の取引データは大量に存在する | 限られた不正データと大量の正常データから不正検知モデルを学習し、不正行為を効率的に発見 |
今後の展望

近年、一部のデータにしか正解ラベルが付いていない状況でも学習可能な半教師あり学習が、様々な分野で注目を集めています。限られた正解データからでも、大量のラベルなしデータを用いることで、学習モデルの精度を高めることが期待できるためです。今後、この技術は更なる発展を遂げ、社会に大きな影響を与える可能性を秘めています。
まず、深層学習との組み合わせは、半教師あり学習の進化を加速させる重要な要素です。深層学習は複雑なパターンを認識する能力に長けており、ラベルなしデータからでも有用な情報を抽出できます。この二つの技術を組み合わせることで、より高精度な予測モデルを構築できると期待されています。例えば、画像認識や自然言語処理といった分野では、膨大なラベルなしデータが存在します。これらのデータを活用することで、従来よりも少ない教師データで高性能なモデルを学習できる可能性があります。
また、ラベルなしデータの質や量、そしてラベル付きデータとの適切なバランスも、半教師あり学習の成果に大きく影響します。質の高いラベルなしデータは、モデルの学習を促進し、精度向上に繋がります。一方で、ノイズの多いデータや偏りのあるデータは、学習を阻害する可能性もあります。さらに、ラベル付きデータとラベルなしデータの比率も、学習結果に大きな影響を与えます。最適な比率はデータの種類や学習タスクによって異なるため、個々の状況に応じて適切なバランスを見つける必要があります。これらの要素を最適化するための研究は、半教師あり学習の更なる普及に不可欠です。
そして、学習の効率化も重要な課題です。大量のデータを扱う半教師あり学習では、学習に時間がかかる場合があります。そのため、より効率的な学習手法の開発が求められています。例えば、学習アルゴリズムの改良や、計算資源の効率的な利用など、様々なアプローチが考えられます。
このように、半教師あり学習は様々な可能性を秘めており、今後の更なる進化が期待されます。様々なデータ形式への対応や、新たな学習手法の開発など、今後の研究開発によって、より多くの分野で活用され、社会に貢献していくことでしょう。
| 半教師あり学習のポイント | 詳細 |
|---|---|
| 深層学習との組み合わせ | 深層学習の複雑なパターン認識能力と組み合わせることで、ラベルなしデータから有用な情報を抽出し、高精度な予測モデルを構築。画像認識や自然言語処理等で有効。 |
| データの質と量、バランス | ラベルなしデータの質と量、ラベル付きデータとのバランスが学習成果に影響。質の高いデータは精度向上に繋がる一方、ノイズや偏りは学習を阻害。最適な比率はデータやタスクごとに異なる。 |
| 学習の効率化 | 大量データ処理による学習時間の増加に対応するため、効率的な学習手法の開発が必要。アルゴリズム改良や計算資源の効率利用など。 |