
報酬成形:強化学習のカギ

AIを知りたい
『報酬成形』って、報酬をどう設定するかでAIの学習内容が変わるってことですよね?具体的にどういうことですか?

AIエンジニア
そうだね。例えば、犬に『お手』を教えたいとする。報酬をおやつにすると、犬はおやつをもらうためにお手を覚える。でも、もし報酬を撫でることにしたらどうだろう?
AIを知りたい
うーん、おやつほど喜んでくれないかも。もしかしたら、撫でられるより他のことをした方がいいと思って、お手は覚えないかもしれませんね。
AIエンジニア
その通り!AIも同じで、何を報酬とするかで学習結果は大きく変わる。だから、AIに望ましい行動を学習させるには、適切な報酬を設定する『報酬成形』が重要なんだ。
報酬成形とは。
人工知能の学習方法の一つである強化学習では、「報酬」を使って学習を促します。この報酬をどのように与えるかを調整することを「報酬成形」と言います。適切な報酬を設定するために、報酬の与え方と学習効果を何度も繰り返し確認していきます。報酬の与え方次第で、学習結果は大きく変わってきます。
報酬成形とは

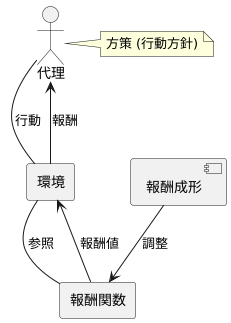
報酬成形とは、強化学習において学習主体を導く報酬関数を調整する技法のことです。強化学習では、学習主体は環境とのやり取りを通して学習を進めます。この学習主体は、しばしば「代理」と呼ばれます。代理は、周りの状況に応じて様々な行動を取りますが、どの行動が良いのか、どの行動が悪いのかを判断する基準が必要です。この基準となるのが報酬関数です。報酬関数は、代理の行動に対して数値的な評価を与えます。
報酬成形は、この報酬関数を適切に設計し、修正する作業を指します。適切な報酬関数は、代理が目標達成に向けて効率的に学習を進めるために不可欠です。もし報酬関数が不適切であれば、代理は目標とは異なる方向に学習を進めてしまう可能性があります。これは、目的地が分からないまま、暗闇の中を手探りで進むようなものです。報酬成形は、代理にとっての道標、あるいは灯台のような役割を果たします。代理が進むべき方向を明るく照らし出し、目標達成へと導きます。
具体的な手法としては、試行錯誤を繰り返しながら、報酬関数の設計と代理の行動方針を確認していきます。代理の行動方針のことを「方策」と呼びます。まず、報酬関数を設計し、その報酬関数に基づいて代理に学習させます。そして、代理の学習結果、つまり方策を確認し、それが目標達成に適切かどうかを評価します。もし方策が不適切であれば、報酬関数を修正し、再度代理に学習させます。この過程を繰り返すことで、最終的に目的とする作業に最適な報酬関数を導き出します。適切に設計された報酬関数によって、代理は迷うことなく目標へとたどり着くことができるのです。
報酬関数の重要性

機械学習の中でも、強化学習という分野では、報酬関数というものが大変重要です。これは例えるなら、教師が生徒を導くための褒美と罰のようなものです。生徒の行動が良い方向に向かっている時は褒美を与え、そうでない時は罰を与えることで、生徒は正しい行動を学ぶことができます。これと同じように、強化学習では、コンピュータプログラムであるエージェントに、ある目的を達成させるために、報酬関数を使って望ましい行動を学習させます。
例えば、チェスをプレイするプログラムを学習させるとしましょう。この場合、目的は勝利することです。もし、勝利した時だけ褒美を与えるように設定すると、プログラムは勝利という目標にたどり着くまでの道筋を見つけるのがとても難しくなります。チェスでは、無数の打ち手があり、勝利に繋がる行動を見つけるのは、大海原で針を探すようなものです。そのため、勝利という最終的な目標だけでなく、そこに至るまでの過程での行動にも褒美を与える必要があります。例えば、相手の駒を取る、王を守る、良い場所に駒を配置する、といった行動です。
これらの小さな成功に対しても褒美を与えることで、プログラムは段階的に学習を進めることができます。まるで山登りで、頂上を目指すだけでなく、途中の拠点に到達する度に休憩し、景色を楽しむように、プログラムは小さな成功体験を積み重ねながら、最終的な目標である勝利へと近づいていきます。このように、報酬関数は、プログラムが何を学ぶべきか、どのような行動が良い行動なのかを教える羅針盤のような役割を果たします。報酬関数の設計が適切であれば、プログラムは効率的に学習し、目標を達成することができます。逆に、報酬関数の設計が不適切だと、プログラムは望ましい行動を学習できず、目標達成が難しくなります。そのため、強化学習において、報酬関数は学習の成否を握る重要な鍵となります。
報酬成形の難しさ

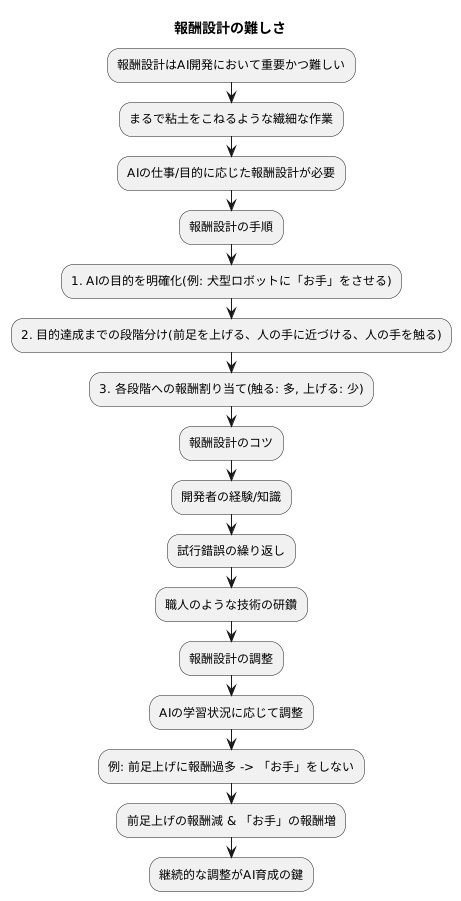
報酬をうまく形作ることは、人工知能を作る上でとても大切ですが、同時にとても難しいことでもあります。ちょうど粘土をこねて思い通りの形にしようとするときのように、繊細な作業であり、簡単にはいきません。なぜなら、人工知能にさせたい仕事や目的によって、それに合った報酬の与え方が変わるからです。あらゆる仕事に効く万能な方法はありません。
報酬の与え方を決めるには、まず人工知能に何をさせたいのかを、はっきりと決める必要があります。たとえば、犬型ロボットに「お手」をさせたいとき、「お手」をするまでにどんな段階があるかを細かく分けます。前足を上げる、人の手に近づける、人の手を触る、などです。そして、それぞれの段階での行動に、適切な報酬の大きさを割り当てます。人の手に触れたら多くの報酬を、前足を少し上げただけでも少し報酬を与えると、犬型ロボットはだんだん「お手」を覚えるでしょう。
この報酬の与え方を決める部分は、開発者の経験や知識、そして何度も試すことによって、より良い形を見つけていくしかありません。まるで職人が技術を磨くように、試行錯誤を繰り返すことが重要になります。
また、一度決めた報酬の与え方が、ずっと最適とは限りません。人工知能が学習していく様子を見ながら、必要に応じて報酬の与え方を調整していく必要があります。たとえば、犬型ロボットが前足を上げるだけで多くの報酬を得られると、「お手」をせずに前足を上げ続けるかもしれません。そのような時は、前足を上げただけでは報酬を少なくし、「お手」をしたときにだけ多くの報酬を与えるように調整します。このように、人工知能の学習状況を常に見て、報酬の与え方を変えていくことが、人工知能をうまく育てる鍵となります。
報酬成形の効果

報酬成形は、強化学習における学習の効率と最終的な成果を大きく向上させる重要な手法です。適切に設計された報酬成形は、まるで登山家が頂上を目指す際に、経験豊富なガイドが最適なルートを示してくれるように、学習主体であるエージェントを目標達成へと導きます。
強化学習では、エージェントは試行錯誤を通じて環境と相互作用し、行動の結果として得られる報酬に基づいて学習を進めます。しかし、特に複雑な課題においては、目標達成までの道のりが長く、偶然に成功するまで学習を続けるのは非常に困難です。まるで広大な砂漠でオアシスを探すようなもので、闇雲に彷徨うだけでは、なかなか目的地にたどり着けません。
報酬成形は、このような状況において、エージェントに道標を与える役割を果たします。目標達成につながる行動に対して中間的な報酬を与えることで、エージェントはより明確な学習信号を受け取ることができます。例えば、ロボットが物を掴む学習をする場合、単に掴むこと自体に報酬を与えるだけでなく、対象物に近づく行動にも報酬を与えます。これにより、ロボットは掴むための手順を段階的に学習し、効率的に目標を達成することができます。
報酬成形は、学習の迷走を防ぎ、目標への最短経路を示すガイドとしての役割を果たします。適切な報酬成形は、学習の初期段階でエージェントを正しい方向に導き、学習時間を大幅に短縮します。また、適切な報酬成形は、エージェントが局所的な最適解に陥ることを防ぎ、真の目標達成へと導きます。
効果的な報酬成形は、強化学習の成功を大きく左右する重要な要素と言えるでしょう。適切な報酬成形の設計は容易ではありませんが、その効果は絶大です。適切に設計された報酬成形によって、エージェントは複雑な課題でも効率的に学習し、優れた成果を発揮することができます。
| 報酬成形 | 説明 | 例 |
|---|---|---|
| 役割 | 強化学習において、学習主体であるエージェントを目標達成へと導くガイドの役割を果たす。目標達成につながる行動に対して中間的な報酬を与えることで、エージェントはより明確な学習信号を受け取ることができる。 | 登山家が頂上を目指す際に、経験豊富なガイドが最適なルートを示してくれる。 |
| 課題 | 複雑な課題において、目標達成までの道のりが長く、偶然に成功するまで学習を続けるのは非常に困難。 | 広大な砂漠でオアシスを探すようなもので、闇雲に彷徨うだけでは、なかなか目的地にたどり着けません。 |
| 効果 | 学習の迷走を防ぎ、目標への最短経路を示す。学習の初期段階でエージェントを正しい方向に導き、学習時間を大幅に短縮。エージェントが局所的な最適解に陥ることを防ぎ、真の目標達成へと導く。 | ロボットが物を掴む学習をする場合、単に掴むこと自体に報酬を与えるだけでなく、対象物に近づく行動にも報酬を与えます。これにより、ロボットは掴むための手順を段階的に学習し、効率的に目標を達成することができます。 |
| 設計の重要性 | 効果的な報酬成形は、強化学習の成功を大きく左右する重要な要素。適切な報酬成形の設計は容易ではありませんが、その効果は絶大。適切に設計された報酬成形によって、エージェントは複雑な課題でも効率的に学習し、優れた成果を発揮することができる。 | – |
今後の展望

機械学習の一種である強化学習は、まるで人間が試行錯誤を通じて学習するように、コンピュータが目的を達成するための行動を自ら学習していく方法です。この学習において、行動の良し悪しを評価する基準となるのが「報酬」であり、適切な報酬を与える仕組みを「報酬成形」と呼びます。この報酬成形こそが、強化学習の成否を大きく左右する重要な要素となっています。
近年、強化学習は目覚ましい発展を遂げ、様々な分野で応用され始めています。例えば、ロボットの制御やゲームの攻略、さらには自動運転技術など、複雑な課題を解決する手段として期待が高まっています。しかし、より高度な課題に挑戦するためには、現状の報酬成形では不十分です。複雑な状況に応じて適切な報酬を与えるためには、より洗練された手法が必要となります。
現在、世界中の研究者たちが、より高度な報酬成形の実現に向けて活発な研究開発に取り組んでいます。具体的には、コンピュータが自ら報酬の基準を調整する「自動報酬成形」や、人間の専門家の知識や経験を反映させる「人間参加型報酬成形」など、様々なアプローチが試みられています。これらの研究が実を結べば、強化学習はさらに適用範囲を広げ、これまで解決が難しかった複雑な問題にも対応できるようになるでしょう。
将来、報酬成形の技術がさらに進化すれば、強化学習は私たちの生活をより豊かに、より便利にすると期待されています。例えば、家事ロボットが人間の指示を待つことなく、自ら考えて最適な家事を行うようになるかもしれません。また、医療現場では、患者の状態に合わせて最適な治療方法を選択する支援システムが実現する可能性もあります。このように、報酬成形は強化学習の未来を大きく左右する重要な技術であり、今後の研究の進展に大きな期待が寄せられています。
| 用語 | 説明 | 応用例 | 課題 | 今後の展望 |
|---|---|---|---|---|
| 強化学習 | 試行錯誤を通じて報酬を最大化する行動を学習する機械学習の一種。 | ロボット制御、ゲーム攻略、自動運転 | 複雑な課題への対応には、現状の報酬成形では不十分。 | より高度な報酬成形の実現により、適用範囲の拡大と複雑な問題への対応が可能に。 |
| 報酬成形 | 強化学習において、行動の良し悪しを評価する報酬を与える仕組み。 | 複雑な状況に応じて適切な報酬を与えるための洗練された手法が必要。 | 自動報酬成形、人間参加型報酬成形など、様々なアプローチが研究開発中。 |