
REINFORCE:方策勾配法入門

AIを知りたい
先生、『REINFORCE(レインフォース)』って強化学習の一種ですよね?どんなものか教えてください。

AIエンジニア
そうだね。『REINFORCE』は強化学習の一種で、方策勾配法というやり方の基本的なものだよ。強化学習では普通、価値関数を求めて、より良い行動を選べるようにしていくんだけど、『REINFORCE』は価値関数を使わずに、直接良い行動を見つけ出すんだ。
AIを知りたい
価値関数を使わずに、直接行動を見つけ出す?難しそうですね。具体的にはどのようにするのですか?
AIエンジニア
試行錯誤を通じて、うまくいった行動の確率を高く、うまくいかなかった行動の確率を低くしていくんだ。確率を調整することで、だんだんコンピュータが最適な行動を選べるようになっていくんだよ。
REINFORCEとは。
人工知能に関わる言葉「REINFORCE」について説明します。REINFORCEは、機械学習の一種である強化学習の一つの方法です。強化学習では一般的に、ある行動の価値を最大化するようなやり方を学ぶことが多いのですが、REINFORCEはもっと直接的に、最適な行動の選び方を学習します。このようなやり方を「方策勾配法」と言い、REINFORCEはこの方策勾配法の中でも、最も基本的な方法です。
強化学習とは

強化学習とは、機械が試行錯誤を通して学習する手法です。まるで、生まれたばかりの赤ちゃんが歩き方を覚える過程のようです。赤ちゃんは、最初はうまく歩くことができず、何度も転んでしまいます。しかし、転ぶたびに、どのように足を動かせばいいのか、どのようにバランスをとればいいのかを少しずつ学んでいきます。最終的には、しっかりと立てるようになり、自由に歩き回ることができるようになります。
強化学習もこれと同様に、機械が環境の中で様々な行動を試しながら、より良い結果を得るための方法を学習します。この学習の主役は「エージェント」と呼ばれるプログラムです。エージェントは、周りの環境を観察し、どのような行動をとるかを決定します。そして、行動の結果として、環境から「報酬」と呼ばれる信号を受け取ります。報酬は、良い行動には高い値、悪い行動には低い値が設定されています。エージェントの目標は、将来得られる報酬の合計を最大にすることです。そのため、エージェントは試行錯誤を通して、報酬を最大にする行動戦略を学習していきます。
例えば、掃除ロボットを例に考えてみましょう。掃除ロボットは部屋の中を動き回り、ゴミを見つけたら掃除をします。この時、ゴミを掃除できた場合は高い報酬、壁にぶつかった場合は低い報酬が与えられます。強化学習を用いることで、掃除ロボットは報酬を最大化するように、つまり、効率的にゴミを掃除し、壁にぶつからないように行動することを学習できます。このように、強化学習は、明確な正解が与えられていない状況下で、最適な行動を学習するのに適した手法と言えるでしょう。
価値関数と方策勾配

強化学習とは、試行錯誤を通じて行動を学習する枠組みのことです。この学習には、大きく分けて二つの手法があります。一つは価値関数に基づく手法、もう一つは方策勾配に基づく手法です。
価値関数に基づく手法は、まず各状態や行動の価値を推定します。この価値とは、将来得られる報酬の期待値を表します。例えば、ある状態に達した時、あるいはある行動をとった時に、その後どれだけの報酬を得られるかを予測するのです。価値が高い状態や行動は、将来多くの報酬を得られる可能性が高いことを意味します。この手法では、推定した価値に基づいて行動を選択します。価値の高い行動を優先的に選ぶことで、最終的に得られる報酬の合計値、つまり累積報酬を最大化できると考えられています。
一方、方策勾配に基づく手法は、価値関数を経由せずに、方策を直接最適化します。方策とは、ある状態でどの行動をとるかを決める規則のことです。具体的には、各状態でどの行動をとるかの確率分布で表されます。例えば、「状態Aでは行動Xを70%の確率で、行動Yを30%の確率で選択する」といった具合です。方策勾配法では、試行錯誤を通じて、この確率分布を少しずつ調整していきます。より良い報酬が得られるように、行動選択の確率を変化させていくのです。価値関数を推定する必要がないため、状態や行動の数が非常に多い場合でも、方策勾配法は適用可能です。価値関数に基づく手法では、膨大な数の状態や行動の価値を全て計算する必要があるため、計算量が膨大になり、現実的な時間で計算できない可能性があります。方策勾配法は、このような問題を回避できるため、近年注目を集めています。
| 手法 | 説明 | 特徴 |
|---|---|---|
| 価値関数に基づく手法 | 各状態や行動の価値(将来得られる報酬の期待値)を推定し、価値の高い行動を優先的に選択する。 | 状態や行動の数が非常に多い場合、計算量が膨大になる可能性がある。 |
| 方策勾配に基づく手法 | 価値関数を経由せずに、方策(ある状態でどの行動をとるかを決める規則)を直接最適化する。 | 状態や行動の数が非常に多い場合でも適用可能。近年注目を集めている。 |
REINFORCE:方策勾配法の基礎

強化学習とは、試行錯誤を通じて行動の良し悪しを学び、最適な行動を見つける学習方法です。その中でも、方策勾配法は、行動を決める方策を直接学習する手法として知られています。REINFORCEは、この方策勾配法の中でも、最も基本的なアルゴリズムの一つです。
REINFORCEは、モンテカルロ法に基づいて学習を行います。モンテカルロ法とは、エピソードが終了するまで待って、そこで得られた報酬を用いて学習する手法です。具体的には、ある場面における行動の選択確率を方策と呼びますが、REINFORCEは、実際に試した行動とその結果得られた報酬を使って、この方策を更新します。
例えば、迷路を解く場面を考えてみましょう。REINFORCEを用いた学習では、迷路のスタートからゴールまでを一つのエピソードとします。エージェントは、迷路の中で様々な行動を試みます。そして、ゴールに辿り着いた場合、その時に得られた報酬と、そのエピソード中に選択した行動を記録します。ゴールに辿り着けなかった場合も同様に、得られた報酬と行動を記録します。
得られた報酬が高いほど、そのエピソード中に選択した行動の選択確率を高くするように方策を更新します。逆に、得られた報酬が低い場合は、選択した行動の選択確率を低くするように更新します。つまり、成功体験を強化し、失敗体験を抑制するように学習を進めます。
このように、REINFORCEは、試行錯誤を通して、より良い報酬が得られる行動の選択確率を高めることで、最終的に迷路を解くための最適な方策を学習します。このように、行動の選択確率を直接操作することで、複雑な行動戦略を学習できることが、REINFORCEの特徴です。
| 項目 | 説明 |
|---|---|
| 強化学習 | 試行錯誤を通じて行動の良し悪しを学び、最適な行動を見つける学習方法 |
| 方策勾配法 | 行動を決める方策を直接学習する手法 |
| REINFORCE | 方策勾配法の中でも、最も基本的なアルゴリズムの一つ。モンテカルロ法に基づいて学習を行う。 |
| モンテカルロ法 | エピソードが終了するまで待って、そこで得られた報酬を用いて学習する手法 |
| 方策 | ある場面における行動の選択確率 |
| REINFORCEの学習方法 | 実際に試した行動とその結果得られた報酬を使って、方策を更新 |
| 迷路の例 | 迷路のスタートからゴールまでを一つのエピソードとし、ゴールに辿り着いた場合の報酬と選択した行動を記録。ゴールに辿り着けなかった場合も同様に記録。 |
| 方策の更新 | 得られた報酬が高いほど、選択した行動の選択確率を高く更新。報酬が低い場合は、選択確率を低く更新。 |
| REINFORCEの特徴 | 試行錯誤を通して、より良い報酬が得られる行動の選択確率を高めることで、最適な方策を学習。行動の選択確率を直接操作することで、複雑な行動戦略を学習できる。 |
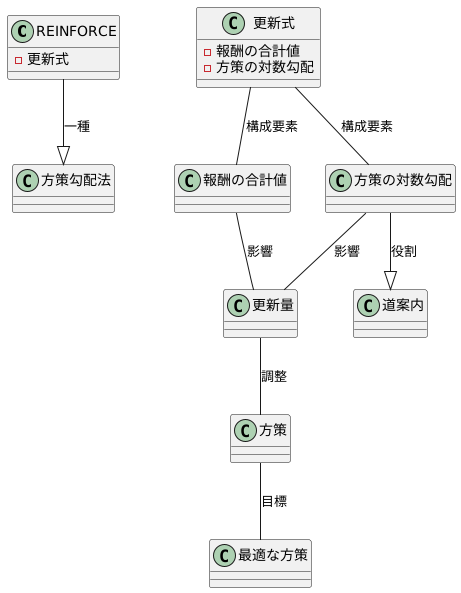
REINFORCEの更新式

強化学習の中でも、方策勾配法という種類の学習手法の一つにREINFORCEがあります。REINFORCEは、方策を直接更新していくことで、より良い行動を選び取る力を身につけていきます。では、どのように方策を更新していくのか、その中心となるのが更新式です。
REINFORCEの更新式は、現在の方策を少しだけ調整するための計算式です。この式は、大きく分けて二つの要素から成り立っています。一つは、ある試行で得られた報酬の合計値です。もう一つは、現在の方策において、行動の選択確率を少しだけ変化させるための指標となる、方策の対数勾配です。
方策の対数勾配は、いわば道案内のような役割を果たします。より良い行動へと方策を導くための、変化の方向を示してくれるのです。この道案内と、試行で得られた報酬を掛け合わせることで、更新量が計算されます。
試行で得られた報酬が高いほど、更新量は大きくなります。これは、良い結果が得られた行動を、より選びやすくするように方策を調整することを意味します。逆に、報酬が低い場合は、更新量は小さくなり、方策の変化も小さくなります。つまり、あまり良くない結果になった行動は、選びにくくするように調整されます。
この更新式を何度も繰り返し適用することで、方策は徐々に改善されていきます。最終的には、与えられた環境において、最も高い報酬が得られるような、最適な方策にたどり着くことが期待されます。しかし、REINFORCEは、更新量が試行ごとの報酬に直接影響を受けるため、学習の過程が不安定になることがあります。そのため、より安定した学習を実現するために、様々な改良手法が研究されています。
REINFORCEの利点と欠点

強化学習における方策勾配法の一つであるREINFORCEは、実装の容易さと連続的な行動空間への対応という利点を持ちます。価値関数を用いることなく、方策を直接最適化するため、アルゴリズムの仕組みが分かりやすく、比較的簡単にプログラムに落とし込むことができます。さらに、行動が連続的な値を取るような問題にも適用できるため、ロボット制御のような複雑なタスクにも対応可能です。例えば、ロボットアームの動きの滑らかさを学習させる場合、REINFORCEは有効な手法となります。
しかし、REINFORCEには学習の不安定さと学習速度の遅さという欠点も存在します。報酬のばらつきが大きいと、学習が安定せず、最適な方策にたどり着くのが難しくなります。これは、山登りで例えると、急に険しい崖が現れるようなもので、なかなか頂上へたどり着けない状況に似ています。また、REINFORCEは一つの試行が終わるまで学習に必要な情報が得られないため、試行に時間がかかる問題では学習に時間がかかります。迷路を解くロボットを例に挙げると、ゴールにたどり着くまでに多くのステップが必要な場合、REINFORCEでは学習が非常に遅くなります。このように、REINFORCEは単純な問題には有効ですが、複雑な問題への適用には工夫が必要となります。学習の不安定さを解消するために、ベースラインと呼ばれる手法を導入したり、分散を小さくするような工夫がしばしば用いられます。また、試行の長さの問題に対しては、試行を途中で区切るなど、問題の性質に合わせた調整が必要となります。
つまり、REINFORCEは実装が容易で連続的な行動空間にも対応できる一方、学習の不安定さと学習速度の遅さという課題も抱えているため、問題の特性を理解した上で適切に利用することが重要です。
| 項目 | 内容 |
|---|---|
| 手法名 | REINFORCE (方策勾配法) |
| 利点 | 実装が容易 連続的な行動空間への対応 |
| 利点の具体例 | ロボットアームの動きの滑らかさを学習 |
| 欠点 | 学習の不安定さ (報酬のばらつきが大きいと最適な方策にたどり着けない) 学習速度の遅さ (試行が終わるまで学習情報が得られない) |
| 欠点の具体例 | 迷路を解くロボットの学習が遅い |
| 欠点への対策 | ベースラインの導入 分散を小さくする工夫 試行を途中で区切る |
| 結論 | 問題の特性を理解した上で適切に利用することが重要 |
REINFORCEの応用例

REINFORCEアルゴリズムは、試行錯誤を通じて学習する強化学習の手法において、基礎となる重要な技術です。 この手法は、様々な分野の問題解決に役立っています。
例えば、ゲームの世界では、コンピュータにゲームのルールを教えなくても、REINFORCEアルゴリズムを使って自ら学習させることができます。複雑なルールや戦略を持つゲームでも、まるで人間のように高度な技を身につけ、巧みにプレイするコンピュータ・プレイヤーを作り出すことが可能です。
また、ロボット工学の分野でもREINFORCEは活躍しています。ロボットに特定の動作をプログラムする代わりに、REINFORCEアルゴリズムを用いることで、ロボットは周りの環境を認識し、状況に合わせて最適な行動を自ら学習できます。 例えば、障害物を避けながら目的地まで移動する、物を掴んで運ぶといった複雑な作業を、試行錯誤を通して効率的に学習することが可能になります。
さらに、インターネット広告の最適化にもREINFORCEは応用されています。ユーザーの行動や反応を分析し、広告の表示方法や内容を自動的に調整することで、より効果的な広告配信を実現できます。 これにより、広告主は費用対効果を高め、ユーザーは自分に合った広告を見ることができるようになります。
交通の流れをスムーズにする信号制御にもREINFORCEは役立ちます。道路の混雑状況や交通量の変化に応じて、信号の切り替え時間を最適化することで、渋滞を緩和し、円滑な交通を実現することが期待されています。
このようにREINFORCEアルゴリズムは、ゲーム、ロボット、広告、交通など、様々な分野で応用され、成果を上げています。この技術を深く理解することは、強化学習の可能性を広げ、私たちの生活をより豊かにするために非常に大切です。
| 分野 | REINFORCEアルゴリズムの応用例 |
|---|---|
| ゲーム | ルールを教えずにゲームを学習させ、高度なプレイをするAIプレイヤーを作成 |
| ロボット工学 | 環境認識に基づき最適な行動を学習(例:障害物回避、物の運搬) |
| インターネット広告 | ユーザーの反応を分析し、広告表示を最適化、費用対効果向上 |
| 交通制御 | 交通状況に応じて信号切り替え時間を最適化、渋滞緩和 |