
ランダムフォレスト:多数決で賢く予測

AIを知りたい
先生、『ランダムフォレスト』って、たくさんの木をまとめて使うって聞いたんですけど、どうしてたくさんの木を使うんですか?

AIエンジニア
いい質問だね。一つ一つの木だと、判断が偏ってしまうことがあるんだ。たくさんの木で判断することで、より正確で安定した結果を得られるんだよ。
AIを知りたい
なるほど。でも、木が多すぎると計算が大変じゃないですか?
AIエンジニア
確かに計算量は増えるけど、たくさんの木を使うことで、それぞれの木の欠点を補い合って、全体としてより良い結果になるんだ。それに、最近のコンピューターは性能が良いから、それほど問題にならないよ。
RandomForestとは。
「人工知能で使われる言葉、『ランダムフォレスト』について説明します。ランダムフォレストは、ものの分類や数値の予測といった問題に使える機械学習の方法です。たくさんの小さな予測モデルを組み合わせて、より正確な予測をする方法のひとつです。入力されたデータから一部を無作為に選び出し、決定木と呼ばれる単純な予測モデルをたくさん作ります。決定木は、まるで木の枝のようにデータを分けていくことで予測を行います。たくさんの決定木を使うので、『ランダムフォレスト』(森)と呼ばれています。それぞれのデータの特徴が、予測にどれくらい影響しているかを見ることができるので、なぜそのような予測になったのかを理解しやすいモデルです。
ランダムフォレストとは

ランダムフォレストは、複数の決定木を組み合わせて、複雑な問題を解く機械学習の手法です。まるで、たくさんの木々が茂る森を想像してみてください。この森全体が、ランダムフォレストを表しています。個々の木は決定木と呼ばれ、それぞれがデータの一部を使って学習します。学習とは、与えられたデータから規則性やパターンを見つけることです。それぞれの木は、学習した結果に基づいて独自の判断を下します。ランダムフォレストの精度は、この多数の決定木の判断を組み合わせることで高まります。個々の木は完璧ではなく、時には間違った判断をすることもあります。しかし、多くの木の判断を多数決でまとめることで、個々の木の誤りを打ち消し、より正確な予測が可能になります。これは、様々な専門家の意見を集約して、より良い結論を導き出す会議のようなものです。個々の専門家は必ずしも正しいとは限りませんが、多様な視点を取り入れることで、より確かな判断ができるのです。ランダムフォレストは、様々な問題に適用できます。例えば、写真に写っている動物が猫か犬かを判別するような分類問題に利用できます。また、過去の売上のデータから将来の売上高を予測する回帰問題にも役立ちます。このように、ランダムフォレストは、データからパターンを学習し、予測を行う強力な手法として、幅広い分野で活用されています。さらに、ランダムフォレストは、どの特徴量が重要かを判断するのにも役立ちます。これは、問題解決に重要な要素を特定するのに役立ち、解釈性を高めます。ランダムフォレストは、複雑な問題を理解し、将来を予測するための、強力で汎用性の高い道具と言えるでしょう。
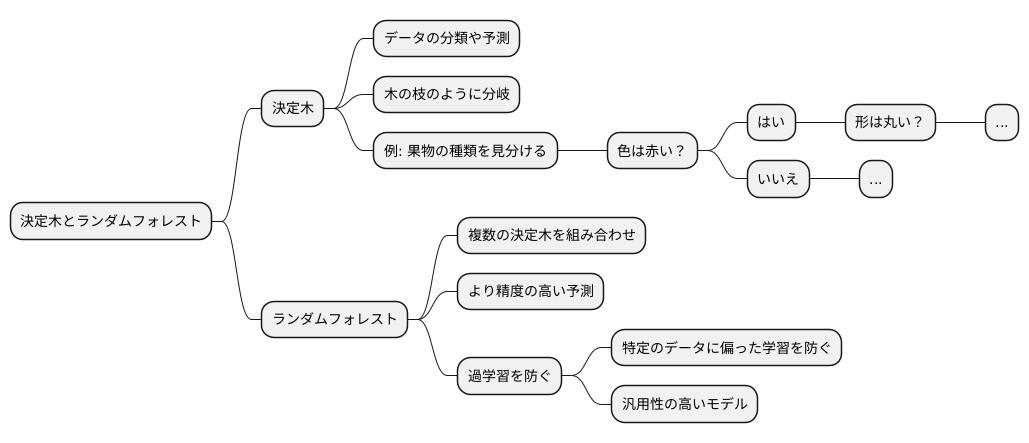
決定木の役割

決定木は、機械学習の中でも、データの分類や予測に用いられる手法のひとつです。まるで木の枝が分かれていくように、データの特徴を段階的に絞り込んでいくことで、最終的な結果を導き出します。この決定木という手法が、ランダムフォレストという、より強力な手法の土台となっています。
例として、果物の種類を見分ける場面を想像してみましょう。目の前に置かれた果物が何なのかを判断するために、いくつか質問を投げかけてみます。「果物の色は赤いですか?」と尋ね、もし「はい」であれば、さらに「形は丸いですか?」と質問を重ねます。これらの質問への答えによって、リンゴ、オレンジ、バナナなど、可能性を絞り込んでいくことができます。これが決定木の基本的な考え方です。
ランダムフォレストは、この決定木を複数組み合わせることで、より精度の高い予測を実現します。まるで森の中にたくさんの木が生えているように、複数の決定木を生成し、それぞれの木に学習させるデータを変えます。さらに、各決定木で使う質問もランダムに選ぶことで、多様な判断基準を持つ木々を育てます。
このように、学習データや質問内容を多様化することで、特定のデータに偏った学習、いわゆる「過学習」を防ぐことができます。過学習とは、特定のデータにのみ最適化されすぎて、未知のデータに対する予測精度が落ちてしまう現象です。ランダムフォレストは、過学習を抑えることで、様々なデータに対しても高い精度で予測できる、汎用性の高いモデルを構築することを可能にします。たくさんの木々が集まることで、森全体として、より正しい判断ができるようになるのです。
ランダム性の重要性

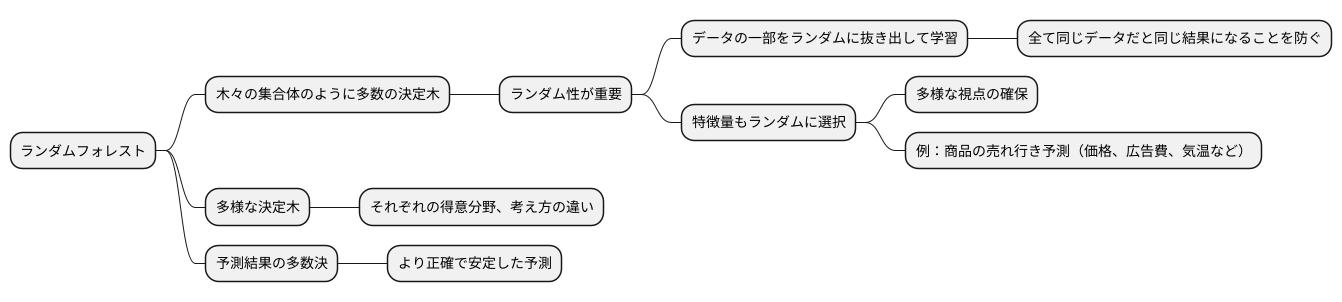
たくさんの木々が集まって森を作るように、たくさんの決定木が集まって予測を行う手法をランダムフォレストと言います。この名前からも想像できるように、ランダムフォレストにはランダム性がとても大切です。
ランダムフォレストは、データから一部を抜き出して学習させることを繰り返すことで、たくさんの決定木を作ります。もし、すべての決定木が全く同じデータを使って学習すると、すべての木が同じような結果を導き出し、多数決をとっても意味がなくなってしまいます。これは、全く同じ意見を持つ人々が集まって議論しても、新しい考えが生まれないのと同じです。
そこで、ランダムフォレストでは、学習データの一部をランダムに選び出して、それぞれの決定木に与えます。これは、会議の参加者をランダムに選ぶようなものです。参加者が異なれば、議論の内容も変わり、様々な視点からの意見が出やすくなります。
さらに、ランダムフォレストは、どの特徴量を使うかもランダムに決定します。たとえば、ある商品の売れ行きを予測する場合、価格、広告費、気温など、様々な特徴量が考えられます。これらの特徴量から、一部をランダムに選び出して、それぞれの決定木に与えます。すべての決定木がすべての情報を持っているのではなく、それぞれが異なる情報を持っていることで、多様な視点が生まれます。
このように、学習データと特徴量の両方にランダム性を持たせることで、様々な決定木が作られます。まるで、それぞれ得意分野や考え方の違う専門家が集まっているようです。そして、これらの決定木の予測結果を多数決でまとめることで、より正確で安定した予測が可能になります。ランダム性は、森を豊かにする多様性と同じように、ランダムフォレストの精度を高める重要な要素なのです。
特徴量の重要度

たくさんの木を使う手法であるランダムフォレストは、予測に役立つ要素の重要度を見えるようにする力を持っています。これは、どの要素が結果に大きな影響を与えるかを判断するのに役立ちます。
例えば、お店でお客さんが何を買うかを予測したいとします。お客さんの年齢、性別、住んでいる地域など、いろいろな要素が考えられます。ランダムフォレストを使うと、これらの要素の中でどれが買い物の行動に一番影響しているかをはっきりさせることができます。
具体的な例を挙げてみましょう。あるお菓子屋さんで、新しいお菓子を売り出すとします。ランダムフォレストを使って、お客さんの年齢、性別、住んでいる地域、年収などの情報から、誰がそのお菓子を買う可能性が高いかを予測します。分析の結果、年齢が最も重要な要素だと分かったとします。若い人ほど新しいお菓子を買う傾向が高いことが分かったのです。
この情報があれば、お菓子屋さんは若い人をターゲットにした宣伝を重点的に行うことができます。例えば、若い人がよく見る雑誌に広告を出したり、若い人が集まる場所にポスターを貼ったりすることができます。また、商品の味やパッケージも若い人の好みに合わせたものにすることができます。
このように、ランダムフォレストは単に予測するだけでなく、予測の理由も教えてくれます。これは、ただ結果を知るだけでなく、その結果に至った過程を理解する上で非常に重要です。この理解に基づいて、より効果的な対策を立てることができるのです。ランダムフォレストは、予測結果とその根拠を共に提供してくれるため、分かりやすく、使いやすい予測手法と言えるでしょう。
| 手法 | 目的 | 説明 | 例 | 利点 |
|---|---|---|---|---|
| ランダムフォレスト | 予測に役立つ要素の重要度を見えるようにする | どの要素が結果に大きな影響を与えるかを判断するのに役立つ | お菓子屋さんで新しいお菓子を売り出す際に、顧客の年齢、性別、住んでいる地域、年収などの情報から、誰がそのお菓子を買う可能性が高いかを予測。年齢が最も重要な要素だと判明。 | 予測結果だけでなく、予測の理由も教えてくれるため、より効果的な対策を立てることができる。 |
様々な応用事例

ランダムフォレストは、様々な分野で活用されている汎用性の高い技術です。その応用範囲は実に幅広く、今後も広がり続けると考えられています。
まず、医療の分野では、病気の診断補助に役立っています。例えば、患者の症状や検査データを入力することで、病気を高い精度で予測することができます。これにより、医師はより早く正確な診断を下すことができ、患者にとって適切な治療方針を決定するのに役立ちます。また、新薬開発の過程においても、効果的な化合物を特定するためにランダムフォレストが活用されています。
金融の分野では、信用リスクの評価にランダムフォレストが用いられています。顧客の属性や過去の取引履歴などのデータから、融資の可否や金利などを判断するのに役立ちます。また、不正な取引を検知するためにも利用されており、クレジットカードの不正利用や金融詐欺などの早期発見に貢献しています。近年、注目を集めているフィンテックの分野においても、ランダムフォレストは中心的な役割を担う技術の一つと言えるでしょう。
さらに、人工知能の様々な分野でもランダムフォレストは活用されています。画像認識の分野では、画像に写っている物体を識別したり、顔認識システムなどで人物を特定したりする際に用いられています。自然言語処理の分野では、文章の分類や感情分析などに活用され、膨大な量の文章データを効率的に処理することを可能にしています。これらの技術は、自動運転や音声認識、機械翻訳など、様々な人工知能技術の基盤を支えています。
このように、ランダムフォレストは、医療、金融、人工知能といった多様な分野で、複雑な問題を解決するための強力な道具として活用されています。そして、データ活用の重要性が高まる現代社会において、その応用範囲は今後ますます広がっていくことが期待されます。
| 分野 | 活用例 |
|---|---|
| 医療 | 病気の診断補助 新薬開発 |
| 金融 | 信用リスクの評価 不正取引の検知 |
| 人工知能 | 画像認識 自然言語処理 |
利点と欠点

ランダムフォレストは、複数の決定木を組み合わせることで、高い予測精度を実現する手法です。多くの利点を持つ反面、いくつか欠点も存在します。まずは利点を見ていきましょう。ランダムフォレストは、高い精度を誇ります。これは、複数の決定木がそれぞれ異なる特徴に基づいて予測を行うことで、単一の決定木よりも頑健な予測が可能になるためです。また、過学習への耐性も高いです。これは、複数の決定木を組み合わせることで、個々の決定木の過学習の影響を抑えることができるためです。さらに、数値データやカテゴリデータなど、様々な種類のデータに適用できることも利点の一つです。加えて、どの特徴量が予測に大きく寄与しているかを示す特徴量の重要度を可視化できるため、モデルの解釈が容易になります。これらの利点から、ランダムフォレストは様々な分野で活用されています。
一方、欠点も存在します。ランダムフォレストは、計算コストが高く、大量のメモリを必要とします。これは、多数の決定木を生成し、それぞれの決定木で計算を行う必要があるためです。特に、扱うデータが膨大な場合、計算時間が非常に長くなり、実用性に欠ける可能性があります。また、モデルの解釈が容易である一方、決定木が多数存在するため、個々の決定木の挙動を詳細に理解することは困難です。つまり、全体としての予測結果は把握しやすいものの、予測に至るまでのプロセスを完全に理解することは難しいと言えるでしょう。そのため、ランダムフォレストを使用する際には、データの規模や計算資源、そして求める解釈のレベルを考慮する必要があります。利点と欠点を理解した上で適切に活用することで、ランダムフォレストは様々な問題解決に大きく貢献する強力な手法となります。
| 項目 | 内容 |
|---|---|
| 利点 | – 高い精度 – 過学習への耐性 – 様々な種類のデータに適用可能 – 特徴量の重要度の可視化 |
| 欠点 | – 計算コストが高い – 大量のメモリを必要とする – 個々の決定木の挙動を詳細に理解することは困難 |