
ランダムフォレスト:多数の樹で森を作る

AIを知りたい
先生、「ランダムフォレスト」ってたくさんの木があって森みたいってイメージでいいんですか?

AIエンジニア
そうだね。たくさんの「決定木」を使って予測するから、森のように例えられるんだよ。ただ、普通の森とは違って、それぞれの木がバラバラに、そして同時に成長していくイメージだね。
AIを知りたい
バラバラに成長するって、どういうことですか?
AIエンジニア
それぞれの木は、与えられたデータの一部だけを使って学習するんだ。それに、木の枝分かれの仕方にも少しランダムな要素を入れる。そうすることで、多様な木ができて、より良い予測ができるようになるんだよ。1本の木だけでは偏った考え方に陥ってしまうかもしれないけれど、たくさんの木で多数決をとることで、偏りを減らして正しい答えに近づけるんだ。
ランダムフォレストとは。
人工知能で使われる『ランダムフォレスト』という言葉について説明します。ランダムフォレストとは、並行して学習させた複数の決定木に予測をさせ、その結果を多数決や平均値でまとめて最終的な答えを出す方法です。ランダムフォレストは、複数のモデルをまとめて使うアンサンブル学習という方法のバギングという種類に分類されます。決定木は一つだけだと学習データの特徴に偏りすぎてしまう欠点がありますが、ランダムフォレストではこの欠点を抑えることができます。
ランダムフォレストとは

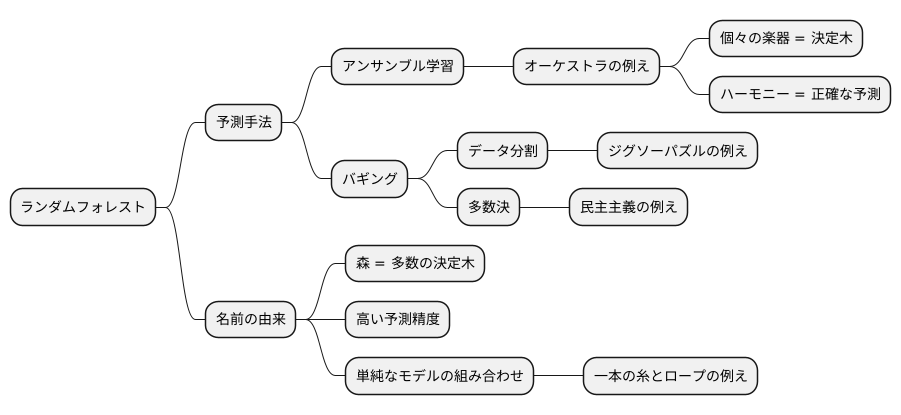
ランダムフォレストは、機械学習の分野でよく使われる予測手法です。たくさんの決定木という簡単な予測モデルを組み合わせて、全体として複雑な予測を可能にする、アンサンブル学習という考え方に基づいています。アンサンブル学習とは、例えるなら、様々な楽器がそれぞれの音色を奏で、全体として美しいハーモニーを作り出すオーケストラのようなものです。ランダムフォレストでは、決定木がそれぞれの楽器の役割を果たし、それぞれの予測結果を統合することで、より正確な予測を実現します。
ランダムフォレストで使われている具体的な方法は、バギングと呼ばれています。バギングは、元のデータをいくつかに分けて、それぞれの部分データから決定木を作ります。まるで、大きな絵をジグソーパズルのように細かく分けて、それぞれのピースから全体像を推測するようなものです。それぞれの決定木は、異なる部分データに基づいて作られるため、少しずつ異なる特徴を捉えます。そして、それぞれの決定木の予測結果を多数決でまとめることで、最終的な予測結果を得ます。多数の意見を聞き、最も多くの支持を得た意見を採用する、いわば民主主義的な方法です。
ランダムフォレストの名前の由来は、森のようにたくさんの決定木を使うことにあります。多数の決定木が複雑に絡み合い、全体として高い予測精度を実現します。一つ一つの決定木は単純な構造で、複雑なデータの予測には不向きです。しかし、ランダムフォレストのようにたくさんの決定木を組み合わせることで、複雑な関係性も捉えることができるようになります。まるで、一本の糸は弱くても、たくさんの糸を束ねると頑丈なロープになるように、単純なモデルを組み合わせることで、強力な予測モデルが生まれるのです。
決定木の弱点を克服

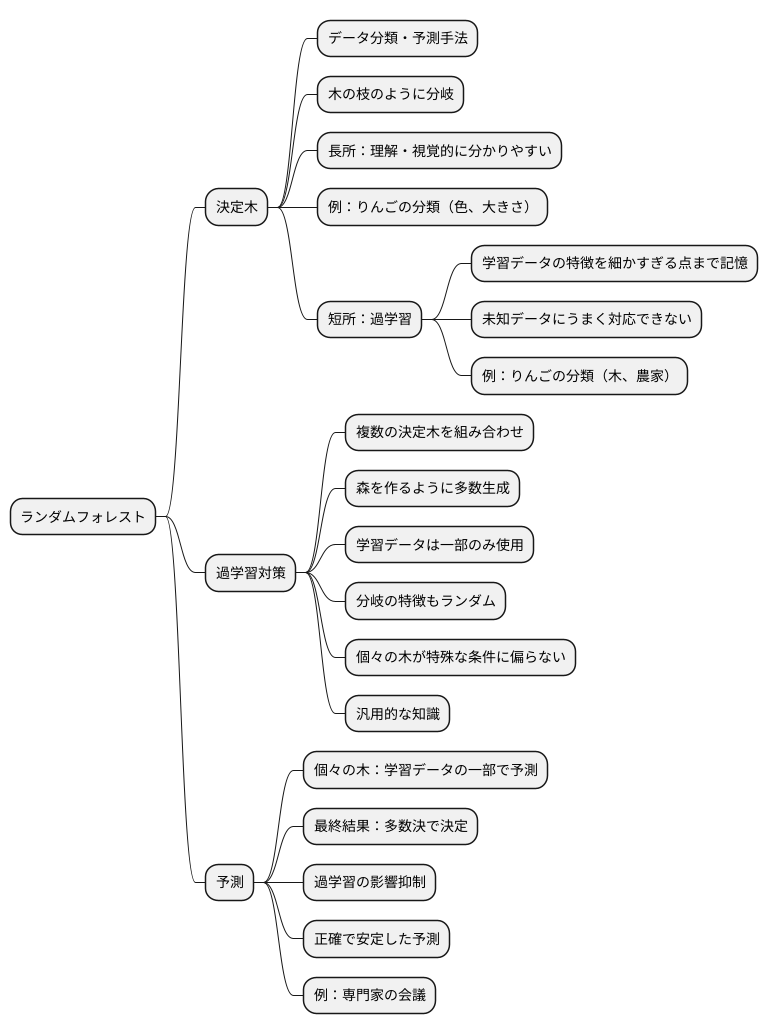
決定木は、データを分類したり予測したりする手法の一つで、その仕組みは木の枝のように分岐していくことから名付けられました。理解しやすく、視覚的に分かりやすいという長所があります。例えるなら、りんごを分類する場合、「色が赤いですか?」「大きさは大きいですか?」といった簡単な質問を繰り返すことで、「これはサンふじです」「これは王林です」と判別していくようなものです。
しかし、決定木には「過学習」という困った弱点があります。これは、学習データの特徴を細かすぎる点まで覚えてしまい、未知のデータにうまく対応できなくなる状態です。りんごの例で言うと、「この木で育った」「この農家の人が育てた」といった、特定のデータセットにだけ当てはまる特殊な条件まで覚えてしまうようなものです。結果として、新しいりんごを見せられても、正しく分類できなくなってしまいます。
この過学習という弱点を克服するために、複数の決定木を組み合わせる「ランダムフォレスト」という手法が用いられます。森を作るように、たくさんの決定木を生成し、それぞれの木に学習させるデータは一部だけとします。さらに、どの特徴で木を分岐させるかもランダムに決めます。こうすることで、個々の木が特殊な条件に偏ることなく、より汎用的な知識を学ぶことができます。
それぞれの木は、学習データから得られた一部の情報に基づいて予測を行います。そして、最終的な予測結果は、多数決のように、多くの木が支持した結果を採用します。個々の木の予測は完璧ではなくても、複数の木が合議することで、過学習の影響を抑え、より正確で安定した予測が可能となります。まるで、様々な専門家が集まって議論し、より良い結論を導き出す会議のようなものです。
このように、ランダムフォレストは、決定木の分かりやすさを保ちつつ、その弱点を克服することで、より高い精度でデータの分類や予測を行うことができる優れた手法と言えるでしょう。
ランダムフォレストの仕組み

たくさんの木を植えて森を作るように、たくさんの決定木を組み合わせることで、複雑な問題を予測する手法があります。これを「ランダムフォレスト」と言います。この手法は、まるで森を作るようにたくさんの決定木を作り、それらの木々の意見をまとめることで最終的な判断を下します。一つ一つの木はそれほど賢くなくても、たくさんの木々の意見を総合することで、驚くほど正確な予測ができます。
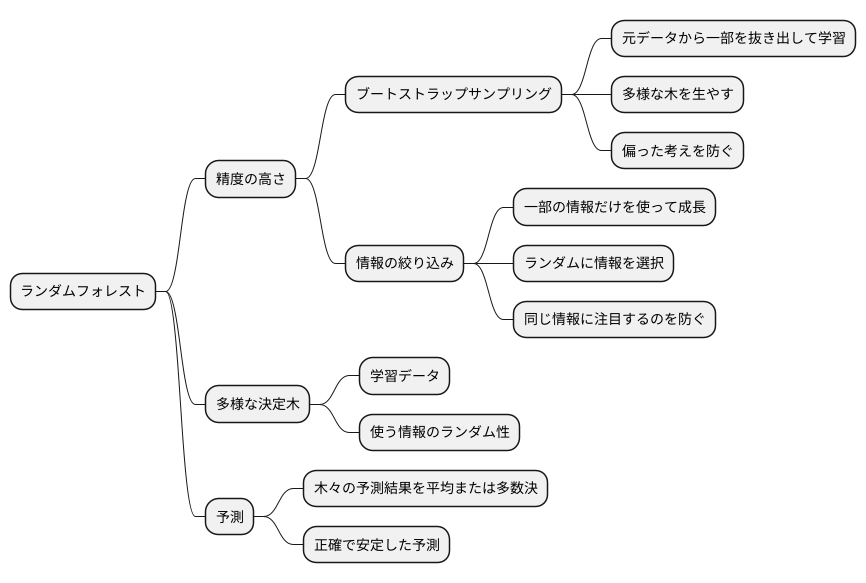
ランダムフォレストの精度の高さは、二つの工夫によって実現されています。一つ目は、学習に使う情報の選び方です。元のデータから一部を抜き出して、それぞれの木に学習させます。これは、同じデータばかり見て偏った考えを持つ木ができないようにするためです。まるで、森全体に多様な木を生やすように、それぞれの木に異なる視点を与えているのです。この仕組を「ブートストラップサンプリング」と言います。
二つ目は、木を作る際に使う情報の絞り込みです。それぞれの木は、与えられた情報のすべてを使うのではなく、一部の情報だけを使って成長します。どの情報を使うかは、木ごとにランダムに決めます。これは、すべての木が同じ情報に注目して同じような形に育ってしまうのを防ぐためです。多様な情報に注目する木々を育てることで、森全体としての予測能力を高めています。
このように、ランダムフォレストは、学習データと使う情報の選び方にランダム性を取り入れることで、多様性のある決定木をたくさん作ります。そして、これらの木々の予測結果を平均したり、多数決を取ったりすることで、より正確で安定した予測を可能にしています。まるで、森全体の知恵を集結させているかのようです。
ランダムフォレストの利点

たくさんの木をまとめて使う、森のような考え方のランダムフォレストには、いくつもの良い点があります。まず、学習しすぎて本来の目的を見失ってしまうことを防ぎやすいです。一つ一つの木は、与えられた情報にぴったり合うように学習しますが、時にそれが行き過ぎて、新しい情報にうまく対応できなくなることがあります。ランダムフォレストでは、たくさんの木を組み合わせることで、この行き過ぎた学習の影響を抑え、新しい情報に対しても安定した結果を出せるようにしています。
次に、高い予測精度もランダムフォレストの大きな魅力です。いろいろな種類の情報にうまく対応できるため、幅広い分野で正確な予測を出すことができます。例えば、病気の診断や商品の売れ行き予測など、様々な場面で役立っています。
さらに、普段見かけないような特殊な情報や、情報が欠けている場合にも強いという特徴があります。一つ一つの木が、これらの特殊な情報や欠けている情報に影響されにくいため、全体としての予測の正確さが保たれます。例えば、健康診断の結果で一部の検査値が抜けていても、他の値から健康状態をある程度予測できるといった具合です。
このように、過学習を防ぎやすく、高い予測精度を持ち、特殊な情報や欠けている情報にも強いランダムフォレストは、情報の分析や機械学習の分野で大変役に立つ方法として広く使われています。複雑な情報の処理や未来の予測に役立つ、頼もしい道具と言えるでしょう。
| メリット | 説明 | 例 |
|---|---|---|
| 過学習しにくい | 多数の決定木を使用することで、個々の木で発生する過学習の影響を抑制し、新しい情報への対応力を向上 | – |
| 高い予測精度 | 様々な種類の情報に対応できるため、幅広い分野で正確な予測が可能 | 病気の診断、商品の売れ行き予測 |
| 特殊な情報や欠損値に強い | 個々の木が特殊な情報や欠損値の影響を受けにくいため、全体としての予測精度が維持される | 一部の検査値が抜けている場合でも健康状態を予測 |
ランダムフォレストの応用

たくさんの木を組み合わせた予測手法であるランダムフォレストは、その汎用性の高さから、実に様々な分野で応用されています。医療、金融、販売促進など、データに基づいた判断が必要な場面で力を発揮しています。
まず、医療分野での活用例を見てみましょう。患者の様々な情報、例えば症状や検査データ、過去の病歴などを基に、ランダムフォレストは病気を予測することができます。また、どの治療法が最も効果的か、患者一人ひとりに合わせた最適な治療方針の決定を支援することも可能です。病気の早期発見や、より効果的な治療の実現に貢献しています。
次に、金融分野では、顧客の信用度を評価する際にランダムフォレストが役立ちます。顧客の年齢や収入、過去の取引履歴といった情報から、融資の可否や金利などを判断する材料を提供します。また、クレジットカードの不正利用など、怪しい取引をいち早く見つけるためにも活用されています。
さらに、販売促進の分野でもランダムフォレストは活躍しています。顧客の過去の購買履歴や興味関心のある商品などを分析することで、顧客が次にどんな商品を買うかを予測したり、一人ひとりに合った商品を推薦したりすることができます。顧客のニーズに合った的確な販売促進活動を行うことで、企業の売り上げ向上に貢献しています。
このように、ランダムフォレストは様々な分野でデータに基づいた的確な判断を支援する、強力な道具として活用されています。今後も、データ活用の重要性が高まるにつれて、ランダムフォレストの活躍の場はさらに広がっていくことでしょう。
| 分野 | ランダムフォレストの活用例 |
|---|---|
| 医療 | ・病気の予測 ・最適な治療方針の決定支援 ・病気の早期発見 ・効果的な治療の実現 |
| 金融 | ・顧客の信用度評価 ・融資の可否や金利の判断 ・クレジットカードの不正利用検知 |
| 販売促進 | ・顧客の購買予測 ・顧客に合った商品推薦 ・的確な販売促進活動による売上向上 |
実装と利用

数多くの木を組み合わせることで、森のように複雑なデータ構造を把握し、高い精度で予測を行う「ランダムフォレスト」は、気軽に利用できる手軽さと、優れた予測能力から、幅広い分野で活用されています。その実装方法と効果的な利用方法について解説します。
ランダムフォレストを使うための環境構築は非常に簡単です。例えば、「さいきっと学ぶ」のような機械学習専用の道具集めを使えば、複雑な設定をすることなく、すぐにランダムフォレストを試すことができます。これらの道具集めは、ランダムフォレストの学び方や予測の仕方を教えてくれる便利な機能を備えており、誰でも簡単に使い始めることができます。
ランダムフォレストをより効果的に使うためには、木々の数や情報の選び方といった、いくつかの調整項目を適切に設定する必要があります。これらの調整項目を細かく調整することで、予測の正確さをさらに高めることができます。しかし、調整項目の中には、専門的な知識が必要となるものもあります。そのため、実際にランダムフォレストを使う場合には、それぞれの調整項目がどのような意味を持つのかを理解し、データに合わせて適切な値を設定することが重要です。
また、ランダムフォレストに与えるデータの状態も、予測の正確さに大きく影響します。もしデータに欠けている部分や異常な値が含まれている場合は、あらかじめ適切な方法で処理しておく必要があります。例えば、欠けている部分は平均値で補ったり、異常な値は取り除いたりすることで、予測の正確さを向上させることができます。
ランダムフォレストは強力な予測手法ですが、その性能はデータの質や調整項目の設定に大きく左右されます。そのため、ランダムフォレストを使う際には、これらの要素に注意深く配慮しながら、データに合った適切な設定を見つけることが重要です。そうすることで、ランダムフォレストの真価を発揮し、高精度な予測結果を得ることができるでしょう。
| 項目 | 説明 |
|---|---|
| 概要 | ランダムフォレストは、複数の木を組み合わせて複雑なデータ構造を把握し、高精度な予測を行う手法。手軽さと予測能力から幅広い分野で活用されている。 |
| 環境構築 | 機械学習専用の道具集め(例:「さいきっと学ぶ」)を使えば、簡単に試せる。 |
| 効果的な利用方法 | 木々の数や情報の選び方など、調整項目を適切に設定する必要がある。専門知識が必要な項目もあるため、理解した上でデータに合わせた値を設定することが重要。 |
| データの前処理 | 欠損値や異常値は、平均値で補完したり、取り除いたりするなど、前処理が必要。 |
| 注意点 | 性能はデータの質や調整項目の設定に左右されるため、注意深く配慮する必要がある。 |