
ランダムフォレスト:多数決で予測精度を高める

AIを知りたい
先生、『ランダムフォレスト』って、複数の木を使うんですよね?たくさんの木を植えるみたいにイメージすればいいんですか?

AIエンジニア
そうですね、たくさんの『決定木』を使います。ただ、植えるというよりは、それぞれ違う形の決定木をたくさん用意するイメージです。それぞれが違う判断をする木をたくさん用意することで、より正しい判断ができるようになります。
AIを知りたい
違う形の決定木って、どういうことですか?
AIエンジニア
たとえば、あるリンゴがおいしいかどうかを判断するのに、色、大きさ、香りなどで判断する木をそれぞれ用意するようなものです。それぞれの木は異なる特徴で判断するので、全体として見ると、より正確に美味しいリンゴかどうかが分かります。一つの木だと間違えることも、複数の木で判断すれば、より正しい答えに近づける、というわけです。
ランダムフォレストとは。
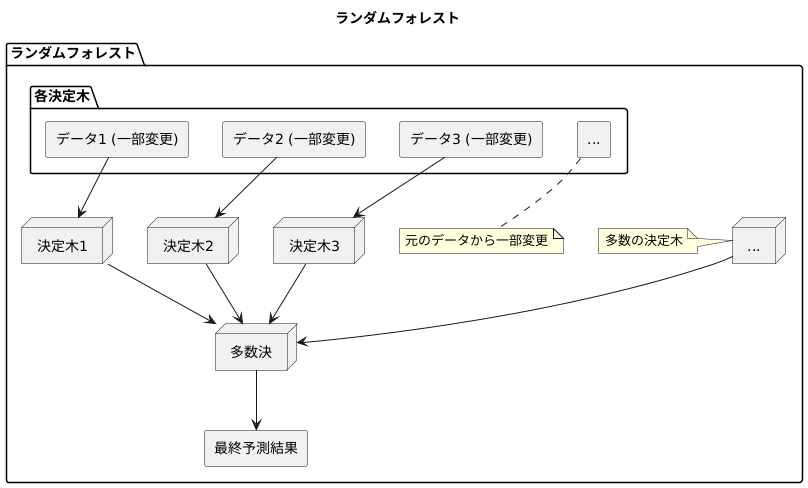
複数の決定木を使って予測する『ランダムフォレスト』という人工知能の用語について説明します。ランダムフォレストでは、並行して学習させたたくさんの決定木それぞれに予測させ、その結果を多数決や平均値でまとめて最終的な答えを出します。ランダムフォレストは、複数のモデルを組み合わせるアンサンブル学習という方法の中でも、バギングと呼ばれる種類に分類されます。決定木は一つだけだと学習データの特徴に過剰に反応してしまい、未知のデータへの予測精度が下がるという欠点がありますが、ランダムフォレストを使うことでこの欠点を抑えることができます。
ランダムフォレストとは

「ランダムフォレスト」とは、たくさんの「決定木」と呼ばれる予測モデルを組み合わせて、より正確な予測を行う機械学習の手法です。まるで森のようにたくさんの木が生えている様子から、「ランダムフォレスト」という名前が付けられています。
一つ一つの木にあたるのが「決定木」です。決定木は、質問を繰り返すことで、答えを絞り込んでいくような仕組みを持っています。例えば、果物を分類する場合、「色は赤いですか?」「大きさはどれくらいですか?」といった質問を繰り返すことで、「りんご」「みかん」「いちご」など、答えを導き出します。
ランダムフォレストは、この決定木をたくさん用意し、それぞれの木に学習させます。しかし、すべての木に同じデータを学習させてしまうと、似たような木ばかりができてしまい、予測の精度はあまり向上しません。そこで、ランダムフォレストでは、それぞれの木に学習させるデータを少しだけ変化させます。元のデータから一部のデータを取り出したり、注目する特徴をランダムに選んだりすることで、多様な木を育てます。
それぞれの木が学習を終えると、予測したいデータに対して、すべての木が予測を行います。そして、それぞれの木の予測結果を多数決でまとめることで、最終的な予測結果を導き出します。
このように、たくさんの木を育て、それぞれの木が異なる視点から予測を行うことで、一つだけの木を使うよりも、より正確で安定した予測が可能になります。また、一部のデータが不足していたり、質が悪かったりしても、他の木が補完してくれるため、データの欠陥に強いという利点もあります。そのため、様々な分野で活用されている、信頼性の高い予測手法と言えるでしょう。
決定木の集合体

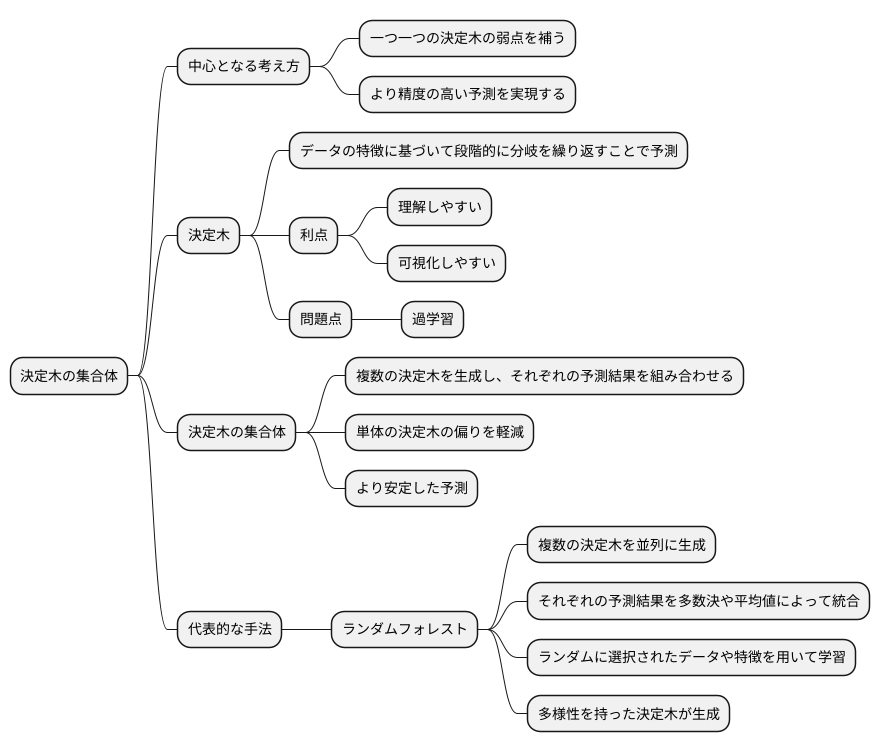
決定木の集合体とは、読んで字のごとく、複数の決定木を組み合わせた予測手法のことです。中心となる考え方は、一つ一つの決定木の弱点を補い、より精度の高い予測を実現することにあります。
まず、決定木という手法について簡単に説明します。決定木は、データの特徴に基づいて段階的に分岐を繰り返すことで予測を行います。例えるなら、木の枝が伸びていくように、様々な条件によってデータが分類されていくイメージです。この方法は、理解しやすく、可視化しやすいという利点があります。しかし、学習データに過剰に適応してしまう「過学習」という問題を抱えています。まるで、学習データだけを完璧に覚えた優等生が、応用問題になると全く解けなくなるようなものです。
この過学習の問題を解決するために、決定木の集合体という考え方が生まれました。複数の決定木を生成し、それぞれの予測結果を組み合わせることで、単体の決定木の偏りを軽減し、より安定した予測を可能にします。これは、様々な専門家の意見を参考に意思決定を行うのと同じです。一人の専門家の意見だけを聞くよりも、複数の専門家の意見を総合的に判断する方が、より正確な結論を導き出せる可能性が高まります。
代表的な決定木の集合体の手法として、ランダムフォレストが挙げられます。ランダムフォレストは、複数の決定木を並列に生成し、それぞれの予測結果を多数決や平均値によって統合することで最終的な予測を行います。それぞれの決定木は、ランダムに選択されたデータや特徴を用いて学習されるため、多様性を持った決定木が生成されます。こうして作られた多様な決定木たちが、互いに弱点を補い合い、より精度の高い予測を実現するのです。まるで、様々な個性を持った専門家集団が、それぞれの得意分野を活かして協力することで、より難しい問題にも対応できるようになる、そんなイメージです。
ランダム性の重要性

ランダム性という言葉を聞くと、計画性がない、いい加減といった印象を持つ方もいるかもしれません。しかし、機械学習の世界、特にランダムフォレストという手法において、ランダム性は非常に重要な役割を担っています。ランダムフォレストは、多数の決定木を組み合わせることで、高精度な予測を実現する手法です。まるで森のようにたくさんの決定木が集まっていることから、この名前が付けられています。
一つ一つの決定木は、データを元に物事を判断する基準を学習していきます。もし、すべての決定木が全く同じデータ、同じ特徴で学習してしまうとどうなるでしょうか。まるで同じ教科書、同じ先生で勉強する生徒のように、皆が同じ考え方になり、多様性が失われてしまいます。その結果、似たような決定木ばかりができてしまい、予測の精度は上がりません。
そこで登場するのがランダム性の考え方です。ランダムフォレストでは、それぞれの決定木に学習させるデータと特徴をランダムに選択します。つまり、一部のデータだけを使ったり、特定の特徴だけに着目したりすることで、個々の決定木に個性を持たせるのです。料理に例えると、同じ食材、同じ調味料で作った料理は、どれも似たような味になってしまいます。しかし、食材や調味料を多様に変えることで、様々な風味を楽しむことができます。ランダムフォレストもこれと同じで、ランダム性によって多様な決定木を生み出し、森全体としての予測精度を高めているのです。
このように、ランダムフォレストにおいて、ランダム性は予測精度向上に欠かせない要素となっています。ランダム性があるからこそ、様々な視点から物事を捉え、より正確な判断を下すことができるのです。
バギングという手法

たくさんの木を植えて森を作るように、複数の決定木を組み合わせることで、より精度の高い予測を行う手法があります。これを「バギング」と呼びます。正式には「ブートストラップ・アグリゲーティング」と言いますが、一般的にはバギングと呼ばれています。
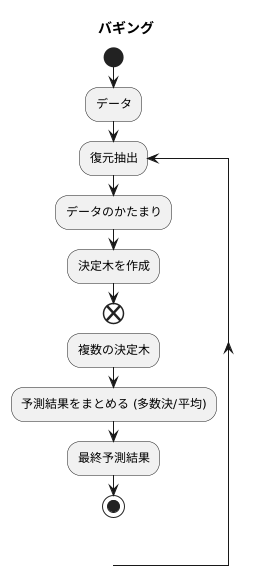
この手法は、データを繰り返し抜き出して、複数の小さなデータのかたまりを作るところから始まります。袋の中にたくさんの玉が入っていて、そこから一つ玉を取り出して記録し、また袋に戻す。これを繰り返すことで、同じ玉が複数回選ばれることもあれば、全く選ばれない玉もあるかもしれません。このように、同じデータを取り出す可能性を許容した抽出方法を「復元抽出」と呼びます。
バギングでは、この復元抽出を使って元のデータと同じサイズのデータのかたまりを複数作ります。そして、それぞれのデータのかたまりを使って決定木を作ります。それぞれの木は、異なるデータで学習するので、異なる特徴を捉えることができます。まるで、様々な専門家に見解を求めるように、多様な決定木を作ることができるのです。
こうしてできた複数の決定木は、それぞれが独自の判断を行います。最終的な予測結果は、これらの決定木の予測結果をまとめて、多数決のように最も多かった予測を採用します。あるいは、数値を予測する場合は、それぞれの木の予測結果の平均値を使うこともあります。
バギングは、この多数決方式によって、単一の決定木よりもより安定した、精度の高い予測を実現します。一つの木が間違った判断をしてしまっても、他の木が正しい判断をしていれば、最終的な予測は正しいものになる可能性が高くなります。まるで、たくさんの人の意見を聞くことで、偏った考えに陥ることなく、より正しい結論を導き出すことができるようにです。
ランダムフォレストは、このバギングという手法を基本として、さらに改良を加えた手法です。バギングによって、複数の決定木に多様性を持たせることで、過学習を防ぎ、より精度の高い予測を実現しているのです。
過学習への対策

機械学習では、学習に使ったデータに対しては非常に高い精度を示す一方で、新たなデータに対する予測精度が低いという問題が発生することがあります。これを過学習と呼びます。例えるなら、特定の教科書の内容だけを完璧に暗記した生徒は、教科書の内容を問われれば満点を取れるでしょう。しかし、その教科書の範囲外の応用問題が出されると、途端に解けなくなってしまう、といった状態です。これは、教科書の内容に特化しすぎて、学習の本質を理解できていないことが原因です。
決定木という手法は、この過学習を起こしやすい性質を持っています。決定木は、データをいくつかの特徴で段階的に分類していくことで予測モデルを構築します。しかし、あまりに細かく分類しすぎると、学習データの些細な特徴まで捉えてしまい、新たなデータに対応できなくなってしまいます。
この過学習を防ぐ方法の一つとして、ランダムフォレストという手法があります。ランダムフォレストは、複数の決定木を生成し、それらの予測結果を統合することで、より精度の高い予測を行います。これは、様々な分野の専門家の意見をまとめることで、より良い判断を下せるという考え方に似ています。一人の専門家の意見は、その専門家の経験や知識に偏っている可能性があります。しかし、多くの専門家の意見を総合すれば、個々の偏りを打ち消し合い、より客観的で正確な判断を下すことができます。
ランダムフォレストも同様に、複数の決定木を生成することで、個々の決定木の偏りを軽減します。それぞれの決定木は、異なるデータや特徴に基づいて学習するため、多様な視点を反映した予測が可能になります。これらの予測結果を多数決や平均値で統合することで、過学習を抑え、未知のデータに対しても高い予測精度を実現できるのです。
多様な活用事例

ランダムフォレストは、様々な分野で役立つ、精度の高い予測モデルです。多くの木を組み合わせることで、複雑な関係も捉え、安定した結果を生み出します。
医療の現場では、患者の状態を詳しく把握し、病気の診断を助けるために使われています。例えば、様々な検査データや症状を入力することで、病気を特定したり、重症度を予測したりすることが可能です。これにより、医師はより的確な診断と治療方針を決定することができます。
金融業界では、顧客の信用リスク評価に役立っています。過去の取引履歴や収入、資産状況などのデータから、顧客が将来返済不能になる確率を予測します。これにより、金融機関は貸し倒れリスクを減らし、安全な融資を行うことができます。また、普段とは異なる取引パターンを検知することで、不正利用の防止にも貢献しています。
販売促進の分野でも、ランダムフォレストは顧客の行動予測に活用されています。過去の購入履歴や閲覧履歴、年齢や性別などの情報から、顧客がどの商品に興味を持つのか、どれくらいの金額を使うのかを予測します。この予測に基づいて、効果的な販売戦略を立てたり、顧客一人ひとりに合わせた商品のおすすめを行うことが可能になります。
このように、ランダムフォレストは、データ分析が必要な様々な場面で、精度の高い予測を提供する強力な道具として使われています。医療、金融、販売促進以外にも、製造業や交通、環境問題など、幅広い分野での活用が進んでおり、今後もその応用範囲は広がっていくと期待されています。
| 分野 | 活用例 | 効果 |
|---|---|---|
| 医療 | 病気の診断、重症度予測 | 的確な診断と治療方針の決定 |
| 金融 | 信用リスク評価、不正利用の防止 | 貸し倒れリスクの軽減、安全な融資 |
| 販売促進 | 顧客の行動予測、商品のおすすめ | 効果的な販売戦略、顧客満足度の向上 |
| その他 | 製造業、交通、環境問題など | 幅広い分野での活用 |