
虹色の強化学習:Rainbow

AIを知りたい
先生、「レインボー」って一体どんなものなんですか?AIの深層学習と何か関係があるんですか?

AIエンジニア
いい質問だね!レインボーは、2017年に開発された、ゲームなどでAIが上手に学習するための、より効率的な方法なんだ。7つの優れた学習方法を組み合わせているのが特徴だよ。
AIを知りたい
7つの方法を組み合わせることで、何か良いことがあるんですか?
AIエンジニア
もちろん!それぞれの学習方法の弱点をお互いに補い合うことで、より早く、より賢く学習できるようになるんだ。だから、レインボーは個々の学習方法よりも高いパフォーマンスを示すんだよ。
Rainbowとは。
人工知能の分野で使われる『レインボー』という用語について説明します。レインボーは、2017年に作られた、深く学ぶ強化学習の手法です。この手法は、強化学習の基本的な手法であるDQNだけでなく、二重DQN、決闘ネットワーク、多段階学習、ノイズ入りネットワーク、カテゴリーDQN、優先順位付き経験再生といった、7つの要素を組み合わせたものです。その結果、レインボーはこれらの個々の要素よりも高い性能を発揮します。
虹の七つの構成要素

虹のように美しい七色に例えられる、画期的な学習手法があります。それは「虹(Rainbow)」と呼ばれる、人工知能の学習能力を飛躍的に向上させる技術です。この手法は、まるで虹の七色のように、七つの異なる要素を巧みに組み合わせることで、単独の手法では到達できない高い学習効果を実現しています。
一つ目の要素は「DQN」と呼ばれる、行動の価値を学習する基礎的な手法です。次に、「二重DQN」は、行動価値の過大評価という問題点を解消し、より正確な学習を可能にします。三つ目の「決闘網」は、状態の価値と行動の優位性を分けて学習することで、効率的な学習を実現します。
四つ目の「多段階学習」は、将来の報酬を予測することで、より長期的な視点での学習を促します。そして、「雑音網」は、行動にランダムな要素を加えることで、多様な行動を試みることを促進します。六つ目の「分類DQN」は、行動価値を確率分布として表現することで、より精緻な学習を可能にします。
最後に、「優先順位付き経験再生」は、過去の経験の中から重要なものを優先的に学習することで、学習効率を格段に向上させます。これらの七つの要素が互いに補完し合い、相乗効果を発揮することで、「虹」は、驚くべき学習能力を実現しているのです。一つ一つの要素を深く理解することで、この画期的な手法の真価が見えてきます。
| 要素名 | 説明 |
|---|---|
| DQN | 行動の価値を学習する基礎的な手法 |
| 二重DQN | 行動価値の過大評価問題を解消し、より正確な学習を可能にする |
| 決闘網 | 状態の価値と行動の優位性を分けて学習し、効率的な学習を実現 |
| 多段階学習 | 将来の報酬を予測することで、より長期的な視点での学習を促す |
| 雑音網 | 行動にランダムな要素を加えることで、多様な行動を試みることを促進 |
| 分類DQN | 行動価値を確率分布として表現することで、より精緻な学習を可能にする |
| 優先順位付き経験再生 | 過去の経験の中から重要なものを優先的に学習することで、学習効率を向上させる |
基本手法:ディープキューネットワーク

深層学習を使った意思決定方法の一つに、深層評価学習網(ディープキューネットワーク、略してDQN)というものがあります。DQNは、人間の脳の神経回路網を模倣した数理モデルであるニューラルネットワークを使って、様々な行動の価値を数値で評価し、最も価値の高い行動を選び出す仕組みです。
例えば、ゲームを考えてみましょう。ゲームの場面、つまり画面に映っている状況をニューラルネットワークに入力すると、各行動(例えば、右に移動、左に移動、ジャンプなど)の価値が数値で出力されます。DQNはこの出力された数値に基づいて、最も高い価値を持つ行動を選択します。
DQNの最大の特徴は、過去の経験から学習できる点です。過去のゲームのプレイ記録、つまりどの場面でどの行動を選択し、どのような結果になったかをニューラルネットワークに学習させます。そうすることで、DQNは未来の行動を予測し、より良い結果につながる行動を選択できるようになります。例えば、過去の経験から「敵に近づくとダメージを受ける」ことを学習すれば、DQNは敵に近づく行動の価値を低く評価し、敵から離れる行動を選択するようになるでしょう。
DQNは、ゲームのような複雑な状況での意思決定において、革新的な成果をあげました。しかし、DQN単体では限界もあり、更なる改良が必要でした。そこで、虹(レインボー)と呼ばれる手法が登場します。虹は、DQNを土台としつつ、他の様々な手法の長所を取り入れることで、DQNの限界を克服しようと試みた、より高度な意思決定方法です。DQNは虹の重要な構成要素であり、虹の理解にはDQNの理解が不可欠です。
改良型ディープキューネットワーク

深層学習を用いた強化学習手法の一つである深層キューネットワーク(DQN)は、画期的な手法として注目を集めましたが、いくつかの弱点も抱えていました。そこで、DQNの性能を向上させるために、様々な改良型が開発されました。ここでは、代表的な改良点とその効果について解説します。まず、DQNが行動の価値を過大評価してしまう問題に対処するために、ダブルDQNが開発されました。DQNでは、同じネットワークが行動選択と価値評価の両方を行うため、過大評価が生じやすくなっていました。ダブルDQNは、行動選択と価値評価に異なるネットワークを用いることで、この問題を軽減し、より正確な学習を可能にしました。
次に、デュエリングネットワークは、状態の価値と、その状態における各行動の優位性を分けて学習します。状態の価値とは、その状態が良い状態なのか悪い状態なのかを表す尺度です。一方、行動の優位性とは、その状態においてどの行動が他の行動より優れているかを表す尺度です。これらの値を分けて学習することで、より効率的に学習を進めることができます。例えば、ある状態の価値が低い場合、その状態における全ての行動の価値も低くなる傾向があります。デュエリングネットワークでは、状態の価値を一度学習すれば、その状態における各行動の価値を個別に学習する必要がないため、学習の効率が向上します。
さらに、マルチステップラーニングは、将来の報酬を考慮することで、より長期的な視点での行動選択を可能にします。DQNでは、次のステップの報酬のみを考慮して学習を進めていましたが、マルチステップラーニングでは、複数ステップ先の報酬まで考慮します。これにより、目先の報酬にとらわれず、長期的に見てより良い結果につながる行動を選択できるようになります。例えば、迷路を解くタスクにおいて、ゴールまでの最短経路を学習するためには、複数ステップ先の報酬を考慮する必要があります。
これらの改良点は、DQNの弱点を補強し、Rainbowと呼ばれる統合型の深層強化学習手法の学習能力を向上させる上で重要な役割を果たしています。各改良点は単独でも効果を発揮しますが、組み合わせて用いることで、相乗効果が生まれ、さらに高度な学習を実現できます。これらの改良により、深層強化学習は様々な分野で応用され、目覚ましい成果を上げています。
| 改良手法 | 課題 | 解決策 | 効果 |
|---|---|---|---|
| ダブルDQN | 行動価値の過大評価 | 行動選択と価値評価に異なるネットワークを使用 | より正確な学習 |
| デュエリングネットワーク | 状態価値と行動優位性の学習の非効率性 | 状態価値と行動優位性を分けて学習 | 学習の効率化 |
| マルチステップラーニング | 短期的な視点での行動選択 | 将来の報酬(複数ステップ先まで)を考慮 | 長期的な視点での行動選択 |
更なる改良

学習の向上を目指す様々な手法を組み合わせることで、人工知能は複雑な課題にも対応できるようになります。その一つとして、計算過程にわざと揺らぎを加える「ノイジーネットワーク」という手法があります。揺らぎを加えることで、これまでとは異なる行動を試すようになり、未知の状況でもより良い行動を見つける可能性を広げます。これは、まるで迷路で行き止まりにぶつかったときに、少しだけ違う道を探してみるようなものです。
また、「カテゴリカルDQN」は、行動の価値を単なる数値ではなく、確率分布として表現します。例えば、ある行動が良い結果につながる確率が高いのか、低いのかだけでなく、どの程度の確率でどのくらい良い結果になるのかを予測します。これにより、よりきめ細やかな情報に基づいて行動を選択することが可能になります。
さらに、「優先度付き経験再生」は、過去の経験の中から特に重要なものを選んで重点的に学習する手法です。人工知能は、成功や失敗といった過去の経験から学習しますが、すべての経験が同じように重要とは限りません。大きな失敗や予想外の成功といった重要な経験を優先的に学習することで、学習効率を大幅に向上させることができます。
これらの手法は、従来の手法だけでは難しかった学習の向上を実現します。そして、「レインボー」と呼ばれる手法は、これらの手法を組み合わせることで、様々な状況や課題に柔軟に対応できる高い能力を実現しています。まるで七色の虹のように、様々な手法を組み合わせることで、より高度な人工知能を実現できるのです。
| 手法名 | 概要 | 例え |
|---|---|---|
| ノイジーネットワーク | 計算過程にわざと揺らぎを加えることで、新たな行動を試す。 | 迷路で行き止まりにぶつかったときに、少しだけ違う道を探してみる。 |
| カテゴリカルDQN | 行動の価値を確率分布として表現し、よりきめ細やかな情報に基づいて行動を選択する。 | 行動が良い結果につながる確率だけでなく、どの程度の確率でどのくらい良い結果になるのかを予測する。 |
| 優先度付き経験再生 | 過去の経験の中から特に重要なものを選んで重点的に学習する。 | 大きな失敗や予想外の成功といった重要な経験を優先的に学習する。 |
| レインボー | 上記3つの手法を組み合わせ、様々な状況や課題に柔軟に対応できる高い能力を実現。 | 七色の虹のように、様々な手法を組み合わせることで、より高度な人工知能を実現する。 |
総合的な学習効果

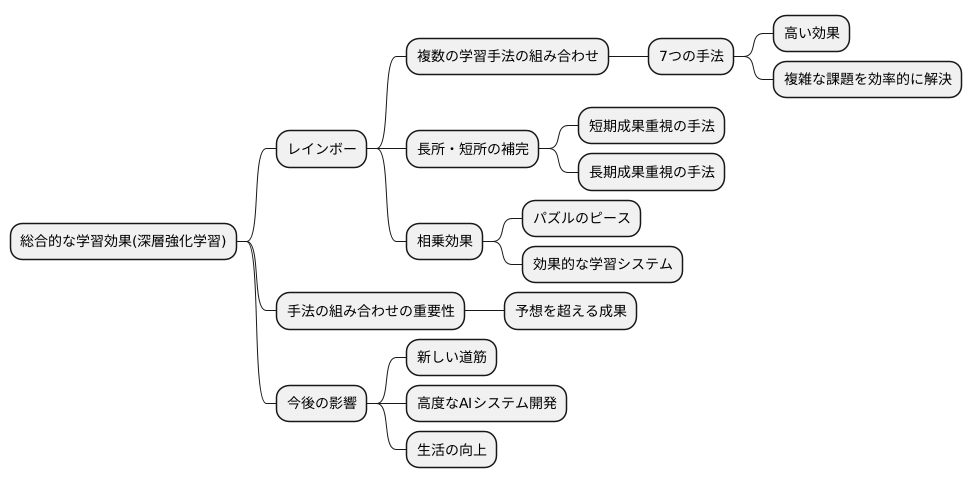
総合的な学習効果について説明します。深層強化学習という分野において、複数の学習手法を組み合わせることで、単独の手法を用いるよりも高い効果が得られることが実証されています。この手法の代表例として「レインボー」という手法が注目されています。レインボーは、七つの異なる学習手法を巧みに組み合わせることで、複雑な課題を効率的に解決し、高い成果を上げています。
レインボーは、まるで虹のように複数の色(手法)が重なり合うことで、より鮮やかな色彩(高い学習効果)を生み出します。それぞれの学習手法には、もちろん得意な分野と苦手な分野が存在します。例えば、ある手法は、短期的な成果を上げるのが得意ですが、長期的な視点が不足しているかもしれません。また、別の手法は、じっくりと学習を進めることで高い精度を実現しますが、学習に時間がかかるという欠点を持つかもしれません。レインボーは、これらの手法を組み合わせることで、それぞれの長所を生かしつつ、短所を補い合う相乗効果を生み出します。まるで、パズルのピースのように、それぞれの学習手法が組み合わさることで、全体としてより効果的な学習システムが構築されるのです。
レインボーの成功は、深層強化学習という分野において、手法の組み合わせの重要性を改めて示すものです。一つの手法に固執するのではなく、複数の優れた手法を組み合わせることで、予想を超える成果を生み出す可能性があることを示唆しています。そして、このレインボーの画期的なアプローチは、様々な課題を解決するための新しい道筋を示すものとして、今後の研究開発に大きな影響を与えると考えられています。人工知能技術の発展において、レインボーは重要な一歩となるでしょう。今後、レインボーの考え方を応用することで、さらに高度な人工知能システムが開発され、私たちの生活をより豊かにすることが期待されます。
将来への展望

深層強化学習という分野において、レインボーと呼ばれる技術は一つの大きな成果と言えるでしょう。しかし、これは単なる終着点ではなく、新たな発展への始まりでもあります。レインボーを構成する要素の一つ一つをさらに磨き上げたり、他の新しい方法と組み合わせることで、より高度な学習の仕組みを作ることができると期待されています。
レインボーはゲームの世界だけでなく、ロボットの制御や自動運転といった様々な分野での活用が期待されています。複雑な状況の中で判断を下したり、機器を制御したりする場面において、レインボーが持つ考え方は、革新的な技術を生み出す可能性を秘めているのです。例えば、ロボットが予測できない環境変化に柔軟に対応したり、自動運転車が複雑な交通状況の中で安全な走行を実現したりするといった未来が想像できます。
レインボーの技術は、人工知能が自ら学習し、高度な問題解決能力を獲得するための重要な一歩となるでしょう。今後の研究開発によって、レインボーがどのように進化し、社会にどのような貢献をもたらすのか、多くの注目が集まっています。例えば、医療分野では、病気の診断や治療方針の決定を支援するシステムの開発に役立つかもしれません。また、製造業では、工場の生産ラインを最適化し、効率を高めることに貢献する可能性もあります。
人工知能の発展において、レインボーは重要な役割を果たすと考えられています。研究者や技術者は、レインボーの持つ可能性を最大限に引き出すために、更なる研究開発に情熱を注いでいます。レインボーの進化は、私たちの生活をより豊かに、より便利にしてくれる未来への希望となるでしょう。今後、レインボーがどのように進化を遂げ、社会に貢献していくのか、期待が高まります。
| 分野 | レインボーの応用 | 期待される効果 |
|---|---|---|
| ゲーム | 高度な学習 | – |
| ロボット制御 | 複雑な状況での判断、機器制御 | 予測できない環境変化への柔軟な対応 |
| 自動運転 | 複雑な交通状況での安全な走行 | – |
| 医療 | 病気の診断、治療方針決定支援 | – |
| 製造業 | 工場の生産ライン最適化 | 効率向上 |