
Q学習:試行錯誤で学ぶAI

AIを知りたい
先生、「Q学習」って難しそうでよくわからないんです。簡単に説明してもらえますか?

AIエンジニア
そうだね。「Q学習」は、コンピュータに試行錯誤を通じて学習させる方法の一つだよ。ゲームを例に考えてみよう。各場面でどの行動をとるのが一番良いかを、コンピュータが自分で学習していくんだ。そのために、「Qテーブル」というものを使って、各場面での行動の価値を記録していくんだよ。
AIを知りたい
「Qテーブル」って、どんなものですか?
AIエンジニア
ゲームの場面ごとに、それぞれの行動に点数を付けていく表のようなものだよ。例えば、ある場面で「右に進む」という行動の点数が10点、「左に進む」という行動の点数が5点だとすると、コンピュータは10点の方の「右に進む」という行動を選びやすくなるんだ。そして、行動した結果に応じて点数を調整していくことで、最適な行動を学習していくんだよ。
Q学習とは。
人工知能の分野でよく使われる言葉に「キュー学習」というものがあります。これは、試行錯誤を通じて学習していく方法の一つです。キュー学習では、それぞれの状況でどんな行動をとるべきか、その価値を記録した表(キューテーブル)を持っています。そして、行動の結果として得られた報酬や、将来の報酬をどのくらい重視するかを表す割引率などを用いて、予測とのずれ(TD誤差)をできるだけ小さくするように学習を進め、その表の価値を更新していきます。
はじめに

人工知能の分野では、機械に自ら考え行動することを目指した研究が盛んです。その中で、試行錯誤を通して学習する強化学習という方法が注目を集めています。
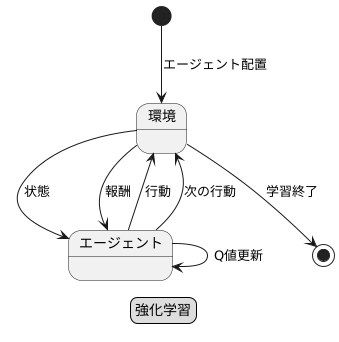
強化学習とは、あたかも人間が様々な経験を通して学習するように、機械にも経験を通して学習させようという考え方です。具体的には、学習する主体であるエージェントをある環境の中に置き、そこで様々な行動を取らせます。そして、その行動に対して環境から報酬と呼ばれる評価が返され、エージェントはその報酬を基に、より良い行動を学習していきます。
この強化学習の中でも、Q学習は特に重要な手法の一つです。Q学習では、エージェントは現在の状態と行動の組み合わせに対して、将来得られるであろう報酬の合計値を予測します。この予測値をQ値と呼びます。エージェントは、様々な行動を試しながら、それぞれの行動に対するQ値を更新していきます。そして、Q値が最大となる行動を選択することで、最適な行動を見つけ出すのです。
例えるなら、迷路の中でゴールを目指す状況を考えてみましょう。エージェントは、現在位置から上下左右のいずれかに進むことができます。それぞれの移動に対して、ゴールに近づく場合は正の報酬、遠ざかる場合は負の報酬が与えられるとします。エージェントは、最初はどの道がゴールへ繋がるか全く知りません。しかし、何度も迷路に挑戦し、報酬を得ることで、徐々にゴールへの道筋を学習していきます。最初はランダムに動いていたエージェントも、学習が進むにつれて、より効率的にゴールを目指せるようになるのです。
このように、Q学習は試行錯誤を通して最適な行動を学習する強力な手法であり、ゲームの攻略やロボットの制御など、様々な分野で応用されています。その可能性は大きく、今後の発展が期待されます。
Q学習の仕組み

「Q学習」は、試行錯誤を通じて学習する仕組みです。まるで迷路を探索するネズミのように、様々な行動を試しながら、より良い結果につながる行動を覚えていきます。この学習の中心となるのが「Q表」と呼ばれる表です。この表は、エージェント(学習を行う者)が置かれた状況(状態)と、その状況で取れる行動を組み合わせたものです。それぞれの組み合わせには、行動の良し悪しを数値で示す「Q値」が記録されています。Q値が高いほど、その状況でその行動を取ることが良い結果につながることを意味します。
エージェントは、まず自分が置かれている状況を認識します。そして、Q表を見て、その状況でどの行動を取れば良いかを判断します。Q値が最も高い行動を選ぶことが基本ですが、常に最高の値だけを選ぶのではなく、時にはランダムに行動を選び、新たな可能性を探ることもあります。行動を実行すると、環境から結果が返ってきます。これは、例えばゲームで得点を得る、迷路でゴールに近づくといったものです。この結果を「報酬」と呼びます。報酬が良いものだった場合、その行動につながったQ値は高く評価されます。逆に、報酬が悪ければQ値は低く評価されます。
Q値の更新は、現在の報酬だけでなく、将来得られるであろう報酬も考慮に入れて行われます。つまり、今の行動がすぐに高い報酬につながらなくても、その行動によって良い状況に移ることができれば、最終的にはより高い報酬を得られる可能性があります。この将来の報酬を見積もるために、次の状況で得られるであろう最大のQ値もQ値の更新に利用されます。このように、現在の報酬と将来の報酬の両方を考慮しながら、Q表の値を少しずつ修正していくことで、エージェントは最適な行動戦略を学習していきます。この学習を繰り返すことで、エージェントはどの状況でどの行動を取れば最も良い結果を得られるかを学習し、最終的には最適な行動を取ることができるようになります。
| 概念 | 説明 |
|---|---|
| Q学習 | 試行錯誤を通じて、より良い結果につながる行動を学習する仕組み |
| Q表 | 状態と行動の組み合わせ、およびそれぞれのQ値を記録した表 |
| 状態 | エージェントが置かれている状況 |
| 行動 | エージェントがとれる行動 |
| Q値 | 状態と行動の組み合わせにおける行動の良し悪しを示す数値。高いほど良い |
| 報酬 | 行動の結果として環境から得られるもの |
| Q値の更新 | 現在の報酬と将来の報酬(次の状態での最大のQ値)を考慮して行われる |
Qテーブルの役割

Q学習は、試行錯誤を通じて学習を進める強化学習の一種です。この学習の中核を担うのがQテーブルです。Qテーブルは、まるで学習者の頭脳のように、どの行動をとるべきかを判断するための情報を蓄えています。
このテーブルは、縦と横にそれぞれ状態と行動を並べた表のような構造をしています。そして、テーブルの各マス目にはQ値と呼ばれる数値が書き込まれています。Q値は、特定の状態において、ある行動をとった場合に、将来どれだけの報酬が得られるかを予測した値です。
学習の初期段階では、Qテーブルにはランダムな値が設定されています。これは、学習者がまだ何も知らない状態を表しています。学習者は、様々な行動を試してみて、その結果得られた報酬をもとにQ値を更新していきます。うまくいった行動のQ値は高く、そうでない行動のQ値は低く更新されます。
学習が進むにつれて、Q値はより正確な予測値に近づいていきます。まるで学習者が経験を積んで賢くなっていくように、Qテーブルの内容も洗練されていきます。最終的には、各状態において最も高いQ値を持つ行動が、その状態でとるべき最適な行動として選ばれます。
Qテーブルの大きさは、状態の数と行動の数で決まります。例えば、状態が10種類、行動が5種類ある場合、テーブルは10行5列の50マスになります。状態や行動の種類が多くなればなるほど、テーブルも大きくなり、学習に必要な時間も増えます。これは、より複雑な状況に対応するためには、より多くの情報を処理する必要があるためです。しかし、Qテーブルは学習者の知識を蓄積し、効率的な学習を実現するための重要な役割を果たしているのです。
| 項目 | 説明 |
|---|---|
| Q学習 | 試行錯誤を通じて学習を進める強化学習の一種 |
| Qテーブル | 状態と行動を縦横に並べ、各マスにQ値を格納した表。学習者の頭脳の役割を果たす。 |
| 状態 | Qテーブルの行を構成する要素。 |
| 行動 | Qテーブルの列を構成する要素。 |
| Q値 | 特定の状態である行動をとった場合に、将来どれだけの報酬が得られるかを予測した値。 |
| 学習初期段階 | Qテーブルにはランダムな値が設定されている。 |
| 学習プロセス | 様々な行動を試してみて、得られた報酬をもとにQ値を更新。うまくいった行動のQ値は高く、そうでない行動のQ値は低く更新される。 |
| 学習が進むにつれて | Q値はより正確な予測値に近づく。 |
| 最適な行動 | 各状態において最も高いQ値を持つ行動。 |
| Qテーブルの大きさ | 状態の数 × 行動の数。状態や行動の種類が多くなるとテーブルも大きくなり、学習に必要な時間も増える。 |
学習の進め方

学習は、まさに試行錯誤の繰り返しです。まるで迷路の中で出口を探すように、様々な行動を試すことで、どの行動がどのくらいの良い結果をもたらすのかを少しずつ学んでいきます。最初のうちは、右に行くか左に行くか、上に行くか下に行くか、全くの手探りで、偶然良い結果にたどり着くこともあれば、悪い結果に陥ることもあります。しかし、この試行錯誤こそが学習の肝となります。
行動を起こすたびに、その結果として得られる良い結果、つまり報酬が記録されます。そして、この報酬の記録をもとに、どの行動が良い結果につながりやすいのかを学習していきます。最初は行き当たりばったりだった行動も、経験を積むにつれて、だんだんと良い結果につながる行動を選ぶようになっていきます。まるで迷路の地図を少しずつ完成させていくように、最適な行動を見つけていくのです。
この学習の過程で、将来の報酬をどのくらい重視するかを決める要素が「割引率」です。例えば、目の前の小さな報酬と、将来得られる大きな報酬があった場合、どちらを優先するでしょうか?割引率が大きい場合、将来の大きな報酬を重視して行動します。逆に割引率が小さい場合は、目の前の小さな報酬を優先します。
もう一つ重要な要素が「学習率」です。これは、新しい情報をどのくらい速く学ぶかを示すものです。学習率が高いと、新しい情報をすぐに吸収しますが、過去の経験を忘れてしまう可能性があります。逆に学習率が低いと、新しい情報をゆっくりと学ぶため、過去の経験をしっかりと覚えていますが、学習に時間がかかります。
割引率と学習率は、学習の効率に大きく影響します。状況に応じて適切な値を設定することで、より効率的に学習を進めることができます。
| 要素 | 説明 | 値が高い場合 | 値が低い場合 |
|---|---|---|---|
| 割引率 | 将来の報酬をどのくらい重視するか | 将来の大きな報酬を重視 | 目の前の小さな報酬を重視 |
| 学習率 | 新しい情報をどのくらい速く学ぶか | 新しい情報をすぐに吸収するが、過去の経験を忘れやすい | 新しい情報をゆっくり学ぶため、過去の経験を覚えているが、学習に時間がかかる |
Q学習の応用例

Q学習は、様々な分野で応用され、成果を上げています。代表的な例として、ゲームにおける人工知能の開発が挙げられます。ゲームのプログラムの中に、Q学習を取り入れることで、コンピューターが操作するキャラクターに高度な行動を学習させることができます。具体的には、ゲームのルールや目標達成を報酬として設定することで、キャラクターは試行錯誤を通じて、より多くの報酬を得られる行動を学習します。この仕組みにより、まるで人間が操作しているかのような、自然で高度なプレイを実現することが可能になります。
また、機械の制御の分野でも、Q学習は大きな力を発揮します。機械に様々な動作を学習させることで、複雑な作業を自動化することができるのです。例えば、工場における製品の組み立て作業や、倉庫における商品の仕分け作業などを、機械に学習させることができます。従来、人間が行っていたこれらの作業を機械が代行することで、作業効率の向上や人件費の削減といった効果が期待できます。
さらに、Q学習は、医療や金融といった、一見すると人工知能とは無縁に思える分野でも、応用が進められています。医療分野では、患者の症状や検査データに基づいて、最適な治療方針を決定するためにQ学習が活用される可能性があります。また、金融分野では、市場の動向を予測し、より効果的な投資戦略を立てるためにQ学習が利用できる可能性があります。このように、Q学習は、その柔軟性と学習能力の高さを活かして、様々な問題解決に役立つ可能性を秘めており、今後ますます幅広い分野での応用が期待されています。
| 分野 | 応用例 | 効果 |
|---|---|---|
| ゲーム | 人工知能によるキャラクター制御 | 高度なプレイの実現 |
| 機械制御 | 工場の製品組み立て、倉庫の商品の仕分け | 作業効率向上、人件費削減 |
| 医療 | 最適な治療方針の決定支援 | – |
| 金融 | 効果的な投資戦略の立案支援 | – |
Q学習の課題

学習のやり方の一つであるQ学習は、とても役に立つ方法ですが、いくつかの難しい点もあります。まず、取り扱う状態の数がとても多い場合、Qテーブルと呼ばれる、状態と行動の組み合わせに対する価値を記録する表が巨大になり、学習に時間がかかってしまうという問題があります。例えば、囲碁のようなゲームでは、盤面の配置一つ一つが状態にあたり、その数は天文学的になります。このような膨大な状態を全てQテーブルに記録するのは現実的ではありません。この問題を解決するために、関数近似と呼ばれる方法が使われます。これは、複雑なQテーブルの代わりに、数式を使って価値を表現する方法です。関数近似を使うことで、Qテーブルをコンパクトに表現し、学習を効率化することができます。
もう一つの難しい点は、探索と活用のバランスです。探索とは、まだ試したことのない行動を試すことです。新しい行動を試すことで、より良い行動が見つかる可能性があります。一方、活用とは、これまでの学習で最も良いとされている行動を選ぶことです。活用によって、現在の知識で最良の結果を得ることができます。探索ばかりしていると、良い行動が見つかるまでに時間がかかってしまいます。逆に、活用ばかりしていると、今知っている範囲で最良の行動しか選ばず、本当に一番良い行動を見逃してしまう可能性があります。例えば、いつも同じ店でお昼ご飯を食べていると、その店より美味しい店があることに気づかないかもしれません。新しい店を試してみることで、もっと美味しいお昼ご飯が見つかるかもしれません。このように、探索と活用のバランスをうまくとることが、Q学習を成功させるためにはとても重要です。色々な方法でこのバランスを調整する研究が行われています。最適なバランスは、扱う問題によって異なり、常に最適なバランスを見つけることは難しい問題です。
| 項目 | 説明 |
|---|---|
| Q学習の課題 | 状態数の爆発、探索と活用のバランス |
| 状態数の爆発 | 状態が多すぎるとQテーブルが巨大になり学習に時間がかかる。例:囲碁 |
| 状態数の爆発への対策 | 関数近似:数式で価値を表現し、Qテーブルをコンパクトにする。 |
| 探索と活用のバランス | 探索:新しい行動を試す、活用:最良の行動を選ぶ |
| 探索のメリット・デメリット | メリット:より良い行動が見つかる可能性、デメリット:良い行動が見つかるまで時間がかかる |
| 活用のメリット・デメリット | メリット:現在の知識で最良の結果、デメリット:本当に一番良い行動を見逃す可能性 |
| 探索と活用のバランスの例 | いつも同じ店でお昼ご飯を食べる(活用) vs 新しい店を試す(探索) |
| 探索と活用のバランスの最適化 | 扱う問題によって異なり、常に最適なバランスを見つけることは難しい |