
Q学習:試行錯誤で学ぶAI

AIを知りたい
先生、「Q学習」ってよく聞くんですけど、具体的にどんなものなんですか?

AIエンジニア
Q学習は、試行錯誤を通じて学習する「強化学習」という分野の手法の一つだよ。 例えるなら、迷路の中でゴールを目指すロボットを想像してみて。ロボットは、各地点でどの方向に進むのが良いかを学習していくんだ。
AIを知りたい
なるほど。ロボットがどんな風に学習していくんですか?
AIエンジニア
ロボットは、それぞれの場所で、上下左右に進むといった行動に対して、どのくらい良い結果が得られるかを数値で記録する表を持っているんだ。この表を「Qテーブル」と呼ぶ。ロボットは行動の結果、報酬をもらったり、罰を受けたりする。そして、その結果に基づいて、Qテーブルの値を更新していくことで、最適な行動を学習していくんだよ。
Q学習とは。
人工知能に関わる言葉である「キュー学習」について説明します。キュー学習は、試行錯誤を通じて学習する強化学習という手法の一つです。キュー学習では、それぞれの状況における行動の価値を数値で表した「キュー値」を記録した表(キューテーブル)を使います。そして、行動の結果として得られた報酬と、将来の報酬をどのくらい重視するかを示す割引率などを用いて計算される「TD誤差」を小さくするように学習を進め、表の中のキュー値を更新していきます。
はじめに

人間が自転車に乗れるようになるまでには、何度も転びながらバランスの取り方を学ぶ必要があります。最初はうまくいかないことも、繰り返すうちにコツをつかみ、やがてスムーズに走れるようになります。このように、試行錯誤を通して学習することは、人間にとって自然な行為です。
人工知能の世界でも、同じように機械に試行錯誤をさせながら学習させる方法が注目を集めています。この学習方法の一つが、Q学習と呼ばれる手法です。Q学習は、強化学習と呼ばれる分野に属しています。強化学習とは、機械が周囲の環境と相互作用しながら、報酬を最大化する行動を学習する枠組みです。自転車の例で言えば、転ばずに長く走ることが報酬となり、その報酬を最大化するように、バランスの取り方やペダルの漕ぎ方を学習していくイメージです。
Q学習では、行動の価値を数値化して、その価値を基に行動を選択します。価値が高い行動ほど、選択される確率が高くなります。自転車の例で言えば、「ペダルを速く漕ぐ」という行動と「ハンドルを左右に大きく振る」という行動があるとします。転ばずに長く走れた場合に報酬が得られるとすると、「ペダルを速く漕ぐ」行動の価値は高く、「ハンドルを左右に大きく振る」行動の価値は低くなります。このように、試行錯誤を通して行動の価値を更新していくことで、機械は最適な行動を学習していきます。
Q学習は、様々な分野で応用されています。例えば、ロボットの制御、ゲームの攻略、商品の推奨など、私たちの生活にも深く関わっています。ロボットであれば、目的の場所に移動するために最適な経路を学習したり、ゲームであれば、高い得点を得るための戦略を学習したりすることができます。また、商品の推奨では、顧客の過去の購買履歴に基づいて、最適な商品を推薦することができます。このように、Q学習は様々な問題を解決するための強力な道具となっています。
| 学習方法 | 概要 | 例 |
|---|---|---|
| 人間の学習 | 試行錯誤を通して学習 (例: 自転車) | 転びながらバランスの取り方を学ぶ |
| 強化学習 (Q学習) | 機械が環境と相互作用し、報酬を最大化する行動を学習 | 転ばずに長く走る(報酬) → バランス/ペダルの漕ぎ方を学習 |
| Q学習の仕組み | 行動の価値を数値化し、価値に基づいて行動を選択 試行錯誤を通して行動の価値を更新 |
「ペダルを速く漕ぐ」(高価値) vs 「ハンドルを左右に大きく振る」(低価値) |
| Q学習の応用 | ロボット制御、ゲーム攻略、商品推奨など | ロボット: 最適な経路学習 ゲーム: 高得点戦略学習 商品推奨: 顧客履歴に基づく最適な商品推薦 |
Q学習の仕組み

「Q学習」は、機械に学習させるための方法のひとつです。まるで迷路を解くように、機械自身が様々な行動を試して、より良い結果へと繋がる行動を覚えていく仕組みです。この学習の中心となるのが「Qテーブル」と呼ばれる表です。この表には、機械が置かれる可能性のあるあらゆる状況と、その状況で取れるあらゆる行動の組み合わせが記録されています。そして、それぞれの組み合わせに対して「Q値」と呼ばれる数値が対応付けられています。このQ値こそが、Q学習の鍵となります。
Q値は、ある状況で特定の行動を取ったときに、将来どれだけの「ご褒美」をもらえるかを予測した数値です。例えば、ロボット掃除機を例に考えてみましょう。部屋の隅という状況で、前進する行動を取った場合、ご褒美としてゴミを掃除できるかもしれません。しかし、壁にぶつかる行動を取った場合、ご褒美は得られず、バッテリーの消費という損失が発生します。Q学習では、ロボット掃除機のような学習主体(「エージェント」と呼ばれます)が、実際に部屋の中を動き回りながら試行錯誤を繰り返します。エージェントは、現在の自分の状況を認識し、Qテーブルを参照して行動を選択します。選んだ行動を実行すると、環境からご褒美(または損失)が与えられ、次の状況へと移ります。
この一連の流れの中で、エージェントはQテーブルの値を更新していきます。更新の際には、実際に得られたご褒美と、次の状況で取れる最良の行動のQ値を参考にします。つまり、目先の成果だけでなく、将来得られるであろうご褒美まで見越して学習を進めるのです。このように、将来のご褒美を予測しながらQテーブルを更新していくことで、エージェントはどの状況でどの行動を取るのが最適なのかを徐々に学習し、最終的には迷路を解くように、どんな状況でも最も効率的に目的を達成できる行動戦略を身に付けるのです。
| 用語 | 説明 | 例(ロボット掃除機) |
|---|---|---|
| Q学習 | 機械学習の一種。試行錯誤を通じて、最適な行動を学習する。 | ロボット掃除機が部屋を掃除しながら、効率的な掃除方法を学習する。 |
| Qテーブル | 状況と行動の組み合わせ、および対応するQ値を記録した表。 | 部屋の隅(状況)と前進(行動)の組み合わせに対するQ値 |
| Q値 | ある状況で特定の行動を取った時の、将来得られるご褒美の予測値。 | 部屋の隅で前進した場合のQ値(ゴミを掃除できる可能性が高い) |
| 状況 | エージェントが置かれている状態。 | 部屋の隅 |
| 行動 | エージェントが取る行動。 | 前進、後退、回転など |
| ご褒美/損失 | 行動の結果として得られる報酬または罰。 | ゴミを掃除できた(ご褒美)、壁にぶつかった(損失) |
| エージェント | 学習を行う主体。 | ロボット掃除機 |
| 学習の流れ | 状況把握→Qテーブル参照→行動選択→ご褒美/損失→次の状況→Q値更新 | 部屋の隅→Qテーブル参照→前進→ゴミ取得→部屋中央→Q値更新 |
Qテーブルの役割

Q学習という機械学習の手法において、Qテーブルは大切な役割を担っています。例えるなら、過去の経験から得られた智慧を蓄える宝箱のようなものです。この宝箱には、様々な場面に出くわした時、どのような行動をとれば最も良い結果に繋がるのかという情報が詰まっています。
具体的には、QテーブルにはQ値と呼ばれる数値が記録されています。Q値は、ある状況における特定の行動の価値を表すものです。例えば、迷路で行き止まりに突き当たった時、「右に曲がる」という行動のQ値が低ければ、それはあまり良い選択ではないことを示しています。反対に、「左に曲がる」という行動のQ値が高ければ、左に曲がることが最良の選択である可能性が高いことを意味します。
Qテーブルは、あらゆる状況と行動の組み合わせに対応するQ値を保存しています。そのため、エージェント(学習を行う主体)は、現在の状況に応じて、Qテーブルを参照することで、どの行動が最も高い報酬、つまり良い結果に結びつくのかを判断できます。まるで、宝箱から最適な道具を取り出すように、Qテーブルから最適な行動を選択するのです。
Qテーブルの大きさは、取り扱う状況の数と行動の数によって決まります。状況や行動の種類が多くなればなるほど、Qテーブルも巨大化します。もし、迷路が複雑になり、分岐点の数が増えれば、Qテーブルに記録するQ値の数も増えることになります。
このように、複雑な問題を扱う際には、膨大な量の情報を管理する必要が生じるため、Qテーブルの管理が課題となります。しかし、QテーブルはQ学習の核心となる重要な要素であり、最適な行動選択を実現するための鍵を握っているのです。
| 項目 | 説明 |
|---|---|
| Qテーブル | 過去の経験から得られた智慧を蓄える宝箱。様々な場面での最適な行動を記録 |
| Q値 | ある状況における特定の行動の価値を表す数値 |
| Q値の例 | 迷路で行き止まりに突き当たった時、「右に曲がる」行動のQ値が低い → あまり良い選択ではない |
| Qテーブルの役割 | エージェントが現在の状況に応じて、どの行動が最も高い報酬に結びつくかを判断するための参照先 |
| Qテーブルのサイズ | 取り扱う状況の数と行動の数によって決まる。状況や行動の種類が多いほど巨大化 |
| Qテーブルの課題 | 複雑な問題では膨大な量の情報を管理する必要があり、Qテーブルの管理が課題となる |
| Qテーブルの重要性 | Q学習の核心となる重要な要素であり、最適な行動選択を実現するための鍵 |
報酬と割引率

学習する機械、いわゆる人工知能を作る方法の一つにQ学習というものがあります。このQ学習では、報酬と割引率という二つの考え方がとても大切です。
まず、報酬について説明します。人工知能は、様々な行動をとることができます。ちょうど、迷路の中で色々な道を選んで進んでいくようなものです。そして、とった行動の良し悪しを評価するために、報酬を与えます。例えば、目指すゴールに近づく行動をとった場合には、高い報酬を与えます。逆に、ゴールから遠ざかる行動をとった場合には、低い報酬、もしくは罰則としてマイナスの報酬を与えます。このように、報酬によって人工知能は、どの行動が良いのかを学習していくのです。
次に、割引率について説明します。人工知能は、今すぐ得られる報酬だけでなく、将来得られる報酬も考慮して行動を選択します。しかし、将来得られる報酬は、今すぐ得られる報酬ほど確実ではありません。そこで、将来の報酬をどの程度重視するかを調整するために、割引率という値を使います。割引率は0から1の間の値で、この値が小さいほど、将来の報酬を軽視し、目先の報酬を重視するようになります。例えば、割引率が0に近い場合は、「今すぐに少しでも報酬がもらえる行動を優先しよう」と考えます。逆に、割引率が1に近い場合は、将来得られる大きな報酬を期待して、「多少時間がかかっても、最終的に大きな報酬が得られる行動を優先しよう」と考えます。
報酬と割引率の設定は、人工知能の学習効率や最終的な性能に大きな影響を与えます。もし、報酬の設定が適切でないと、人工知能は間違った行動を学習してしまいます。また、割引率の設定が不適切な場合、目先の利益にとらわれて最終的な目標を達成できない、あるいは、いつまでも最適な行動を見つけられないといった問題が起こる可能性があります。そのため、人工知能がうまく学習するように、報酬と割引率を適切に設定することが非常に重要です。
| 概念 | 説明 | 値/設定 | 影響 |
|---|---|---|---|
| 報酬 | 行動の良し悪しを評価するための指標。 | ゴールに近づく行動:高い報酬 ゴールから遠ざかる行動:低い報酬/罰則 |
AIは報酬によって良い行動を学習する。適切な設定が重要。 |
| 割引率 | 将来の報酬をどの程度重視するかを調整する値。 | 0 ~ 1 小さい値:将来の報酬を軽視 大きい値:将来の報酬を重視 |
AIの学習効率や最終性能に影響。不適切な設定は、目先の利益の追求や最適行動の発見困難につながる可能性あり。 |
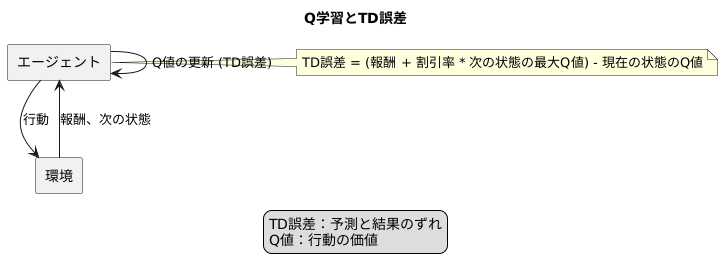
学習の更新とTD誤差

学習とは、経験から学ぶことです。機械学習においてもこの考え方は同じで、試行錯誤を通じて知識を蓄え、より良い結果を導き出すことを目指します。Q学習と呼ばれる手法では、行動の価値を数値で表す「Q値」を用いて学習を進めます。このQ値を更新するために重要なのが「TD誤差」です。
TD誤差とは、現在の予測と実際の結果とのずれを表す指標です。例えば、ある行動をとった結果、思ったよりも良い結果が得られたとします。この場合、TD誤差は正の値となり、その行動のQ値は増加します。逆に、思ったよりも悪い結果が得られた場合は、TD誤差は負の値となり、Q値は減少します。
TD誤差は、現在の状態における予測Q値と、実際に行動を実行して得られた報酬と次の状態の最大Q値を組み合わせて計算されます。具体的には、次の状態での最大のQ値に割引率を掛け、それに得られた報酬を足した値から、現在の状態のQ値を引くことで計算します。この計算により、将来的な報酬まで考慮に入れた学習が可能になります。
Q学習では、エージェント(学習を行う主体)が環境と繰り返しやり取りをする中で、TD誤差を用いてQ値を更新していきます。この更新は、TD誤差が小さくなる、つまり予測と結果のずれが小さくなる方向に進みます。結果として、エージェントはより正確なQ値を学習し、最適な行動戦略を身につけていくのです。
このように、Q学習におけるTD誤差は、エージェントが環境に適応し、学習を進める上で欠かせない要素と言えます。あたかも人間が経験から学ぶように、機械も試行錯誤を通じて成長していく、その過程を支えているのがTD誤差なのです。
応用事例

Q学習は、機械学習の中でも強化学習と呼ばれる分野の一種であり、様々な場面で活用されています。
まず、ロボットの制御の分野では、ロボットアームをどのように動かすか、あるいは移動ロボットがどのように目的地まで進むかといった課題を解決するためにQ学習が用いられています。従来の方法では、あらかじめプログラミングされた通りにロボットが動くだけでしたが、Q学習を用いることで、試行錯誤を通じて最適な動作をロボット自身が学習できるようになりました。例えば、工場の組み立てラインで部品を取り付けるロボットアームは、より速く正確に作業を行う方法を自ら学習し、生産性の向上に貢献しています。また、倉庫内を移動して荷物を運ぶロボットは、障害物を避けながら最短経路を見つけることで、作業効率を向上させています。
次に、ゲームの人工知能開発の分野でもQ学習は活躍しています。囲碁や将棋といった伝統的なゲームから、複雑なルールを持つ最新のテレビゲームまで、様々なゲームで人工知能を賢くするためにQ学習が利用されています。Q学習によって学習した人工知能は、もはや人間に勝るほどの強さを身につけている例も少なくありません。ゲームの人工知能は、まるで人間のように戦略を立ててゲームを進めることができ、プレイヤーに更なる楽しさを提供しています。
さらに、インターネット上のサービスの分野でもQ学習は応用されています。例えば、商品の推薦システムでは、利用者の過去の購買履歴や閲覧履歴を学習することで、利用者が気に入りそうな商品を予測して表示します。また、広告の配信を最適化するためにQ学習が用いられることもあります。利用者の興味関心に基づいて効果的な広告を表示することで、広告の効果を高めることができます。このようにQ学習は、私たちの日常生活をより便利で快適なものにするために役立っています。
このようにQ学習は、様々な分野で活用され、私たちの生活を豊かにする技術です。今後、更なる発展と応用が期待されます。
| 分野 | 活用例 | 効果 |
|---|---|---|
| ロボットの制御 | ロボットアームの動作制御、移動ロボットの経路計画 | 生産性向上、作業効率向上 |
| ゲームAI開発 | 囲碁、将棋、テレビゲーム | 人間に匹敵するAI、ゲームの面白さ向上 |
| インターネットサービス | 商品推薦システム、広告配信最適化 | 利便性向上、広告効果向上 |