
過学習を防ぐL2正則化

AIを知りたい
先生、「L2正則化」ってよく聞くんですけど、何のことか教えてください。

AIエンジニア
簡単に言うと、L2正則化は機械学習モデルが複雑になりすぎないように調整する方法の一つだよ。 複雑になりすぎると、学習に使ったデータに過剰に適応してしまい、新しいデータではうまく予測できない「過学習」という状態になるんだ。L2正則化は、それを防ぐのに役立つんだよ。
AIを知りたい
複雑になりすぎるのを防ぐ、というのは具体的にどういうことですか?
AIエンジニア
モデルを作る際には、たくさんの部品を調整して、データに合うようにしていくんだけど、L2正則化では、部品の値が大きくなりすぎないようにするんだ。値が大きいと、モデルが複雑になりすぎる傾向があるからね。そうすることで、過学習を防ぎ、新しいデータに対しても精度良く対応できるようになるんだよ。
L2正則化とは。
人工知能の分野でよく使われる「L2正則化」について説明します。L2正則化とは、学習モデルが複雑になりすぎて、学習データだけに特化してしまい、新しいデータにうまく対応できなくなることを防ぐための工夫です。通常、モデルの学習では、損失関数と呼ばれる、予測と実際のデータとのずれを表す値と、正則化項と呼ばれるモデルの複雑さを表す値の和を最小にするように調整します。L2正則化では、この正則化項が、モデルのパラメータ(重み)の2乗で表されます。似たような手法にL1正則化がありますが、L2正則化はL1正則化と比べて、モデルの精度を高める効果が強い傾向にあります。
過学習とは

機械学習の目的は、未知のデータに対しても正確な予測ができるモデルを作ることです。しかし、時に学習に用いたデータに過度に合わせてしまい、未知のデータへの対応力が乏しくなることがあります。これを過学習と呼びます。
例えるなら、試験対策で過去問ばかりを解き、出題傾向を丸暗記するようなものです。過去問では満点を取れても、出題形式が変わると全く解けなくなる、まさに過学習の状態と言えるでしょう。
過学習は、複雑すぎるモデルを使ったり、学習データが少ない時に起こりやすくなります。複雑なモデルは、学習データの細かな特徴までも捉えようとするため、いわば過去問の些細な部分にまでこだわりすぎる状態です。結果として、学習データには完璧に合致するモデルができますが、新しいデータへの対応力は弱くなります。
また、学習データが少ない場合は、限られた情報から全体像を推測しなければなりません。これは、少ない過去問から出題範囲全体を予測するようなものです。当然、推測が外れる可能性は高く、誤った規則を学習してしまう、つまり間違った勉強をしてしまうリスクが高まります。
過学習は、モデルの汎化性能、すなわち未知のデータへの対応能力を低下させます。これは、様々な問題に対応できる応用力を失うことと同じです。機械学習では、過学習を避けることが非常に重要であり、様々な手法を用いてこの問題への対策を施します。

正則化による過学習対策

機械学習モデルを訓練する際、学習データに過度に適合してしまう「過学習」という問題が生じることがあります。過学習とは、訓練データに対する精度は高いものの、新たなデータに対する予測性能が低い状態を指します。この問題に対処する有効な手法の一つが「正則化」です。
正則化は、モデルの複雑さを抑制することで過学習を防ぎ、未知のデータに対しても高い予測精度を実現することを目指します。具体的には、モデルが持つ多数の調整つまみ、つまりパラメータの値を小さく保つことで、モデルの表現力を制限し、過度に複雑な形にならないようにします。例えるなら、複雑に入り組んだ曲線を描くのではなく、緩やかな曲線を描くように仕向けるイメージです。
では、どのようにパラメータの値を小さく保つのでしょうか。それは、モデルの学習において重要な役割を果たす「損失関数」に「正則化項」と呼ばれるペナルティを追加することで実現されます。損失関数は、モデルの予測値と実際の値とのずれの大きさを測る指標であり、モデルの学習過程ではこの損失関数を最小化することを目指します。ここに、パラメータの大きさに関するペナルティである正則化項を加えることで、パラメータの値が大きくなるとペナルティも大きくなるようにします。
つまり、正則化項を加えた損失関数を最小化しようとすると、モデルは予測精度を高く保ちつつ、パラメータの値を小さく抑えるという二つの目標を同時に達成するように学習されます。これにより、過学習を防ぎ、未知のデータに対しても安定した予測性能を発揮するモデルを構築することが可能になります。正則化は、様々な機械学習モデルに適用できる汎用的な手法であり、モデルの精度向上に大きく貢献します。
L2正則化とは

多くの機械学習手法では、学習を通して観測データによく合うモデルを作ることが目標です。しかし、あまりに観測データに特化しすぎたモデルは、未知のデータに対してうまく対応できなくなってしまうことがあります。これを過学習と呼びます。過学習を防ぐための手法の一つに正則化があり、様々な正則化手法の中でもよく用いられるのがL2正則化です。
L2正則化は、モデルのパラメータの大きさに制約を加えることで過学習を防ぎます。具体的には、損失関数(モデルの予測値と実際の値との間の誤差を表す関数)に、パラメータの二乗和を足し合わせた正則化項を加えます。この正則化項は、パラメータの値が大きいほど値が大きくなります。つまり、モデル学習の際に、損失関数の値だけでなく正則化項の値も小さくする必要が生じます。結果として、モデルは過度に複雑な形になることを避け、パラメータの値を全体的に小さくするように学習されます。
L2正則化を加えることで、モデルは入力データの変化に対して出力値が緩やかに変化する、滑らかなモデルになります。これは、入力データに含まれるわずかなノイズや外れ値の影響を受けにくくなることを意味します。たとえば、ある商品の価格を予測するモデルを考えてみましょう。L2正則化がない場合、モデルは過去のわずかな価格変動に過剰に反応し、極端な価格を予測してしまうかもしれません。しかし、L2正則化を適用することで、モデルは価格の大きな変動を抑制し、より安定した現実的な予測を行うことができるようになります。
このように、L2正則化はモデルの複雑さを抑え、滑らかな関数に近づけることで、未知のデータに対しても安定した予測性能を発揮するモデルを作るための強力な手法と言えるでしょう。このL2正則化は、リッジ回帰をはじめ様々な機械学習モデルで広く使われています。

L1正則化との違い

L1正則化とL2正則化、これらは機械学習モデルの複雑さを抑え、過学習を防ぐための手法、正則化においてよく用いられる二つの方法です。どちらもモデルのパラメータの大きさに制限を加えることで、未知のデータに対する予測精度を高めることを目指しています。しかし、その働き方には大きな違いがあります。
L1正則化は、モデルのパラメータの絶対値の合計を正則化項として用います。このため、L1正則化はいくつかのパラメータを完全にゼロにする性質を持っています。まるで不要な枝を剪定するように、重要度の低い特徴量に対応するパラメータをゼロにすることで、モデルを簡素化します。この性質は、「特徴選択」と呼ばれ、どの特徴量が予測に重要なのかを明らかにするのに役立ちます。結果として、解釈しやすい、つまり、人間にとって理解しやすいモデルを作ることができます。
一方、L2正則化は、パラメータの二乗の合計を正則化項として用います。L2正則化は、パラメータをゼロにするのではなく、全体的に小さな値に抑え込むように働きます。全ての枝を均等に短く刈り込むイメージです。そのため、L2正則化を用いたモデルは、多くのパラメータが小さな値を持つ、密度の高い、「デンスな」モデルになります。L1正則化のように特定のパラメータをゼロにするわけではないので、特徴選択には向きません。しかし、パラメータの値が極端に大きくならないため、モデルの安定性を高める効果があります。
このように、L1正則化とL2正則化はそれぞれ異なる特徴を持っています。どちらの手法が適しているかは、扱うデータの性質やモデルの目的によります。例えば、説明変数が非常に多く、その中から重要な変数を選び出したい場合はL1正則化が適しています。一方、全ての変数が予測に関連しており、モデルの安定性を高めたい場合はL2正則化が適しています。場合によっては、L1正則化とL2正則化を組み合わせた「Elastic Net」と呼ばれる手法も有効です。
| 項目 | L1正則化 | L2正則化 |
|---|---|---|
| 正則化項 | パラメータの絶対値の合計 | パラメータの二乗の合計 |
| パラメータへの影響 | いくつかのパラメータをゼロにする (特徴選択) | パラメータを全体的に小さな値に抑え込む |
| モデルの特徴 | スパースなモデル (解釈しやすい) | デンスなモデル (安定性が高い) |
| 適用例 | 重要な特徴量を選び出したい場合 | 全ての変数が予測に関連しており、モデルの安定性を高めたい場合 |
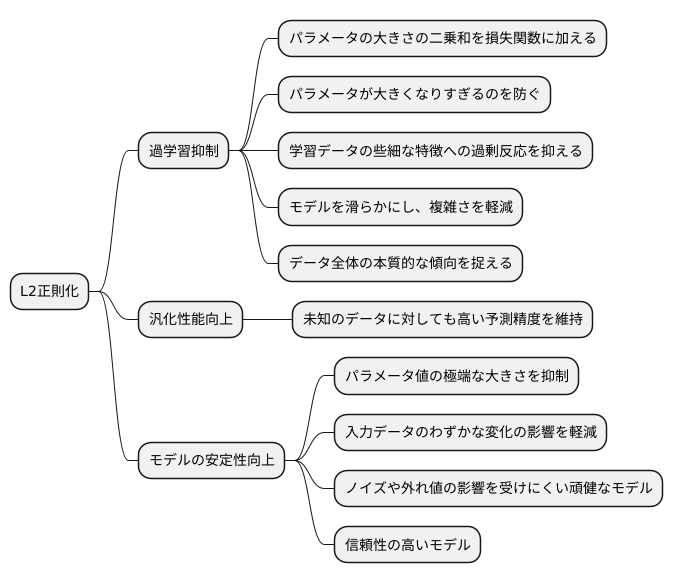
L2正則化の利点

多くの学習データから規則性を導き出し、未知のデータに対しても正確な予測を行うことが機械学習の目的です。しかし、学習データに過剰に適合してしまうと、未知のデータに対する予測精度が低下する「過学習」という問題が発生します。この過学習を防ぎ、未知のデータに対しても高い予測精度を維持する汎化性能を高めるための強力な手法の一つがL2正則化です。
L2正則化は、モデルのパラメータの大きさの二乗和を損失関数に加えることで、パラメータが過剰に大きくなることを抑制します。モデルのパラメータは、入力データから出力結果を導き出すための重み付けのような役割を果たします。これらの重みが大きすぎると、モデルは学習データの些細な特徴にまで過剰に反応し、複雑になりすぎてしまいます。L2正則化によってパラメータの大きさを抑えることで、モデルを滑らかにし、複雑さを軽減することで過学習を防ぎます。言い換えれば、学習データの個別の特徴よりも、データ全体に見られる本質的な傾向を捉えるようにモデルを誘導するのです。
L2正則化は、モデルの安定性向上にも寄与します。パラメータ値が極端に大きいと、入力データのわずかな変化が予測結果に大きな影響を与え、不安定な挙動を示す可能性があります。たとえば、データに含まれるごくわずかなノイズにも過剰反応し、本来とは異なる予測をしてしまうかもしれません。L2正則化はパラメータの大きさを抑制することで、このようなノイズや外れ値の影響を受けにくい、頑健なモデルを構築することを可能にします。つまり、多少のデータの変動にも安定した予測結果を出せるようになり、信頼性の高いモデルが得られるのです。
L2正則化の実装

多くの機械学習の道具には、あらかじめ過学習を防ぐ仕組みが組み込まれています。この仕組みは、モデルが複雑になりすぎるのを防ぎ、未知のデータに対してもきちんと働くようにするための工夫です。この仕組みの一つがL2正則化です。L2正則化は、モデルを学習させる際に、モデルの重みに対して「罰」を与えることで、重みが大きくなりすぎるのを防ぎます。この「罰」の強さを決めるのが、正則化の強さという値です。
たとえば、よく知られた「scikit-learn」という道具を使うと、この正則化の強さを簡単に調整できます。この道具には、正則化の強さを表す特別な値が用意されていて、これを変えるだけで、モデルの複雑さを調整できます。
正則化の強さを大きくすると、モデルの重みに対する「罰」が強くなります。そのため、重みは小さくなり、モデルは単純になります。これは、複雑すぎるモデルにありがちな、学習データだけに過剰に適応してしまう「過学習」を防ぐ効果があります。ただし、単純になりすぎると、学習データに対しても精度が悪くなることがあります。
逆に、正則化の強さを小さくすると、モデルの重みに対する「罰」が弱くなります。そのため、重みは大きくなりやすく、モデルは複雑になりやすいです。これは、学習データに対する精度は高くなる可能性がありますが、「過学習」のリスクを高めます。つまり、学習データにはよく合いますが、未知のデータにはうまく対応できないモデルになってしまうかもしれません。
この正則化の強さのちょうど良い値は、試行錯誤で見つける必要があります。たとえば、「交差検証」という方法がよく使われます。これは、学習データをいくつかのグループに分け、それぞれのグループでモデルを学習させ、他のグループでその精度を確かめることで、最適な正則化の強さを探す方法です。このようにして、学習データと未知のデータの両方でうまく働く、バランスの取れたモデルを作ることができます。
| 正則化の強さ | 重みへの影響 | モデルの複雑さ | 過学習への影響 | 学習データへの精度 | 未知データへの精度 |
|---|---|---|---|---|---|
| 大 | 小さくなる | 単純 | 抑制 | 低くなる可能性あり | 高くなる可能性あり |
| 小 | 大きくなる | 複雑 | 促進 | 高くなる可能性あり | 低くなる可能性あり |